
一、离散与连续状态
在强化学习(Reinforcement Learning, RL)中,状态(State) 描述了智能体所处的环境信息。不同的任务和环境,会决定状态是离散的还是连续的。
离散状态(Discrete State)
在离散环境中,状态通常是有限个离散位置或情境。
例如图中上方的网格环境中,智能体(小车或探测器)可以出现在格子 1~6 中的任意位置。
这种表示方式非常适合初学强化学习时的教学任务,比如“格子世界”(Grid World)。
在这种离散场景下,状态空间可以被枚举出来:
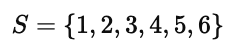
智能体只需要在这几个状态之间进行移动(向左或向右),策略 π(s) 就能明确地定义在每个离散格子中采取哪种动作。
连续状态(Continuous State)

然而在现实世界中,大多数任务的状态并非离散,而是连续的。
图中下方展示了一个带有卡车的例子,它的状态不仅仅是一个“位置编号”,而是由多个连续变量组成的向量:
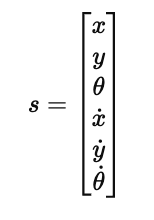
这意味着状态空间是无限维、连续可变的。
例如,在自动驾驶、机械臂控制、飞行器导航等场景中,状态往往包括位置、速度、角度、角速度等连续参数。
连续状态空间的实例:自动直升机(Autonomous Helicopter)

图中展示了一个自动直升机的例子。
直升机的状态不仅包含二维位置,而是一个三维连续空间,还包括姿态角、角速度、线速度等复杂特征:
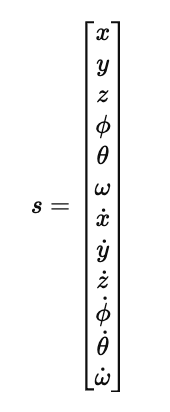
在这样的连续状态空间中,强化学习算法无法像离散状态那样简单枚举每个状态,而需要通过函数逼近(Function Approximation) 来学习价值或策略函数,例如使用神经网络来映射状态与动作的对应关系。
二、月球着陆器环境与奖励函数
强化学习中,智能体(Agent)需要在一个环境(Environment)中不断尝试行动,并根据奖励(Reward)来调整行为策略。
月球着陆器(Lunar Lander) 是一个非常经典的连续状态强化学习任务,它很好地展示了状态、动作与奖励三者之间的关系。
环境设定(Environment Setup)
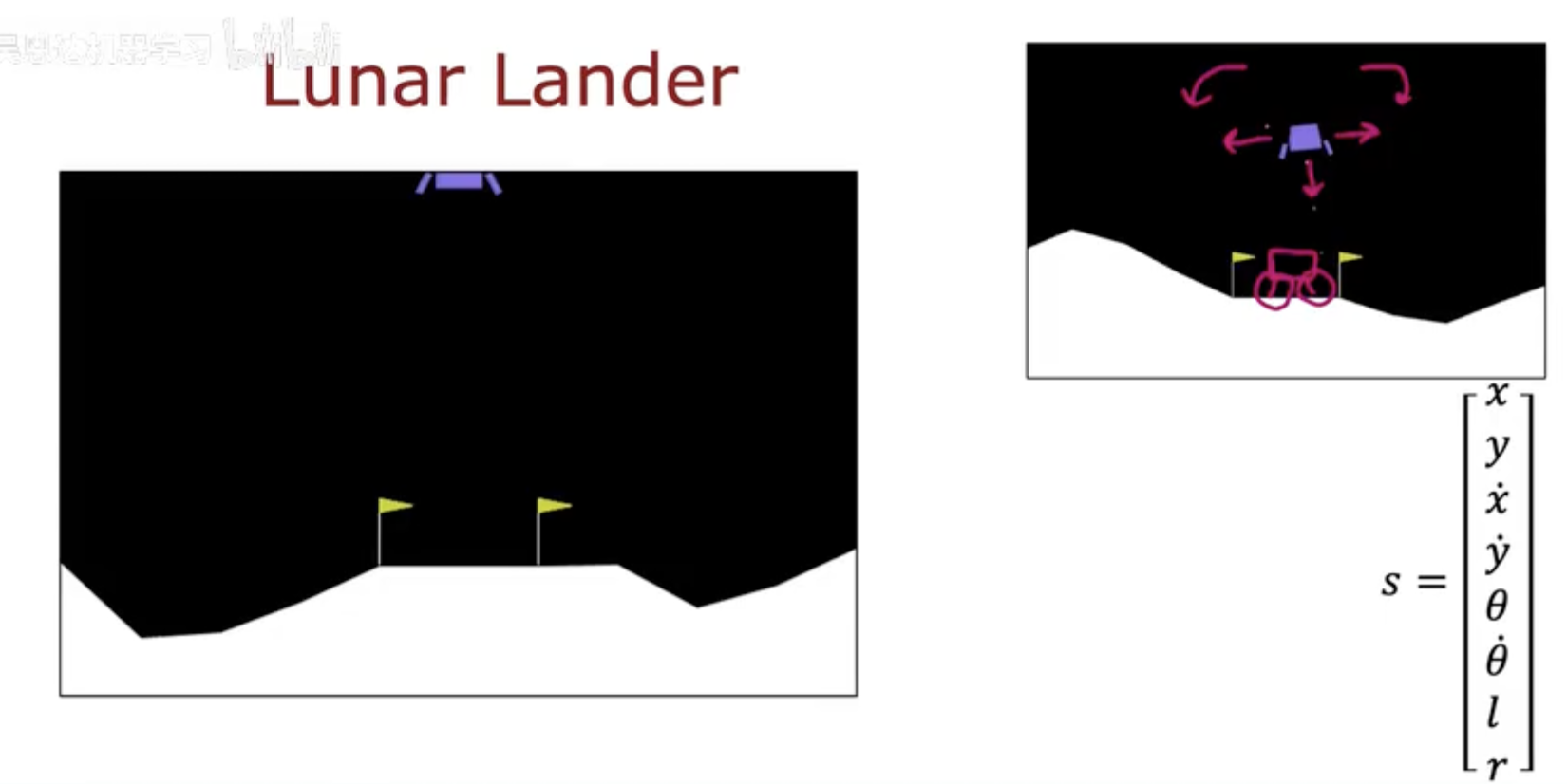
如图所示,月球着陆器的任务是:
让一艘带有推进器的小型飞船,安全地降落到地面上指定的着陆区(由两面小旗标出)。
着陆器的状态可以由一个连续变量向量表示:
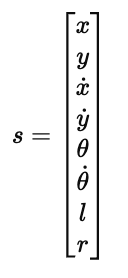
其中:
x,y:飞船的水平与垂直位置;
x˙,y˙:速度分量;
θ,θ˙:角度与角速度;
l,r:左右着陆支架是否触地(布尔值)。
这种状态表示法意味着:智能体不仅要学会“落地”,还要考虑角度、速度等复杂因素,使得整个过程保持稳定。
策略目标(Goal and Policy)
强化学习的目标是学习一个策略 π(s),在任意状态 s 下选择一个动作 a=π(s),
以最大化未来的累计奖励(return)。
在着陆器任务中,这意味着要找到一个策略,使飞船既能稳稳着陆,又能尽量少消耗燃料。
奖励函数(Reward Function)
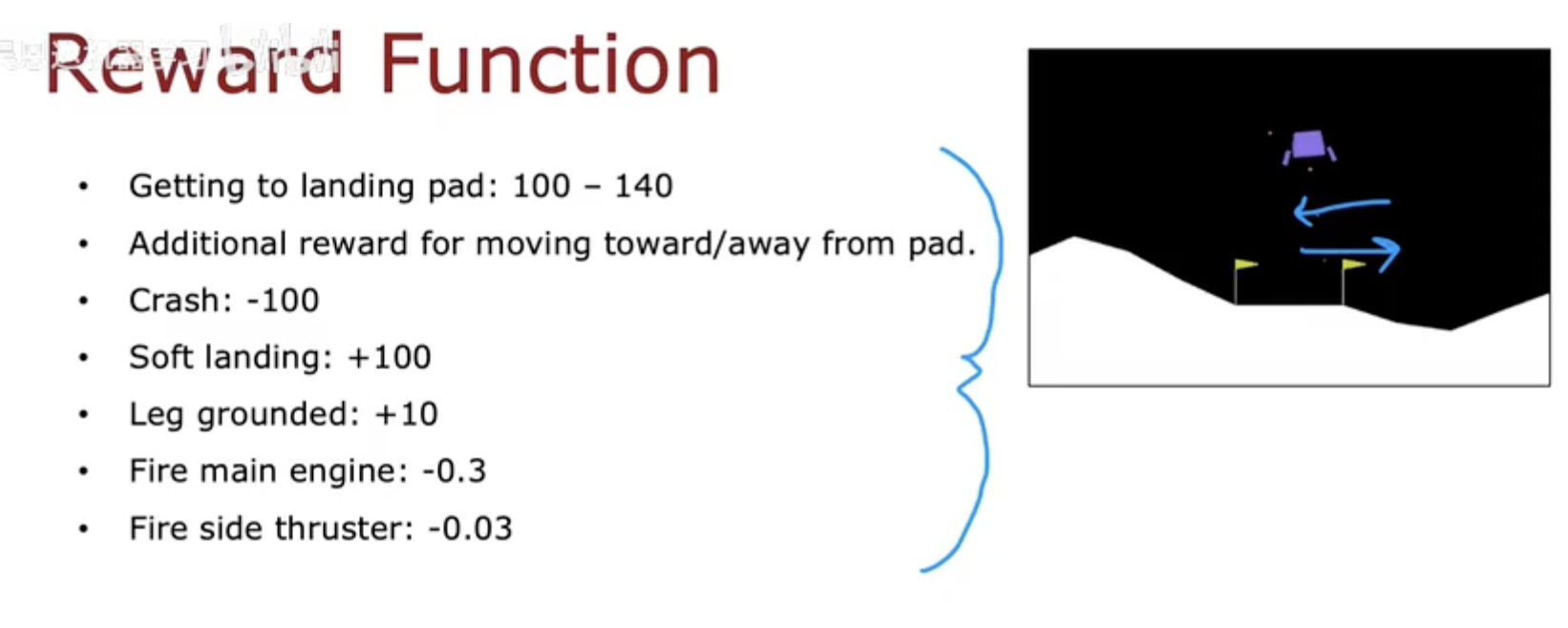
在强化学习中,奖励函数 R(s) 决定了智能体学习的方向。
月球着陆器任务的奖励被精心设计,使得飞船在“更接近理想行为”时获得更高分值:
这意味着智能体需要在速度控制与燃料使用之间进行权衡。
如果燃料消耗太多会被扣分,但不使用推进器又可能导致坠毁。
强化学习的目标(RL Objective)

因此,这个任务的核心目标是:
学习一个策略 π(s),使得智能体能够最大化期望回报(Expected Return):
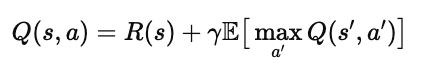
其中 γ 是折扣因子(discount factor),控制模型对未来奖励的重视程度。
在月球着陆器中,通常使用 γ=0.985,这让模型既关注短期行为(如燃料使用),又能学习长期目标(平稳落地)。
三、深度强化学习与价值逼近
在前两节中,我们已经了解了连续状态下强化学习任务的复杂性。
月球着陆器这种环境不仅状态空间是连续的,而且每个状态对应的动作结果也带有随机性。
为了在这种高维、非线性环境中学习有效策略,我们需要引入深度强化学习(Deep Reinforcement Learning, DRL) 的思想。
1. 神经网络逼近 Q 函数(Approximating Q(s,a) with Neural Networks)
在离散环境中,我们可以用表格记录每个状态–动作的 Q 值;
但在连续环境中,状态无限多,根本无法枚举。
于是我们使用神经网络 Q(s,a;θ) 来逼近 Q 函数。
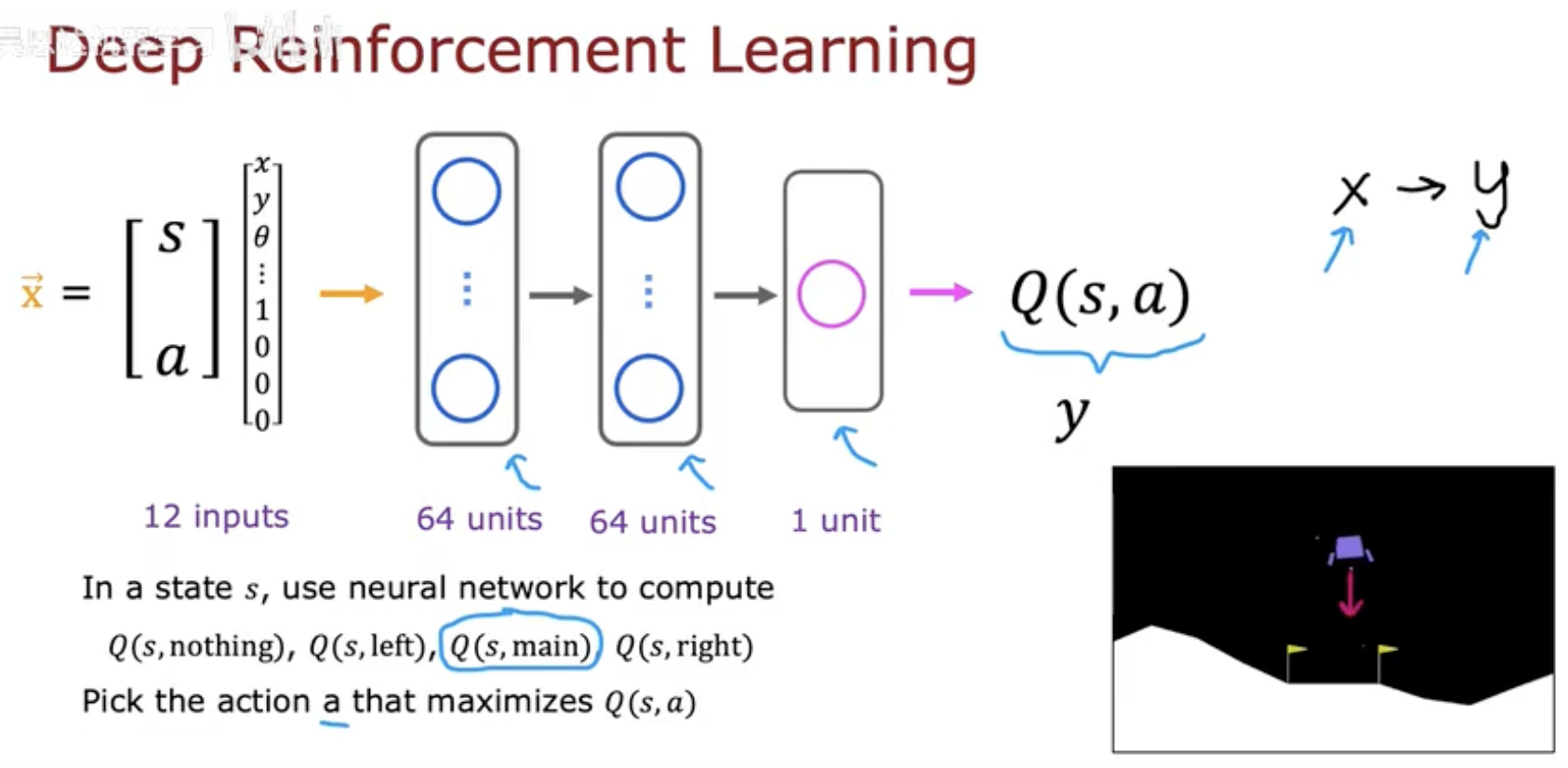
这张图展示了深度强化学习的基本结构:
输入层接收连续状态向量 s(例如位置、速度、角度等);
隐藏层学习到状态与动作之间的非线性关系;
输出层预测不同动作的 Q 值。
网络的目标是学习参数 θ,使得 Q 网络对每个状态–动作组合的估计值尽可能接近真实的期望回报。
2. 贝尔曼方程与目标更新(Bellman Equation for Value Update)
神经网络的训练依然遵循贝尔曼方程,只不过公式稍作修改:
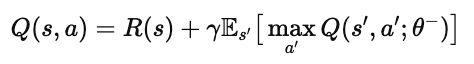
其中:
θ 是当前网络的参数(online network);
θ− 是目标网络(target network)的参数,用于稳定训练;
s′ 表示执行动作后的下一状态;
R(s) 是即时奖励。

这张图用箭头表示了“当前状态 → 动作 → 下一个状态”的循环关系,
展示了 Q 值如何根据奖励与未来预测的最大 Q 值进行递推更新。
3. 学习算法流程(Learning Algorithm)
训练一个深度强化学习智能体的过程,可以总结为以下步骤:

采样(Sampling):
智能体与环境交互,收集状态–动作–奖励–下一状态四元组 (s,a,r,s′)。存储(Replay Buffer):
将采样数据保存到经验回放池中,以便后续随机抽样训练,避免时间相关性。更新(Update Q Network):
从经验池中抽取批次样本,计算目标值:
然后最小化损失函数:
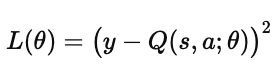
同步(Target Network Update):
定期将在线网络参数复制给目标网络,使学习过程更稳定。策略改进(Policy Improvement):
智能体在每个状态选择 Q 值最大的动作: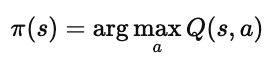
经过大量训练迭代后,智能体逐渐学会在连续状态空间中做出最优决策。
四、在连续世界中学习价值
强化学习的核心在于“学习经验”,而价值函数则是智能体理解世界的关键。
无论是离散格子中的移动,还是在月球上平稳降落的复杂控制任务,
智能体都在通过与环境的不断交互,去估计某个状态有多好(Value)。
从离散到连续的跨越
在离散状态下,智能体可以用表格形式记录每个状态的价值;
但在连续环境中,这种方式失效,因为状态是无限的。
深度强化学习的引入解决了这一难题:
神经网络不再“记住每个状态”,而是学会了从状态到价值的映射函数。
这使得算法能够处理飞行控制、机械臂操控、车辆导航等复杂任务,
成为通往真实智能的重要一步。
状态价值的意义
状态价值函数 V(s) 的含义,是在状态 ss 下遵循策略 π 所能获得的期望回报:
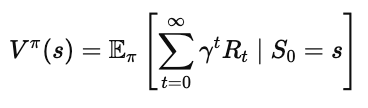
它让智能体不再盲目试错,而是能够“预测未来”,
提前评估某个状态的潜在收益。
在连续环境中,这种预测能力至关重要——
因为任何微小的状态差异都可能带来完全不同的结果。
从价值到策略
价值函数不仅衡量“状态好坏”,还直接指导策略改进:
智能体会不断比较不同状态或动作的期望价值,
并选择能带来更高长期回报的那一个。
在长期训练中,这种循环往复的“评估与改进”过程,
让智能体逐步逼近最优策略,实现真正意义上的自我学习。
最后的思考
连续状态空间的强化学习,是通往真实智能系统的重要桥梁。
从月球着陆器到自动驾驶,从机械臂到无人机,
所有这些智能体都需要理解“当前状态的价值”,
并基于这一理解去做出最优决策。
正如本文的主题所强调的那样:
理解连续状态中的价值,是强化学习走向现实世界的关键一步。