
一、连续特征的数据表示
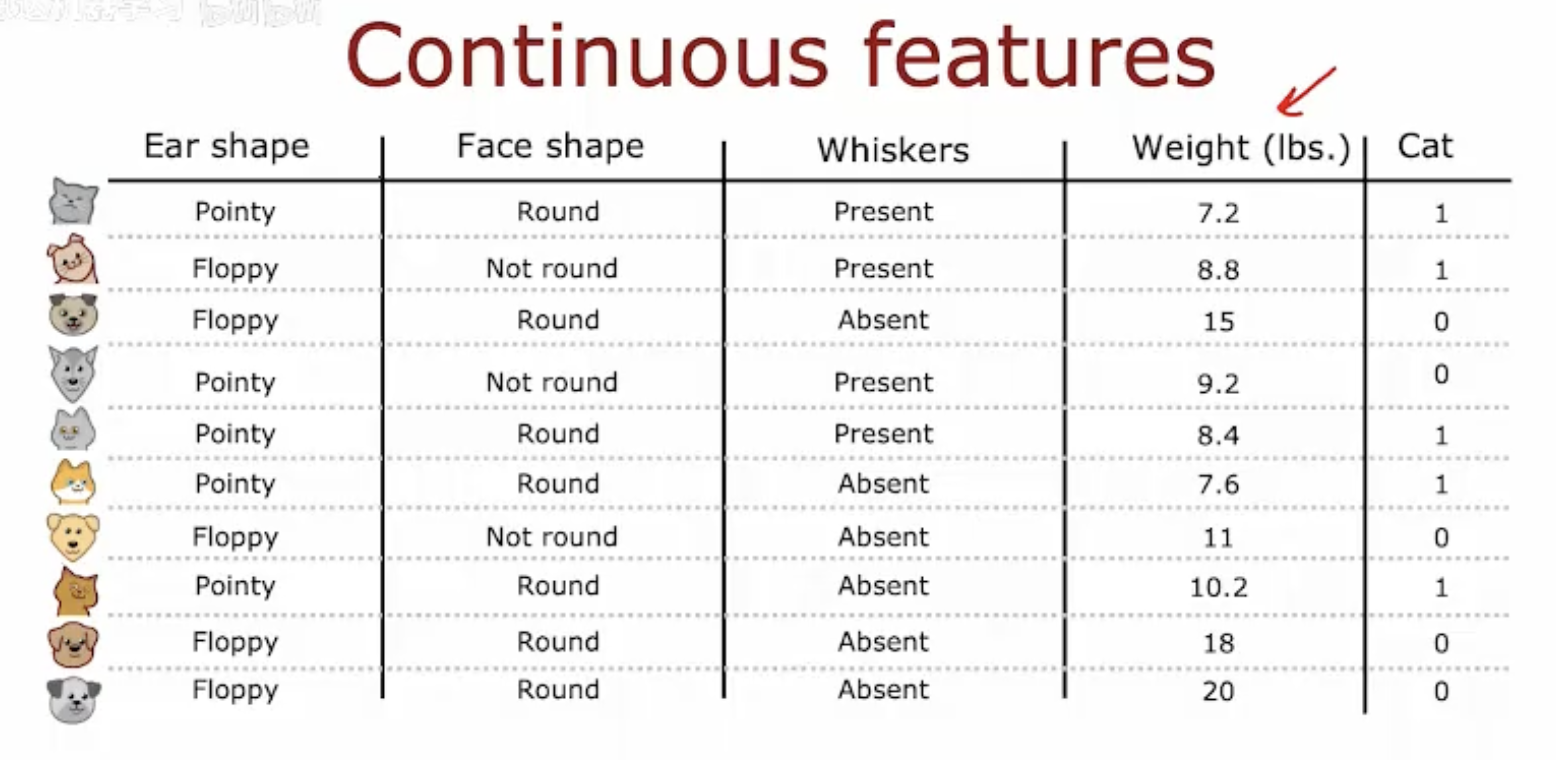
图片展示了一个关于宠物(猫和狗)的数据集,其中包含了几个特征:耳朵形状(尖耳或垂耳)、脸型(圆形或非圆形)、胡须(有或无)、体重(以磅为单位)以及一个目标变量“是否为猫”(用1表示猫,0表示狗)。
耳朵形状和脸型是分类特征,分别有“尖耳/垂耳”和“圆形/非圆形”两种状态。
胡须也是一个分类特征,表示为“有”或“无”。
体重是一个连续特征,以磅为单位,表示宠物的体重。
目标变量“Cat”是一个二元分类变量,用于区分宠物是猫还是狗。
这个数据集可以用于训练机器学习模型,以预测宠物的种类。连续特征如体重可以用于构建决策树,通过不同的阈值来分割数据,从而帮助模型做出预测。
二、基于连续变量的决策树构建
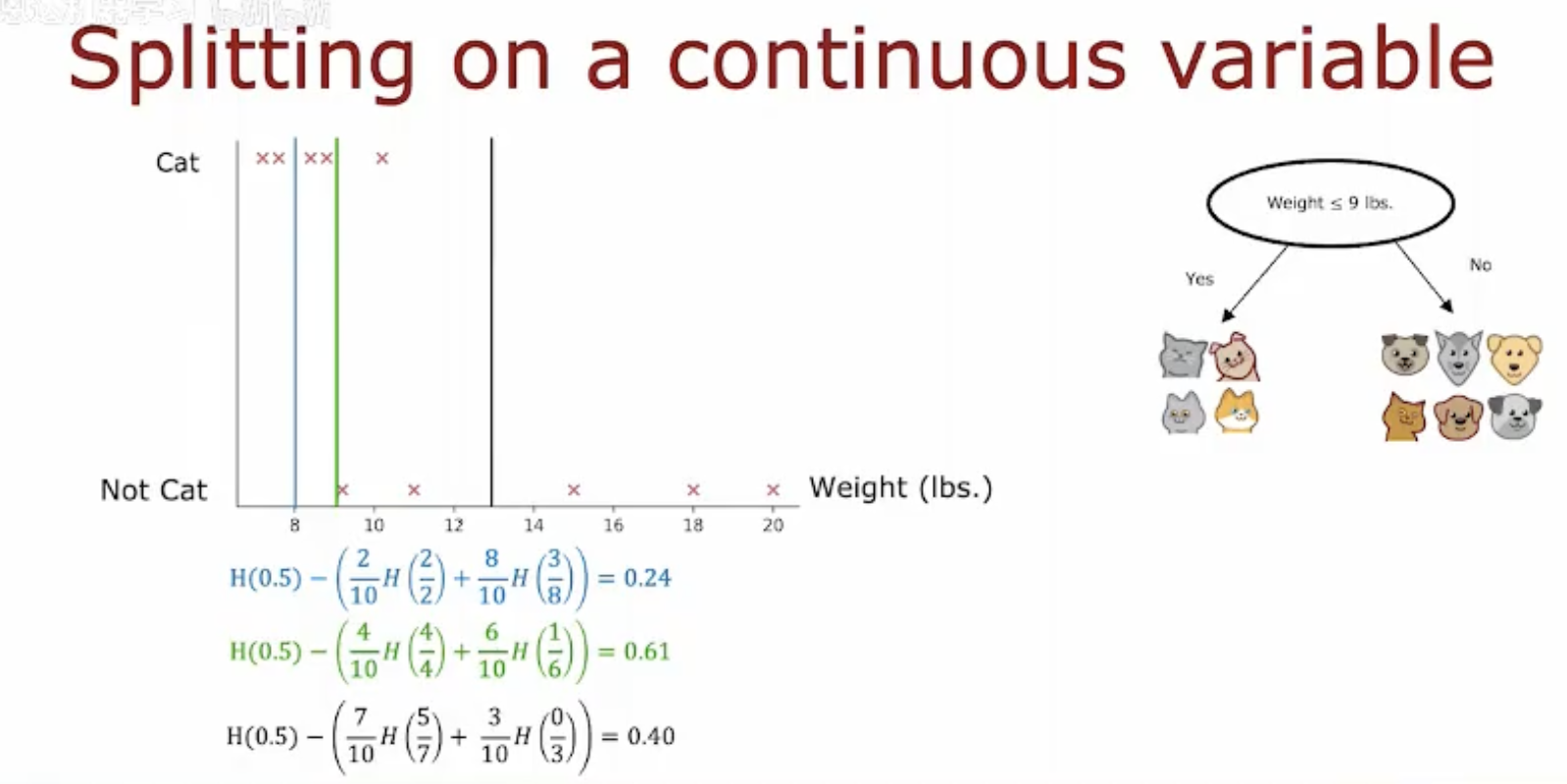
图片展示了如何使用体重这一连续特征来构建决策树,以区分猫和狗。
左侧图表:显示了体重与宠物种类之间的关系。横轴表示体重(磅),纵轴表示宠物种类(猫或非猫)。图中用“×”标记了非猫(狗),用“××”标记了猫。可以看到,体重在9磅以下的宠物更可能是猫。
右侧决策树:展示了一个简单的决策树,用于根据体重预测宠物种类。决策树的根节点是一个判断条件:“体重 ≤ 9 lbs.”,如果条件为真(是),则预测为猫;如果条件为假(否),则进一步根据其他特征进行预测。
信息增益计算:图中还展示了不同分割点的信息增益计算。信息增益用于衡量分割后数据集的不确定性减少的程度。计算公式为:

其中,H表示熵,是衡量数据集不确定性的指标。不同的分割点(如8磅、10磅等)会产生不同的信息增益值,选择信息增益最大的分割点可以最大化模型的预测能力。
三、总结:处理连续特征以构建决策树
在机器学习中,处理连续特征是构建决策树模型的关键步骤之一。以下是详细的总结,主要关注如何处理连续特征以构建决策树:
1. 识别连续特征
首先,识别数据集中的连续特征。在本例中,体重是一个连续特征,其值可以在一定范围内连续变化。
2. 选择分割点
选择一个或多个分割点来将连续特征转换为分类特征。分割点的选择通常基于某种标准,如信息增益、基尼不纯度等。
在图片2中,体重被用作分割点,例如,选择9磅作为分割点,将数据分为体重小于或等于9磅和体重大于9磅两组。
3. 计算信息增益
计算每个可能的分割点的信息增益,以确定哪个分割点能最大程度地减少数据集的不确定性(即熵)。
图片2展示了不同分割点的信息增益计算,例如,分割点8磅、10磅等的信息增益值分别为0.24、0.61和0.40。
4. 选择最佳分割点
选择信息增益最大的分割点作为决策树的节点。这有助于最大化模型的预测能力。
在本例中,分割点10磅的信息增益最大,因此被选为最佳分割点。
5. 构建决策树
使用选定的分割点构建决策树的节点。每个节点代表一个特征的分割点,每个分支代表分割后的数据子集。
在图片2的决策树中,根节点是体重≤9磅的判断条件,根据这个条件将数据分为两组。
6. 递归分割
对于每个分割后的数据子集,重复上述步骤,直到满足停止条件(如达到最大深度、节点中的样本数小于某个阈值等)。
这个过程会递归地在决策树中创建更多的节点和分支,直到每个叶节点都是纯的(即只包含一个类别的样本)或无法进一步分割。
7. 评估模型
使用测试数据集评估决策树模型的性能,确保模型具有良好的泛化能力。
可以通过交叉验证、混淆矩阵等方法来评估模型的准确性、召回率等指标。
通过以上步骤,可以有效地处理连续特征,并利用这些特征构建决策树模型。这种方法在处理包含连续变量的数据集时非常有用,特别是在需要进行分类预测的场景中。