
一、F1指标的定义
在机器学习和数据分析领域,F1指标是一个非常重要的评估工具。它通过综合考虑精确率(Precision)和召回率(Recall),来衡量分类模型的性能。精确率关注的是模型预测为正的样本中,实际为正的比例;而召回率则关注实际为正的样本中,被模型正确预测为正的比例。
通俗理解:
F1指标就像是在评价一个侦探的工作表现。精确率就像是侦探抓到的人中,真正有罪的比例;召回率则是所有有罪的人中,被侦探抓到的比例。F1指标就像是综合考虑这两个方面,给出一个全面的评价。如果一个模型的F1指标很高,那就意味着它在预测正样本时既准确又全面,就像一个既不会冤枉好人,又能抓住所有坏人的优秀侦探。
二、精确率与召回率的权衡
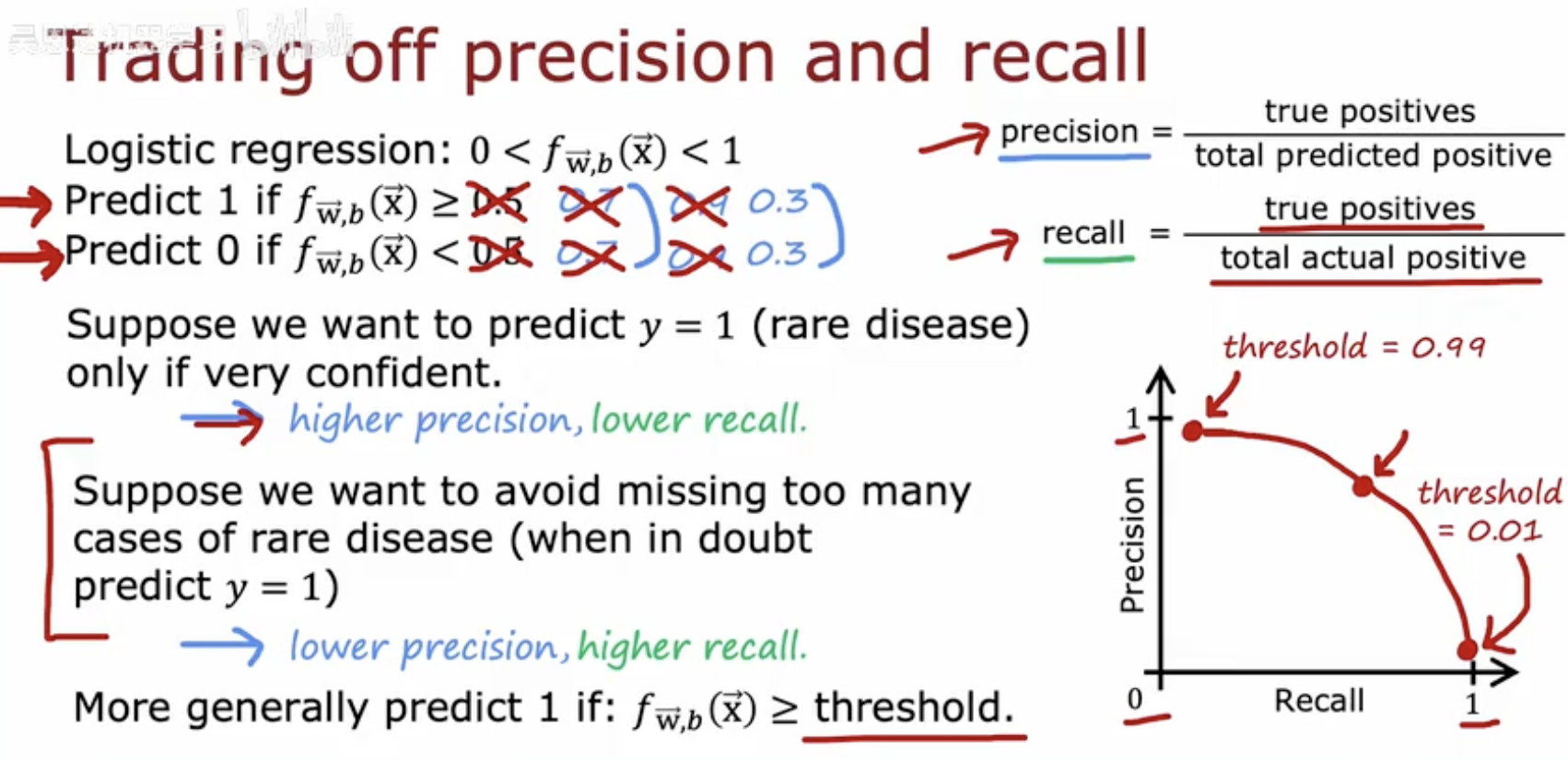
这幅图片解释了在机器学习中如何权衡精确率(Precision)和召回率(Recall)。
逻辑回归:输出值 0< fw,b(x) <1 表示模型预测的概率。
预测规则:
如果 fw,b(x)≥0.5,则预测为1(正类)。
如果 fw,b(x)<0.5,则预测为0(负类)。
精确率和召回率:
精确率(Precision)定义为真正例(True Positives)除以总预测为正的样本数(True Positives + False Positives)。
召回率(Recall)定义为真正例(True Positives)除以总实际为正的样本数(True Positives + False Negatives)。
阈值调整:
如果我们希望只在非常有信心时预测 y=1(例如罕见疾病),则设置较高的阈值(例如0.99),这会导致更高的精确率但召回率较低。
如果我们希望避免错过太多罕见疾病的案例(即使在不确定时),则设置较低的阈值(例如0.01),这会导致精确率较低但召回率较高。
一般规则:更一般地,如果 fw,b(x) ≥ threshold,则预测为1。
图示:图中展示了精确率和召回率之间的关系,随着阈值的变化,精确率和召回率呈现出相反的趋势。阈值越高,精确率越高,召回率越低;阈值越低,精确率越低,召回率越高。
三、F1分数:精确率与召回率的平衡

这张图片主要展示了如何通过F1分数来比较不同算法的精确率(Precision)和召回率(Recall)。
表格数据:
表格列出了三个算法的精确率(P)和召回率(R)。
算法1:精确率为0.5,召回率为0.4。
算法2:精确率为0.7,召回率为0.1。
算法3:精确率为0.02,召回率为1.0。
F1分数计算:
F1分数是精确率和召回率的调和平均数,它能够平衡这两个指标。
算法1的F1分数为0.444。
算法2的F1分数为0.175。
算法3的F1分数为0.0392。
平均值比较:
图片中指出,简单地计算精确率和召回率的平均值(即(P+R)/2)是不准确的,因为它没有考虑到精确率和召回率之间的平衡。
例如,算法2的精确率和召回率平均值是0.4,但F1分数是0.175,这表明算法2在精确率和召回率之间存在较大的不平衡。
F1分数公式:
F1分数的计算公式是:

这个公式强调了精确率和召回率的乘积,而不是它们的和,从而更好地平衡了这两个指标。
结论:
图片强调了F1分数在比较不同算法时的重要性,因为它更合理地平衡了精确率和召回率,而不是简单地取平均值。
通过F1分数,我们可以更全面地评估一个算法在精确率和召回率之间的平衡,从而做出更合理的选择。