
一、引言
在推荐系统中,一个重要的任务不仅是预测用户是否会喜欢某个物品,还包括 找到与该物品相关的其他物品。
例如:
在电商网站上,用户正在浏览一双运动鞋,系统可能会推荐“相关商品”,如运动袜或同品牌的运动衣。
在视频网站上,用户看完一部爱情片,系统会推荐更多类似题材的影片。
这种“查找相关项目”的能力,使得推荐系统不仅能满足用户的即时需求,还能帮助用户 发现新的兴趣点。从算法的角度来看,这通常依赖于对物品特征的建模和相似度的计算。
二、基于特征的相似性查找

在协同过滤模型中,每个物品都可以用一个特征向量 x(i) 来表示。这个向量可能包含多个维度,例如:
x1:物品的“浪漫”程度;
x2:物品的“动作”元素;
甚至更多维度(如 x3,x4,…)。
核心问题:如果我们想要找到与物品 i 相似的物品,就需要在所有其他物品中寻找一个物品 k,使得它的特征向量 x(k) 与 x(i) 尽可能接近。
数学方法
衡量两个物品相似性的常用方式是 欧几里得距离(Euclidean Distance):
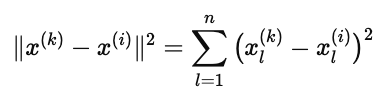
其中:
x(i) 表示物品 i 的特征向量;
x(k) 表示候选物品 k 的特征向量;
n 是特征的维度数。
最相似的物品就是那个与 x(i) 距离最小的物品。
通俗理解
可以把每个物品看作空间中的一个点。物品之间的“接近程度”,就像两个点在平面或空间中的距离。越靠近的点,表示物品之间越相似。
例如,如果某部电影的特征向量主要在“浪漫”维度上很高,那么和它最接近的电影,往往也是以浪漫为主的影片。
三、协同过滤的局限性:冷启动问题

虽然基于特征的相似性查找能够找到相关物品,但在实际应用中,协同过滤仍然面临一个重大挑战:冷启动问题(Cold Start Problem)。
(1)什么是冷启动问题?
冷启动问题指的是当系统遇到 新物品 或 新用户 时,由于缺少历史交互数据,模型无法准确给出推荐。
新物品冷启动:比如一部新上映的电影还没有人打分,系统无法判断它的特征向量。
新用户冷启动:一个新注册的用户没有看过或打过分的电影,系统不知道他的兴趣偏好。
(2)为什么冷启动很难?
协同过滤依赖于用户与物品的历史交互数据。如果数据过少,就无法进行相似性计算。例如:
新物品没有评分,无法判断与哪些老物品相似;
新用户没有行为数据,系统无法找到“兴趣相似的用户”。
结果是:推荐系统在初期可能什么也推荐不出来,用户体验会大打折扣。
四、解决思路:使用辅助信息
为了解决冷启动问题,推荐系统通常会借助 辅助信息(Side Information),也就是物品或用户的额外特征。这样,即使缺少交互数据,也能初步推测出相似性和偏好。
(1)物品的辅助信息
类型(Genre):比如动作片、爱情片、喜剧片;
演员(Movie Stars):某位明星参演的电影,容易被粉丝喜欢;
制作公司或导演:具有特定风格的作品。
这些信息能帮助系统在新电影刚上线时,推测它可能会吸引的用户群体。
(2)用户的辅助信息
人口统计学特征(Demographics):年龄、性别、地域;
兴趣偏好(Preferences):用户在注册时填写的标签或喜好;
行为特征:即使没有打分,用户的浏览记录或点击行为也能提供线索。
(3)通俗理解
这就像朋友推荐一部新电影时,即使没人看过,他也会说:
“这是动作片” → 吸引爱看动作片的人;
“主演是某某明星” → 吸引明星粉丝;
“导演风格和你喜欢的电影很像” → 帮助你判断是否值得一看。
通过利用这些 外部信息,推荐系统可以在冷启动阶段仍然给用户合理的推荐,保证体验的连续性。
五、总结与应用
在这篇文章中,我们探讨了推荐系统中 查找相关项目 的核心思想和实践方法:
基于特征的相似性查找
每个物品可以用特征向量表示。
通过计算欧几里得距离或其他相似度度量,找到与目标物品最接近的候选物品。
冷启动问题
当新物品或新用户缺少交互数据时,系统无法直接建模。
这是协同过滤类算法的天然缺陷。
解决思路:使用辅助信息
借助用户的年龄、兴趣标签、地域等信息;
借助物品的类型、主演、制作公司等信息;
在缺乏评分数据时,仍能初步推测相关性和偏好。
应用场景:
电商平台:推荐“相关商品”,提升购买转化率。
视频/音乐平台:推荐相似影片或歌曲,延长用户停留时间。
新闻/信息流:推荐同类主题文章,提高用户点击率。