第一节:句式结构的两种视野 在自然语言处理中,理解一个句子不仅仅是识别每个词的意思,更重要的是理解这些词是如何组合在一起表达完整语义的。目前主流的句法分析主要有两种视角:成分句法分析和依存句法分析。 1. 成分句法分析 (Constituency Parsing) 成分句法分析又被称为短语结构语法(
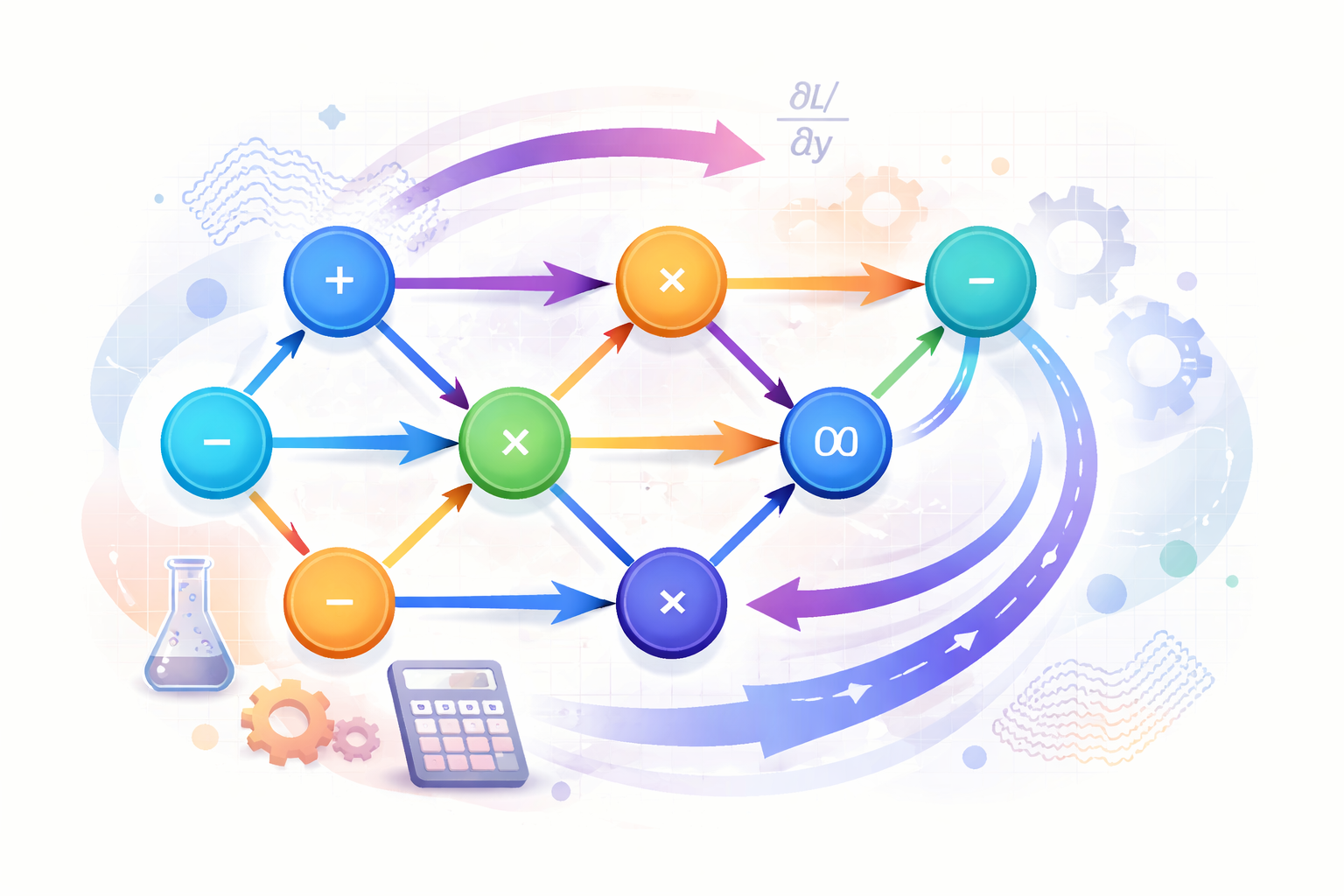
第一节:计算图定义 在深度学习中,软件并不是直接处理一长串复杂的数学公式,而是将神经网络的方程式表示为一张“图”。这种表达方式不仅让复杂的运算变得直观,更是自动求导技术的基础。 1. 什么是计算图? 计算图(Computation Graph)是数学表达式的一种图形化表示。在这种结构中: 源节点(S
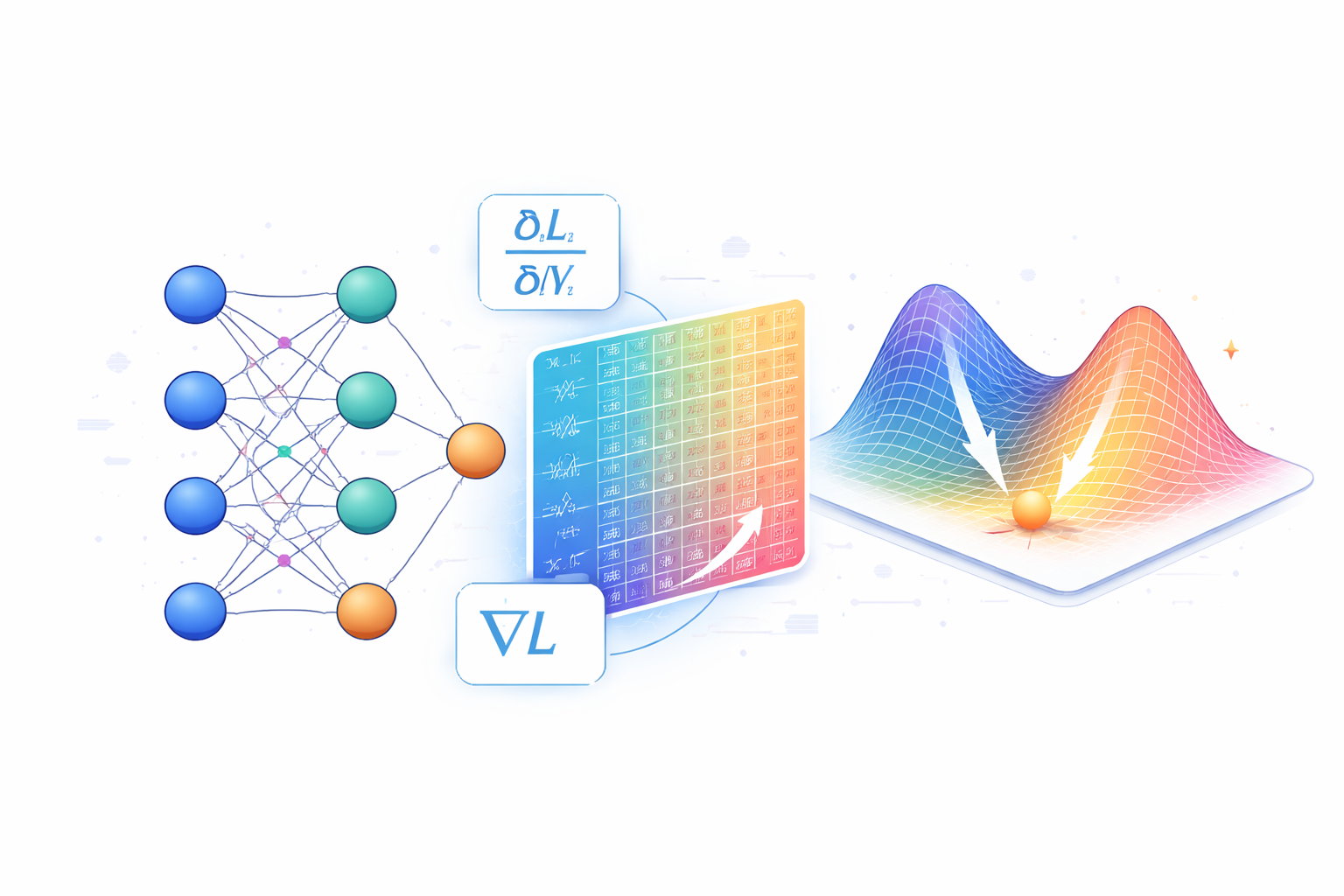
第一节:从并行逻辑回归到神经网络 1. 神经网络的本质 很多人初学神经网络时会觉得它是一个复杂的“黑箱”,但从数学视角来看,神经网络并不是某种全新的魔法。本质上,一个神经网络可以看作是同时运行的多个逻辑回归。 当我们审视一个简单的单层结构时,它执行的操作与逻辑回归高度相似:对输入特征进行加权求和,然

第一节:NLP 分类任务的本质挑战 在自然语言处理(NLP)的演进过程中,我们始终在解决一个核心矛盾:语言的离散符号本性与语义的连续复杂性之间的冲突。 从离散符号到分布式表示 早期的 NLP 依赖于独热编码(One-hot encoding),这种方式将单词视为孤立的符号,无法捕捉词与词之间的相似性

第一节:机器如何“理解”语义? 在深度学习统治自然语言处理(NLP)之前,计算机看待单词的方式非常简单:每一个词都被视为一个孤立的符号。通常我们使用 One-hot 编码,即给每个词一个极长的向量,其中只有一个位置是 1,其余全是 0。 但这种方法有一个致命的缺陷:它无法表达词与词之间的关系。在 O
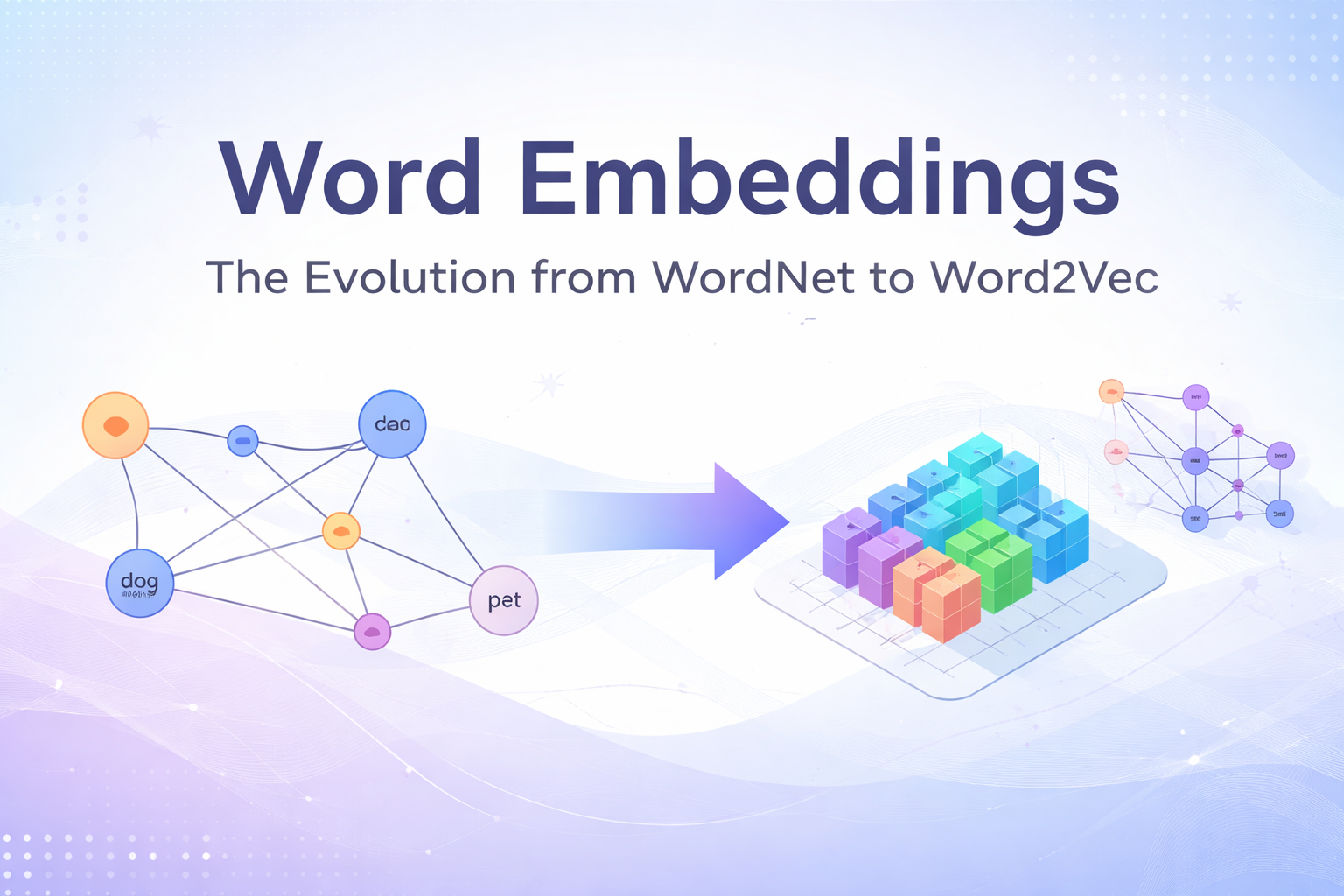
第一节:计算机如何理解“意义”? (How do we represent meaning?) 在深入研究复杂的算法之前,我们需要先思考一个哲学问题:什么是“意义”(Meaning)? 1. 语言学中的“意义” 根据《韦伯斯特词典》的定义,意义通常指一个词、短语所代表的“思想”(Idea)。在传统

一、基尼指数(Gini Index) 1.1 基尼指数的基本定义(Definition of Gini Index) 在分类问题中,一个节点内部样本越“混乱”,该节点就越不纯;反之,如果节点中的样本几乎都属于同一类,则说明该节点分类效果较好。

一、分类(Classification)的基本概念 1.1 有监督学习与无监督学习 在进入分类任务之前,需要先区分两个非常基础的概念:有监督学习和无监督学习。 有监督学习中

一、什么是数据预处理(Introduction to Data Preprocessing) 在机器学习或数据挖掘中,我们常听到一句话:“数据质量决定模型上限”。 这句话背后的核心,其实就是数据预处理(Data Preprocessing)。 在真正建模之前,我们拿到的数据往往是杂乱的、不完整的、有

