
一、Adam含义
Adam算法是一种高效、常用的神经网络优化器,自动调节学习率让训练更快更稳。
通俗理解:
把它想象成下山找最低谷的人,既记得前面的惯性,又根据最近坡度的陡峭程度实时调整步幅,既不会太快冲过头,也不会太慢磨洋工。
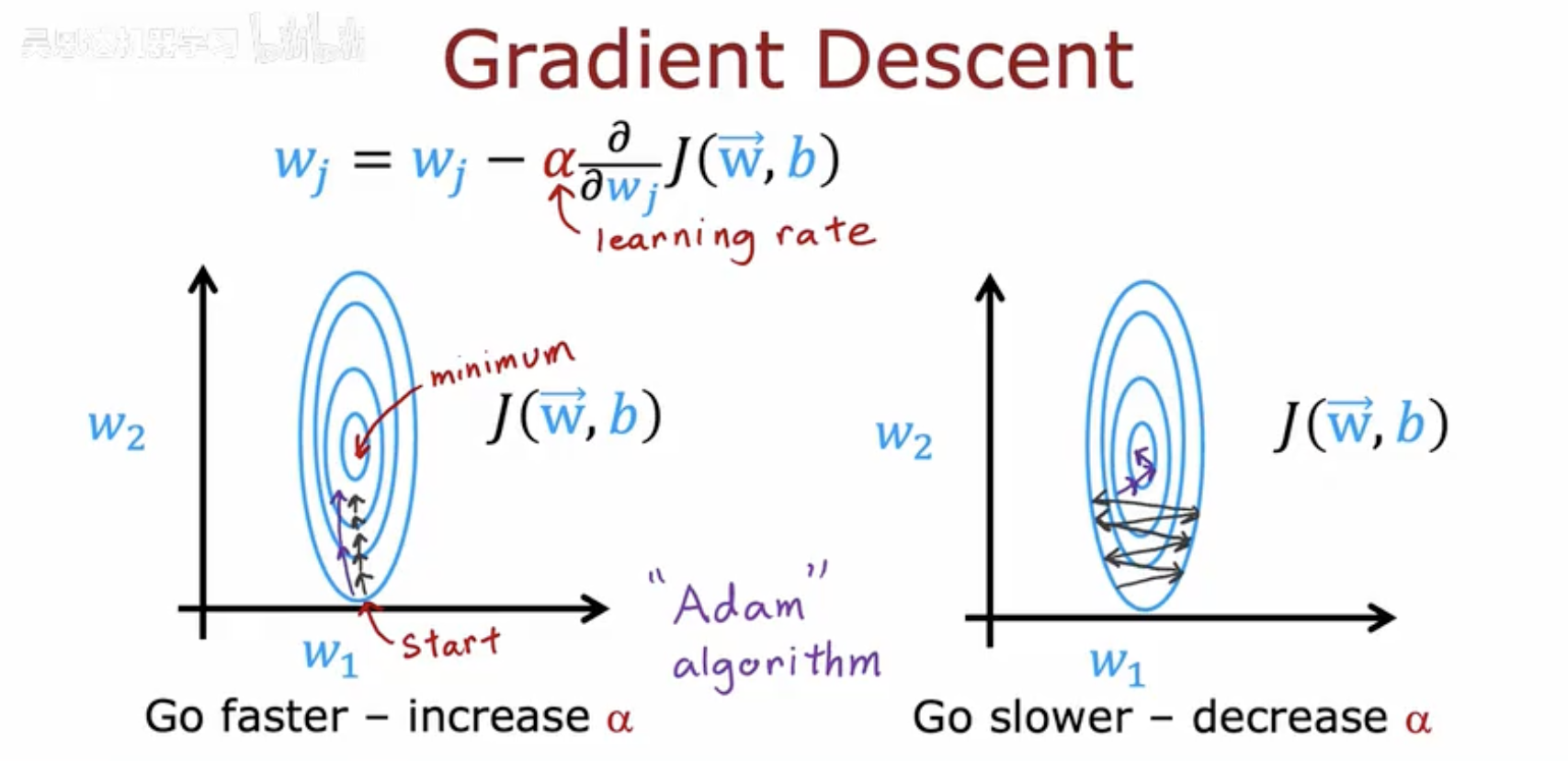
图片把梯度下降比作下山找最低点。
白色曲线是损失函数 J(w,b),横轴是权重 w。
梯度下降从起点 W₁ 出发,沿负梯度一步步往下走。
右侧标着“Go faster – increase α”“Go slower – decrease α”,提示每一步的步长由学习率 α 控制。
最下方用大字标出 “Adam”,表示 Adam 算法就是自动调节这个 α,让下降又快又稳。
二、Adam算法的直观理解

图片展示了Adam算法的核心概念,即自适应矩估计(Adaptive Moment Estimation),并强调了它不是只使用单一的学习率(α)。
自适应矩估计:图片中提到“Adaptive Moment estimation”,这是Adam算法的关键特性。它结合了动量(Momentum)和RMSprop的优点,通过计算梯度的一阶矩(均值)和二阶矩(未中心化的方差)来动态调整每个参数的学习率。
公式:
这些公式展示了如何更新权重 w1 和 w10 以及偏置 b。每个参数都有自己的学习率 α1, α10, α11,这是Adam算法与其他优化算法的主要区别。
学习率的动态调整:Adam算法为每个参数动态调整学习率,这有助于在训练过程中更有效地收敛到最优解。
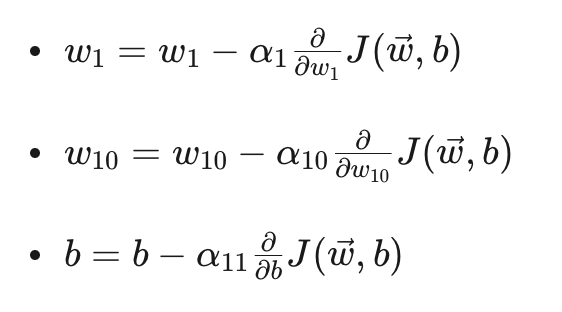
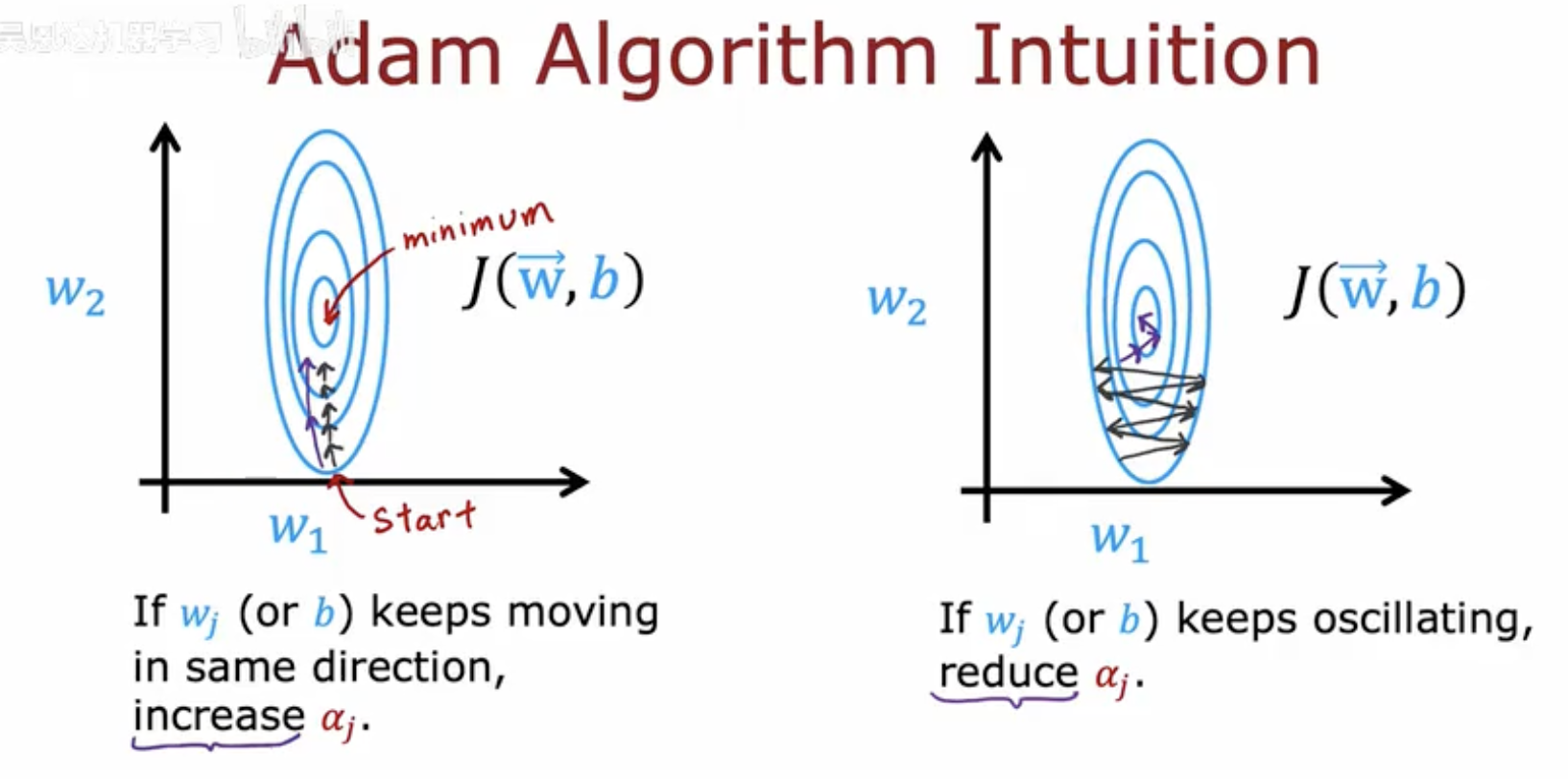
这幅图片展示了Adam算法的直观理解。
左侧图示:
显示了梯度下降法寻找损失函数 J(w,b) 最小值的过程。
指出如果参数 wj(或 b)持续朝相同方向移动,那么学习率 αj 会增加,从而加快收敛速度。
右侧图示:
显示了参数在最小值附近振荡的情况。
指出如果参数 wj(或 b)持续振荡,那么学习率 αj 会减少,以避免过大的步长导致错过最小值。
三、使用Adam优化器的MNIST模型训练示例

这幅图片展示了使用Adam优化器在Keras中构建和训练一个简单的神经网络模型的代码示例。
模型构建:
使用
Sequential模型,包含三个Dense层:第一层有25个神经元,激活函数为
sigmoid。第二层有15个神经元,激活函数为
sigmoid。第三层有10个神经元,激活函数为
linear(输出层)。
编译模型:
使用Adam优化器,学习率设置为
0.001(即10^-3)。损失函数为
SparseCategoricalCrossentropy,适用于多分类问题。
训练模型:
使用
model.fit方法在MNIST数据集上训练模型,训练100个周期(epochs)。