
第一节:引言 在深度学习进入“大模型时代”之前,处理序列任务(如机器翻译、文本摘要)的主流框架是 Encoder-Decoder(编码器-解码器) 结构,通常被称为 Seq2Seq 模型。 1.1 编码器-解码器的工作原理 在标准的 Seq2Seq 架构中,编码器(通常是一个循环神经网络 RNN,如

第一节:机器翻译评估的挑战 在评估机器翻译(Machine Translation, MT)系统的性能时,最理想的方式是聘请双语专家进行人工评分。然而,随着深度学习模型的快速迭代,人工评估面临着不可逾越的瓶颈: 高昂的成本: 大规模语料库的翻译评估需要耗费大量的人力财力。 低下的效率: 人工评分无法

第一节:机器翻译的历史黎明与早期规则建模的局限 机器翻译作为自然语言处理(NLP)领域最古老且最具挑战性的课题之一,其构想几乎与现代计算机的诞生同步。早在 20 世纪 50 年代,研究人员就开始尝试让机器理解并转换人类语言。 1. 1950s:冷战背景下的技

第一节:重新定义“深度”——从一维到二维的跨越 在谈论深度学习时,我们经常听到“深层网络”这个词。但在循环神经网络(RNN)的语境下,“深度”其实有两个截然不同的维度。 RNN 的第一种深度:时间轴上的展开

第一节:引言 在自然语言处理(NLP)的早期,我们习惯于使用标准的 RNN、LSTM 或 GRU。这些模型都有一个共同的特点:它们是“因果”的(Causal)。这意味着在处理每一个词(x(t))时,模型只能看到该词及其之前的上下文。 1.1 左侧上下文的局限性 想象一下,我们正在训练一个情感分类模型

第一节:前言 在处理图像识别(CNN)或简单的数值回归(MLP)时,我们的模型通常假设输入数据是相互独立的。然而,人类的语言、动人的旋律、或是波动的股票曲线,都具有一个共同特征:序列性(Sequentiality)。 如果你只看“马”这个字,你无法判断它是主语、宾语还是形容词;但如果你看到“那匹马在
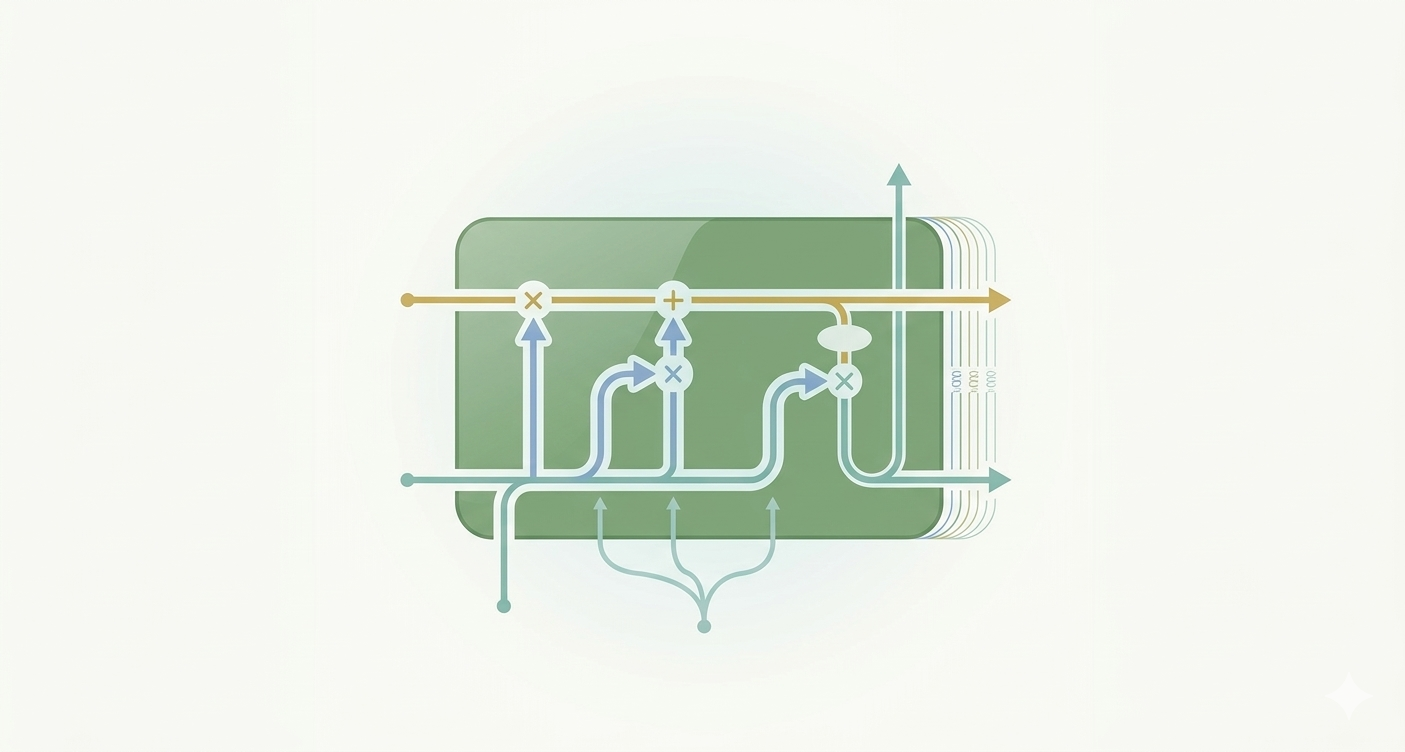
第一部分:引言 在深度学习的序列建模中,循环神经网络(RNN)曾被寄予厚望。然而,传统的 vanilla RNN 在实际应用中存在一个致命的缺陷:“短时记忆”。由于梯度消失问题,它很难捕捉到序列中跨度较大的长距离依赖关系。 为了打破这一瓶颈,长短期记忆网络(Long Short-Term Memor
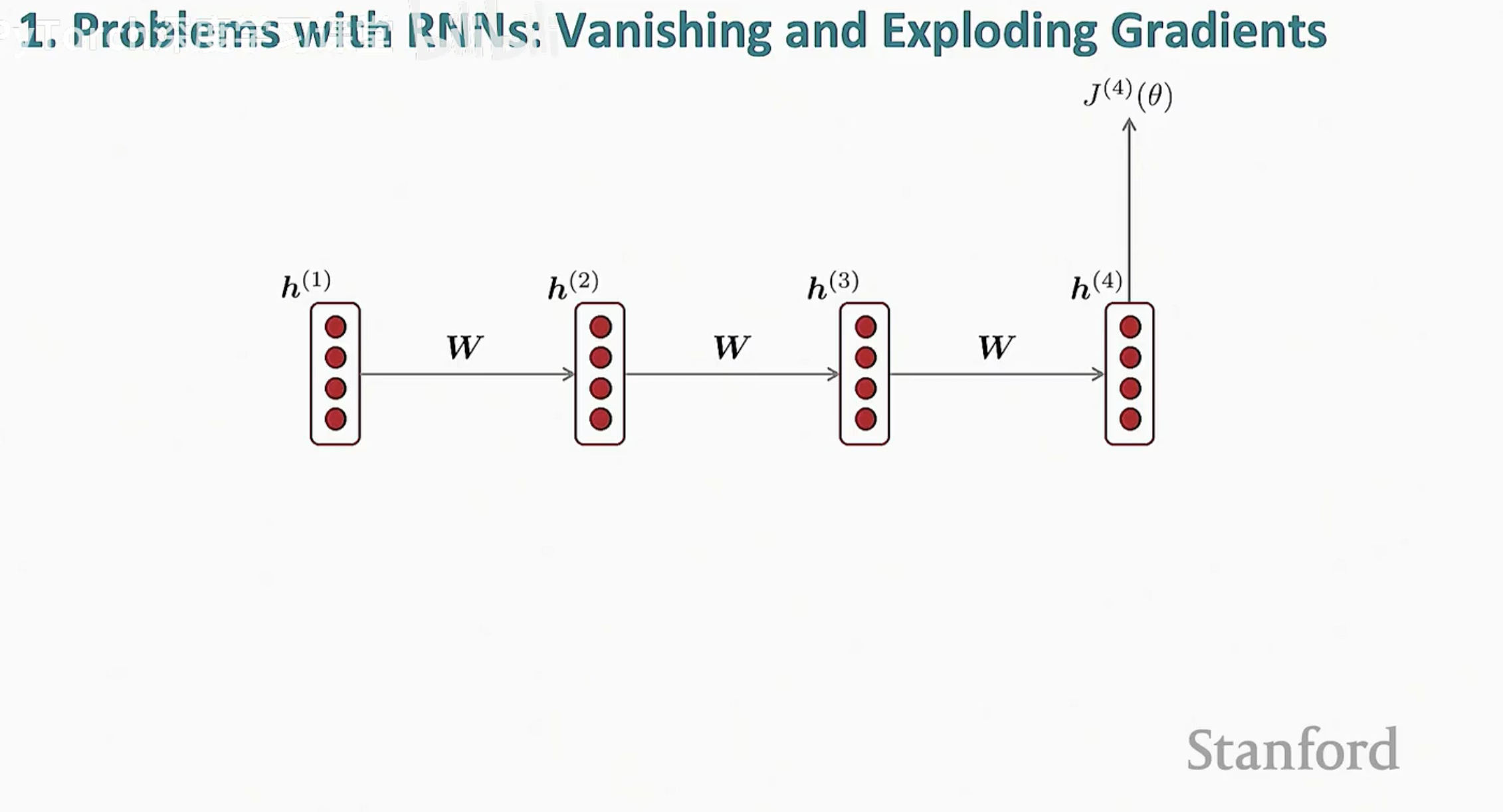
第一节:引言 在深度学习的序列建模中,循环神经网络(RNN)曾被寄予厚望。由于其循环连接的结构,理论上 RNN 能够保留无限长的历史信息。然而在实际训练中,你会发现它表现得非常“短视”——它能轻易记住上一个单词,却总是忘记上一个段落。 这种局限性的核心原因,在于反向传播(Backpropagatio
第一节: 什么是语言模型? (Language Model Recap) 在深入探讨如何评价一个模型之前,我们首先需要明确:我们要评价的对象究竟是什么? 1.1 核心定义:预测未来 从本质上讲,语言模型 (Language Model, LM) 是一个极其简单的系统:它只做一件事——预测下一个词 (
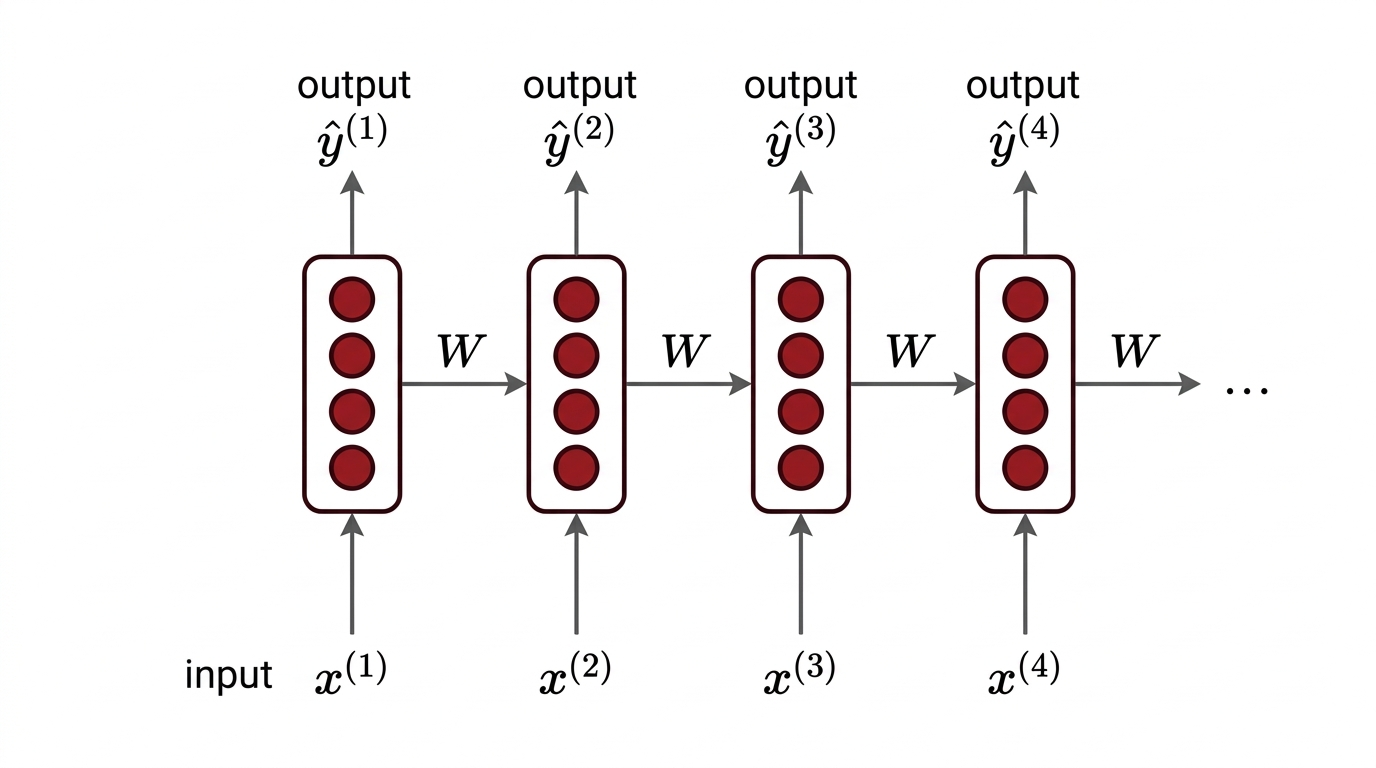
第一节:RNN 的核心架构 1.1 为什么我们需要 RNN? 在处理图像识别或简单分类任务时,传统的全连接神经网络(DNN)和卷积神经网络(CNN)表现卓越。但在处理序列数据(如自然语言、语音、股票走势)时,它们会面临两个致命的缺陷: 输入长度固定:传统模型要求输入向量的维度必须预先设定,但现实中的
