
一、从全量到小批量——训练思路的转变

在传统的神经网络或线性回归训练中,我们通常定义一个代价函数:

其中 m 是训练样本总数。理想情况下,我们希望每次梯度下降都基于全部样本计算,以获得最精确的更新方向。
然而——当 m 达到上亿级(如图中写的 100,000,000)时,
每次完整遍历数据集(称为 Batch Gradient Descent)会变得极其缓慢,
并且需要巨大的显存和计算资源。
Mini-batch 的引入
为了解决这一问题,我们引入了 Mini-batch Gradient Descent。
其核心思想是:
每次从全部样本中随机抽取一个小批量 m′(例如 1000 个样本),
用它们近似整体梯度进行一次参数更新。
公式变为:

这种做法有两个好处:
加速训练 —— 每次更新只需计算一小部分数据,显著提升效率;
引入噪声 —— 随机采样带来轻微扰动,有助于跳出局部最优点。
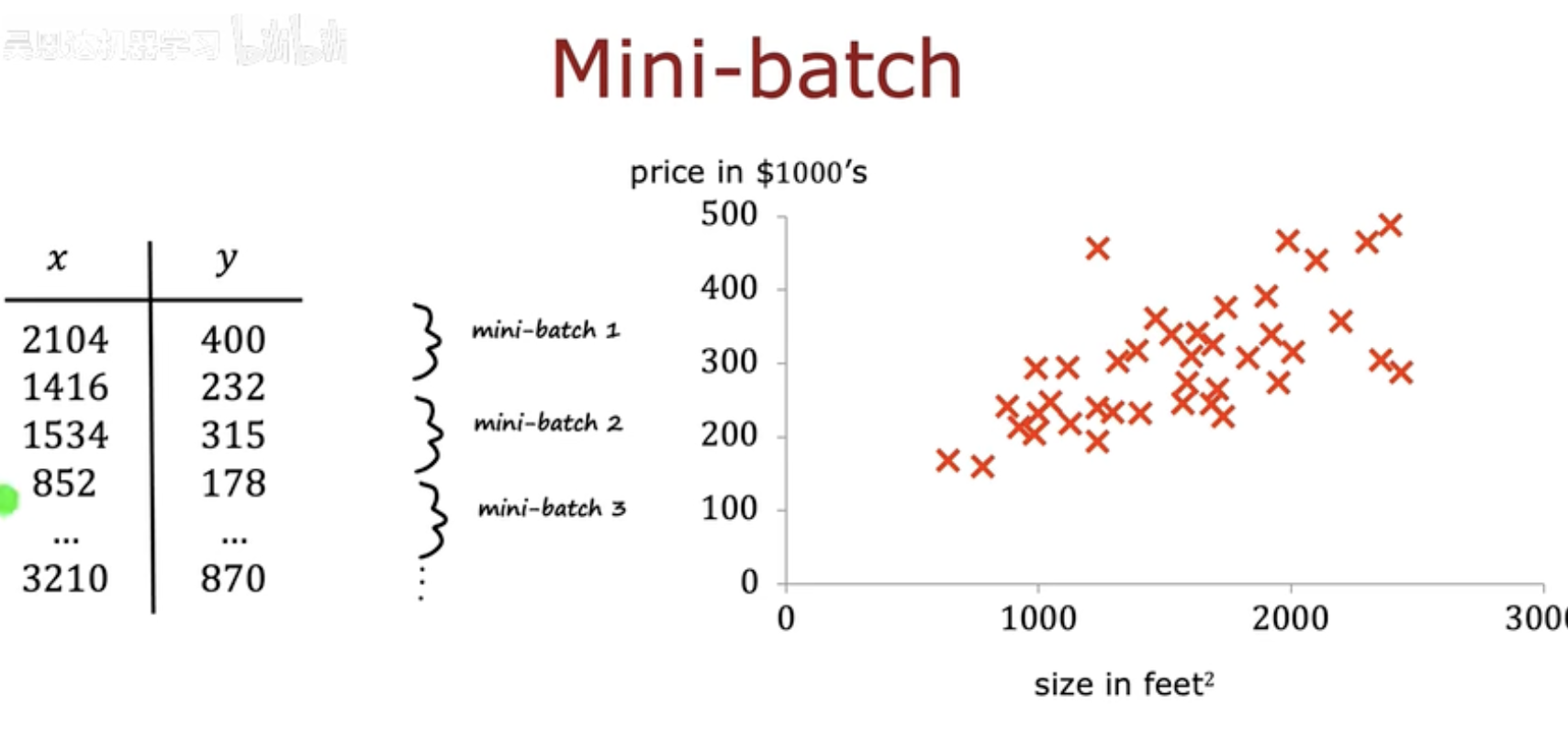
图中展示了一个房价预测例子(左表为数据集,右侧为分批过程),
将庞大的数据划分成多个 mini-batch。
这种方法让模型在更新时“看见”数据的不同局部分布,
从而提高泛化能力。
二、Mini-batch 的机制与效果
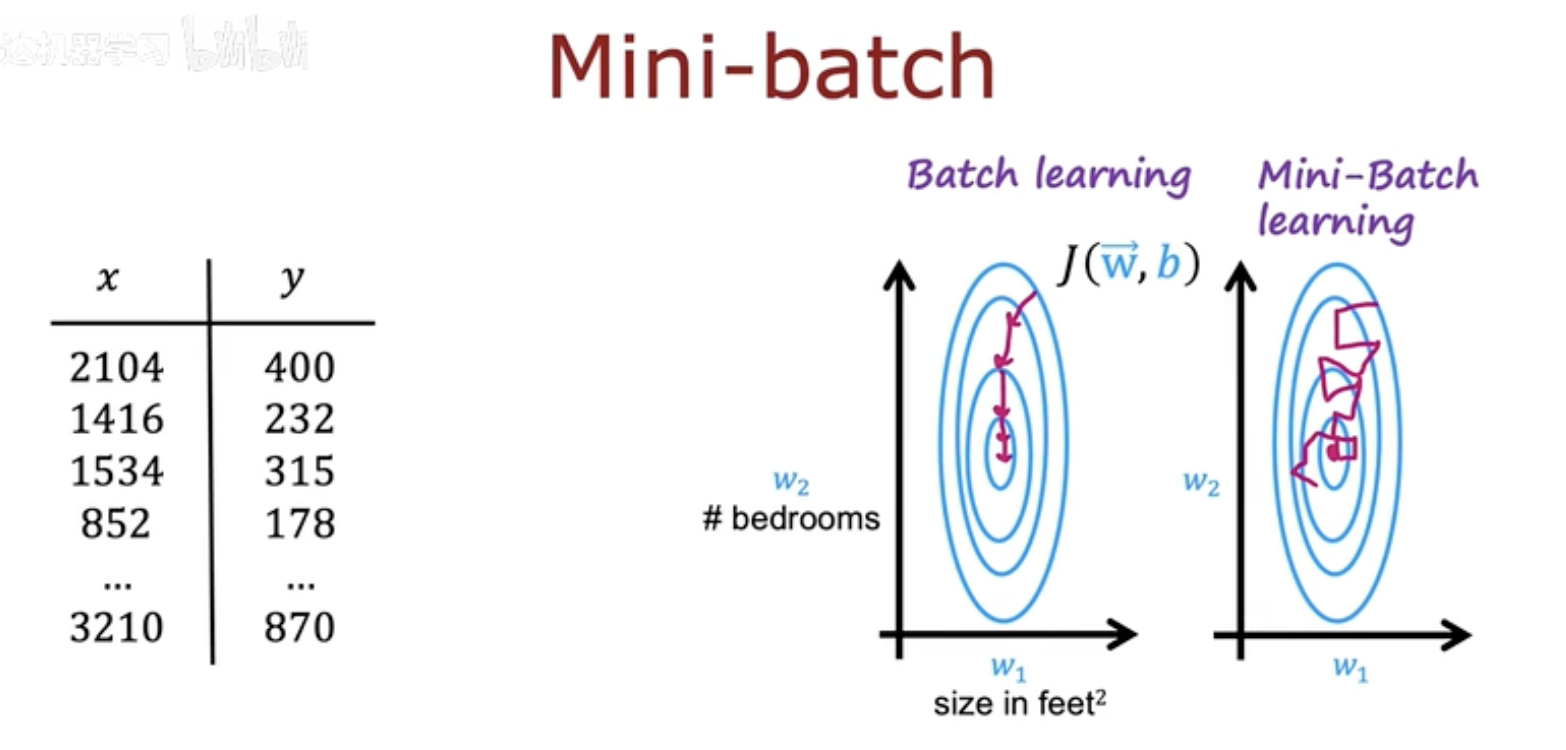
在梯度下降中,Batch Learning 与 Mini-batch Learning 的核心差异,
不仅体现在速度上,更关键的是参数更新路径的行为差异。
Batch Learning 的特征
在 Batch Learning(全量学习)中,
模型每次使用所有样本计算精确梯度,更新方向稳定、平滑。
在图中左侧的蓝色等高线图里,
每一步的更新(粉色箭头)都笔直地指向全局最优点。
但这种“稳定”是有代价的:
需要更长时间来完成一次更新;
每次更新成本极高,尤其是在大规模数据场景下。
Mini-batch Learning 的特征
而右侧的 Mini-batch Learning 则展示出另一种动态:
每个小批次的数据分布不同,因此每次梯度更新方向都会稍有偏差。
这使得更新路径呈现出“抖动式”前进的特征。
尽管更新方向不稳定,但这种随机性反而带来优势:
更快的收敛速度 —— 每次更新都利用部分样本,迭代频率高。
避免陷入局部最优 —— 轻微的扰动有助于模型跳出局部陷阱。
泛化更强 —— 不同 mini-batch 的多样性让模型学得更全面。
小结
Mini-batch 方法可以看作在“精度”与“速度”之间的折中。
它牺牲了一部分精确性,却换来了更高效、更稳定的整体训练过程。
这也解释了为何现代深度学习几乎都采用 mini-batch 训练。
三、Replay Buffer 与样本采样
在监督学习中,Mini-batch 来自静态数据集;
而在强化学习(Reinforcement Learning, RL)中,
智能体的训练样本是从与环境交互中不断产生的。
这带来一个新的挑战:
数据之间存在强相关性(temporal correlation),
连续采样的状态-动作对 (s,a,r,s’) 并非独立同分布(i.i.d.)。
Replay Buffer 的引入
为了解决这一问题,我们引入了 Replay Buffer(经验回放缓冲区)。
顾名思义,它是一个用来存储智能体最近交互经历的队列。
每次智能体与环境交互后,会将一个四元组

存入缓冲区中。
当缓冲区填满(例如 10,000 条数据)时,
旧数据会被新数据覆盖,以保证内容持续更新。
Mini-batch 采样机制
训练阶段中,智能体不会顺序使用这些样本,
而是随机采样出一个 mini-batch(例如 1000 条),
作为当前神经网络的训练数据。
每条样本都提供:
当前状态 s
执行动作 a
奖励 R(s)
下一状态 s′
模型利用这些样本更新 Q 网络参数,使得:
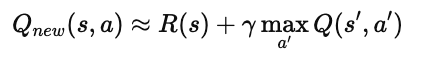
这种“打乱时间顺序的采样”能有效减少样本间的相关性,
让学习过程更加稳定,也更接近独立分布假设。
四、Replay Buffer 与样本采样

在前几节中,我们提到 Q 网络的参数更新:
每一轮训练后,模型会通过

来替换旧的 Q 值函数。
这种方式称为 Hard Update(硬更新)。
虽然简单直接,但在实际强化学习中会引发不稳定问题:
新旧网络差距过大,导致学习震荡;
Q 值在短时间内波动剧烈,训练过程难以收敛。
Soft Update 的提出
为了解决这种不稳定性,研究者提出了 Soft Update(软更新)。
它并不是一次性完全替换参数,而是通过一个平滑系数 τ(通常很小,如 0.01)
进行部分更新:

这种方式使得新旧网络之间逐步过渡,
让学习更加平稳、连续。
对比理解
结合 Mini-batch 的效果
当 Soft Update 与 Mini-batch 联合使用时,
强化学习的更新过程会变得更加平滑和鲁棒:
Mini-batch 打散了样本之间的时间相关性;
Soft Update 避免了网络参数剧烈跳变。
两者共同作用,使得智能体在面对复杂环境时,
依然能保持稳定的学习轨迹。