
一、引言
在数据挖掘与机器学习中,我们经常强调“了解数据比使用模型更重要”。原因很简单:模型的表现往往不是由算法本身决定的,而是由数据的特征决定的。如果我们不了解数据的维度、稀疏性、分辨率以及规模,就无法正确选择分析方法,也无法判断模型是否能在这些数据上有效工作。
为了帮助你建立对“数据特征”的整体理解,我们先通过一张概览图来认识四个最关键的特征。

在这张图中,数据的四个重要特征依次被列出:维度(Dimensionality)、稀疏性(Sparsity)、分辨率(Resolution)和规模(Size)。它们看似简单,但背后对应着许多实际分析中必须考虑的挑战。例如,高维数据可能让距离计算变得毫无意义;稀疏数据在文本和推荐系统中无处不在;分辨率会直接影响模式是否可被识别;而数据规模则决定了我们能否使用某些模型或计算方法。
这些特征并不是孤立存在的,而是共同决定了一组数据在分析中会面临什么困难,也决定了我们需要采取什么策略来处理。接下来的章节将逐一围绕它们展开,用更直观的方式解释它们的重要性。
二、维度性(Dimensionality)
在数据集中,维度性(Dimensionality)指的是数据包含的属性或特征数量。每一个特征都相当于描述数据的一条“轴”,维度越多,我们对数据的描述就越细致。但与此同时,高维数据也会带来额外的分析负担。

随着维度数量的增加,数据空间的体积会呈指数级增长。这意味着我们需要处理的计算量也会随之变得庞大,许多算法在高维空间中的表现会明显变差。此外,高维数据不容易进行可视化,想要理解数据之间的关系也更加困难。因此,在处理此类数据时,常常需要借助 PCA、t-SNE、UMAP 等降维技术,帮助我们在保留主要信息的基础上降低维度,从而更好地分析数据。
为了让维度性的概念更直观,我们可以看一个简单的例子。假设我们有一个房屋销售的数据集,其中每一行数据代表一栋房子,包含多个特征:价格、面积、卧室数量、浴室数量以及所在位置。虽然五个特征并不算多,但想要在脑海中同时处理五个维度并进行分析,其实并不容易。
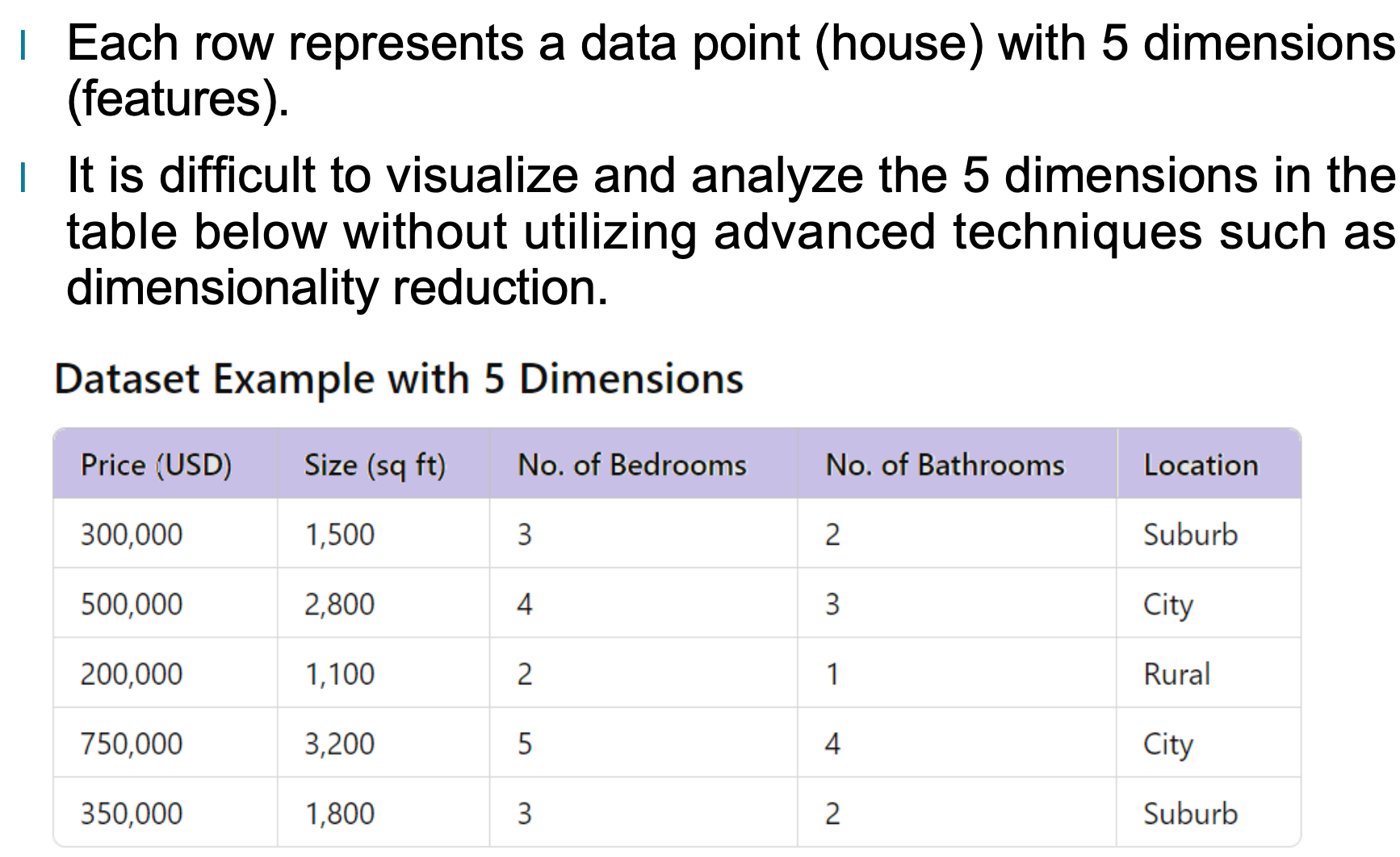
当特征数量继续往上增加,比如十几个、几十个甚至几百个维度时,直接观察这些维度之间的关系几乎变得不可能。因此,理解维度性的重要性,对于后续的数据预处理与分析有着非常关键的影响。
三、稀疏性(Sparsity)
在很多现实世界的数据集中,我们经常会遇到一种情况:大部分数据都是零或者缺失值。这就是所谓的“稀疏性(Sparsity)”。它的本质含义是:在一张数据表中,大多数位置都没有实际信息,只有少数位置包含真正有用的值。

稀疏数据集的常见代表包括购物篮分析(大部分商品顾客都不会买)、用户评分矩阵(大部分电影用户都没评分)、文本数据(大部分词不会出现在同一篇文章中)等。在这类数据里面,“0”更多表示的是“什么都没有发生”,并不是我们要重点分析的对象。这也导致在稀疏数据中,缺失或零值往往并不具备太大的信息量,相反,分析更关注那些真正出现的、非零的条目。
例如,在聚类这样的无监督学习任务中,如果算法没有特别处理稀疏性,容易被大量的零值误导,使得聚类结果偏向不必要的维度。因此,实际分析往往需要使用专门为稀疏数据设计的算法,避免让缺失或零数据主导分析结果。
为了更直观地理解稀疏性,下方的例子展示了一个典型的稀疏数据集:大多数产品列都是“0”,表示顾客没有购买对应商品,只有少数单元格出现非零值,例如购买数量。
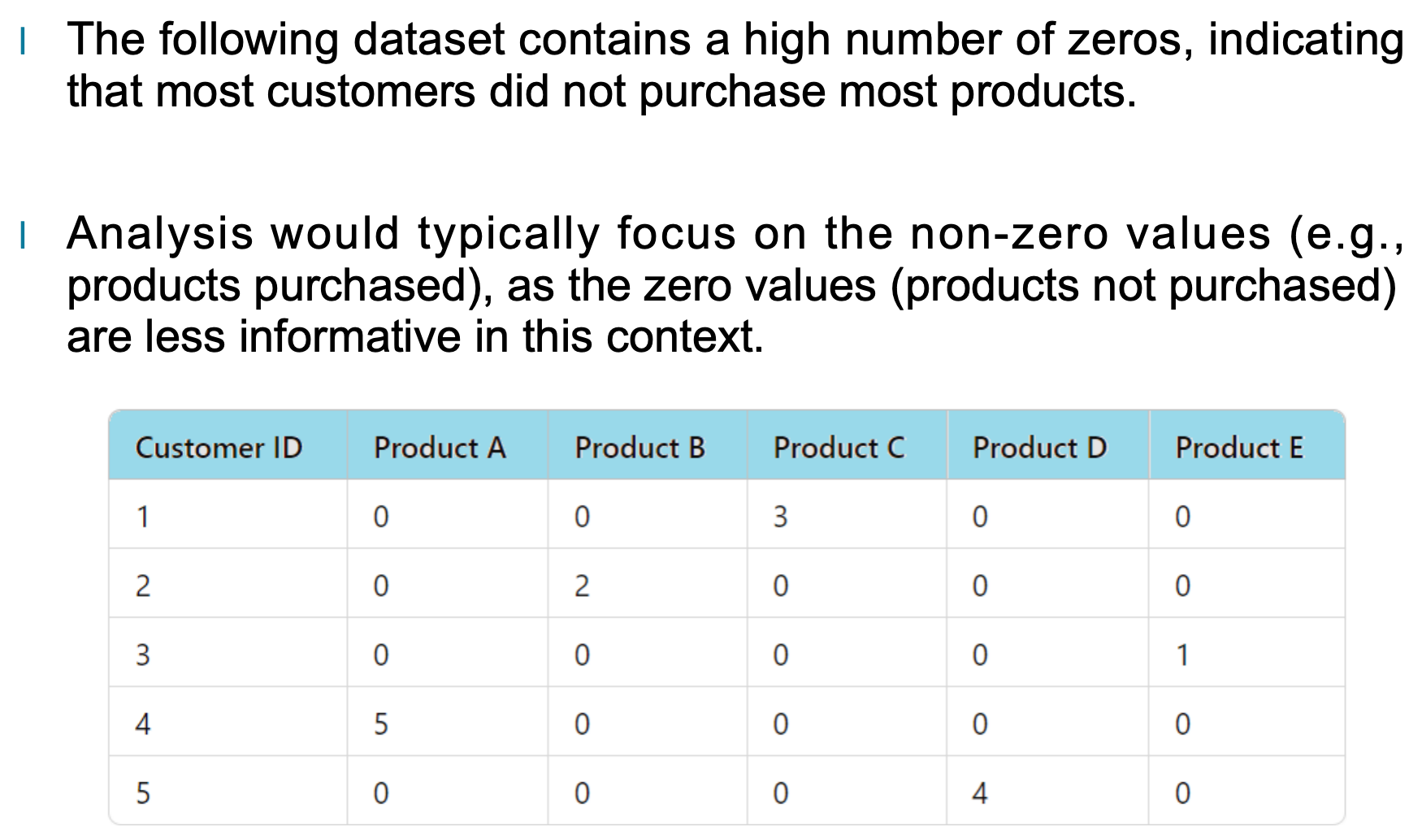
在这样的表格里,分析者通常会忽略大量的零值,而更多关注像“产品 C=3”“产品 E=1”这样出现非零数字的位置,因为它们才真正提供了顾客行为信息。换句话说,稀疏数据的分析重点,在于寻找“存在的证据”,而不是“缺失的部分”。
四、分辨率(Resolution)
在数据分析中,“分辨率”指的是数据被记录时的细节程度或粒度。简单来说,就是数据有多“细”,我们能看到多具体的信息。分辨率越高,数据中的细节越丰富;分辨率越低,数据更加概括。选择合适的分辨率是分析中非常关键的一步,因为不同粒度会直接影响我们能发现什么模式和结论。
1. 什么是数据的分辨率?
数据的分辨率描述了数据被采集时的精细程度。例如,记录天气可以按小时、天、月甚至年来统计,而不同的统计方式都会影响我们能观察到的现象。
分辨率高时,我们能看到非常精细的变化,但也有可能引入噪声或不必要的复杂度;分辨率低时,数据比较平滑,但可能丢失掉一些关键细节。

2. 分辨率对数据分析的影响
分辨率影响分析结果的最大方式,来自于它会改变我们能看到什么“模式”。
高分辨率数据(细粒度)
例如记录每小时温度,这样的数据非常适合观察短时变化,比如:当天突然升温
凌晨急速降温
极端天气出现的具体时段
但同时,这类数据也可能包含大量噪声,因此分析算法必须更加复杂。
低分辨率数据(粗粒度)
例如按“月”记录平均温度,这种数据很适合看长期趋势,比如:季节变化
气候周期
年度趋势
但它无法反映日常或实时的变化,意味着很多短期现象会被“平均”掉。
3. 示例:按月记录的平均温度
下面我们来看一个按月份记录的温度示例数据集:
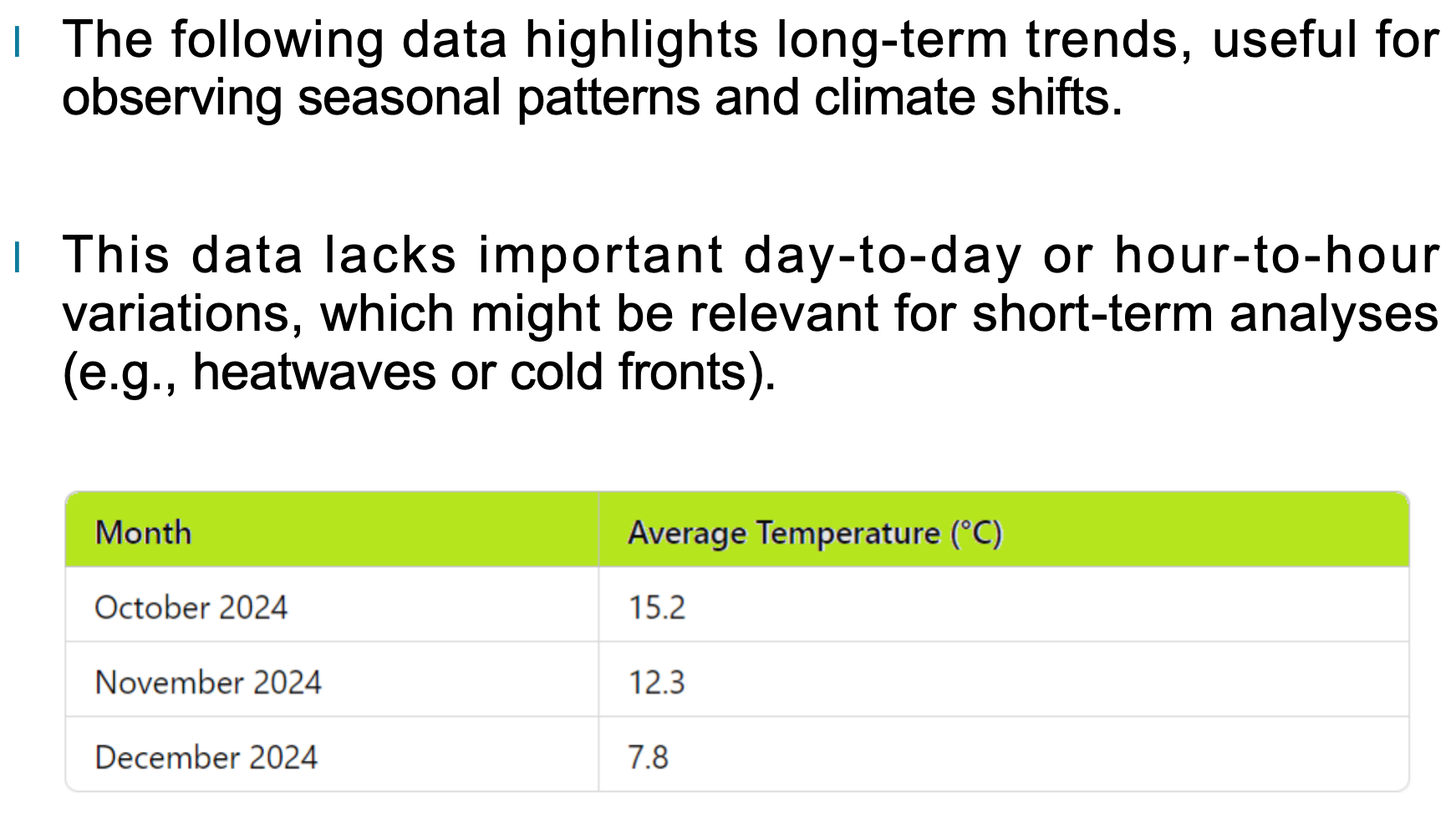
从这类数据中,我们可以清楚看到温度随月份逐渐下降的季节性趋势。这非常适合研究:
气候变化趋势
季节循环
长期温度变化分析
但同时,我们也注意到它无法反映:
某一天是否异常寒冷
是否有短期热浪
昼夜温差情况
这些信息在“月平均”里全部被平滑掉了。
4. 如何选择合适的分辨率?
选择分辨率取决于你的分析目的:
如果你想研究季节变化、年际趋势,使用 低分辨率(如月/年级) 就很合适。
如果要分析短期变化、异常检测、天气预报,则必须使用 高分辨率(如小时、分钟级) 数据。
如果分辨率过高但你不需要那么多细节,你就可能额外承担存储成本与分析复杂度。
因此,分辨率不是越高越好,而是需要根据任务目标来决定。
五、数据量(Size)
在数据分析中,“数据量”指的是整个数据集的规模,包括记录(observations)的数量以及每条记录所包含的属性(dimensions)。数据量是判断一个数据集是否易于处理、是否适合某些算法的重要指标。随着数据量不断增长,数据处理方式、存储需求以及分析策略也会随之改变。
1. 数据量决定了存储与处理需求
当数据集非常大时,它不仅占用更多的存储空间,也要求更高的计算能力。例如包含数十万甚至数百万条数据的表格,通常无法在普通设备上高效处理。这种情况下,分析者往往需要借助分布式计算平台(如 Hadoop、Spark)或云端解决方案来支撑计算任务。

2. 大规模数据集示例
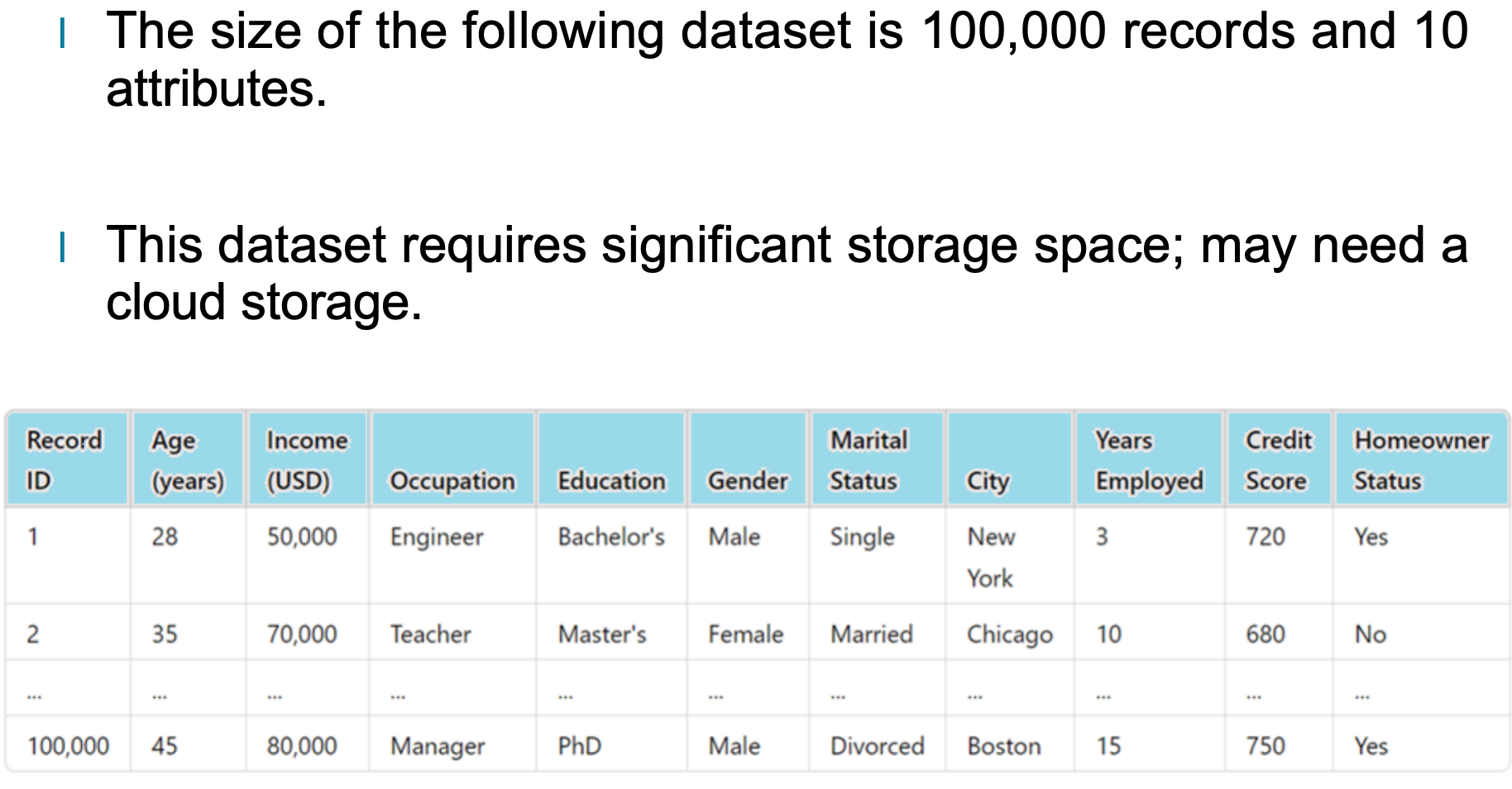
例如下面这个数据集包含 100,000 条记录 和 10 个属性。如此规模的数据集不仅占用大量存储空间,而且单次查询或分析的开销也更高,可能需要云存储或大数据平台协助处理。
3. 面对大数据量的常见策略
因为数据过大可能导致处理缓慢甚至无法在本地设备运行,因此在实际分析中,经常会使用以下策略降低数据规模带来的压力:
使用抽样(Sampling)技术:只从大数据集中抽取具有代表性的一部分进行分析,既能减少计算量,也能得到接近整体情况的结果。
分布式计算框架:如 Spark,可以将大数据拆分到多个节点并行处理,大幅提高效率。
云存储与云计算:通过云服务动态扩展计算资源,应对数据高峰。
六、总结
在数据分析领域,理解数据本身的特征,与掌握分析方法同样重要。本篇文章围绕“数据的重要特征”展开讨论,从维度数量、稀疏性、分辨率到数据规模,逐一分析了这些因素对数据处理和建模策略的影响。
高维数据带来了更广的信息量,但也隐藏着“维度灾难”这样的挑战,需要借助降维技术与更复杂的算法来有效处理。稀疏性提醒我们,数据中的大量零值或缺失值并不总是噪声,而是提示我们在分析时应更多关注非零信息的结构。分辨率则让我们更深刻地认识到数据采集尺度的重要性:不同粒度会导致截然不同的分析结果,选择合适的分辨率是寻找真实模式的关键。至于数据规模,它不仅决定着存储和计算能力的需求,也会进一步影响我们选择怎样的技术框架、硬件条件以及抽样策略。
无论面对的是小型数据集还是海量数据,理解这些特征都能帮助我们在分析之前就做出更合理的判断与规划,为后续建模、可视化和推断奠定扎实基础。掌握数据的性质,本质上就是更好地掌握问题本身。只有理解数据,才能真正从数据中发现价值。