
一、异常检测的定义
异常检测(Anomaly Detection)是一种数据分析技术,它通过分析数据集中的模式和行为,识别出那些与正常模式显著不同的观测值或事件。在实际应用中,它就像是一个敏锐的“守门人”,时刻监视着数据流,寻找那些“不按套路出牌”的数据点。
通俗理解:
在信用卡交易监控中,异常检测可以识别出那些与用户日常消费习惯不符的交易,如在异地或短时间内大额消费,从而及时发现可能的欺诈行为,保护用户的资金安全。它在网络安全、工业生产、医疗诊断等多个领域都有广泛应用,帮助我们提前发现潜在问题,减少损失。
二、异常检测示例图解
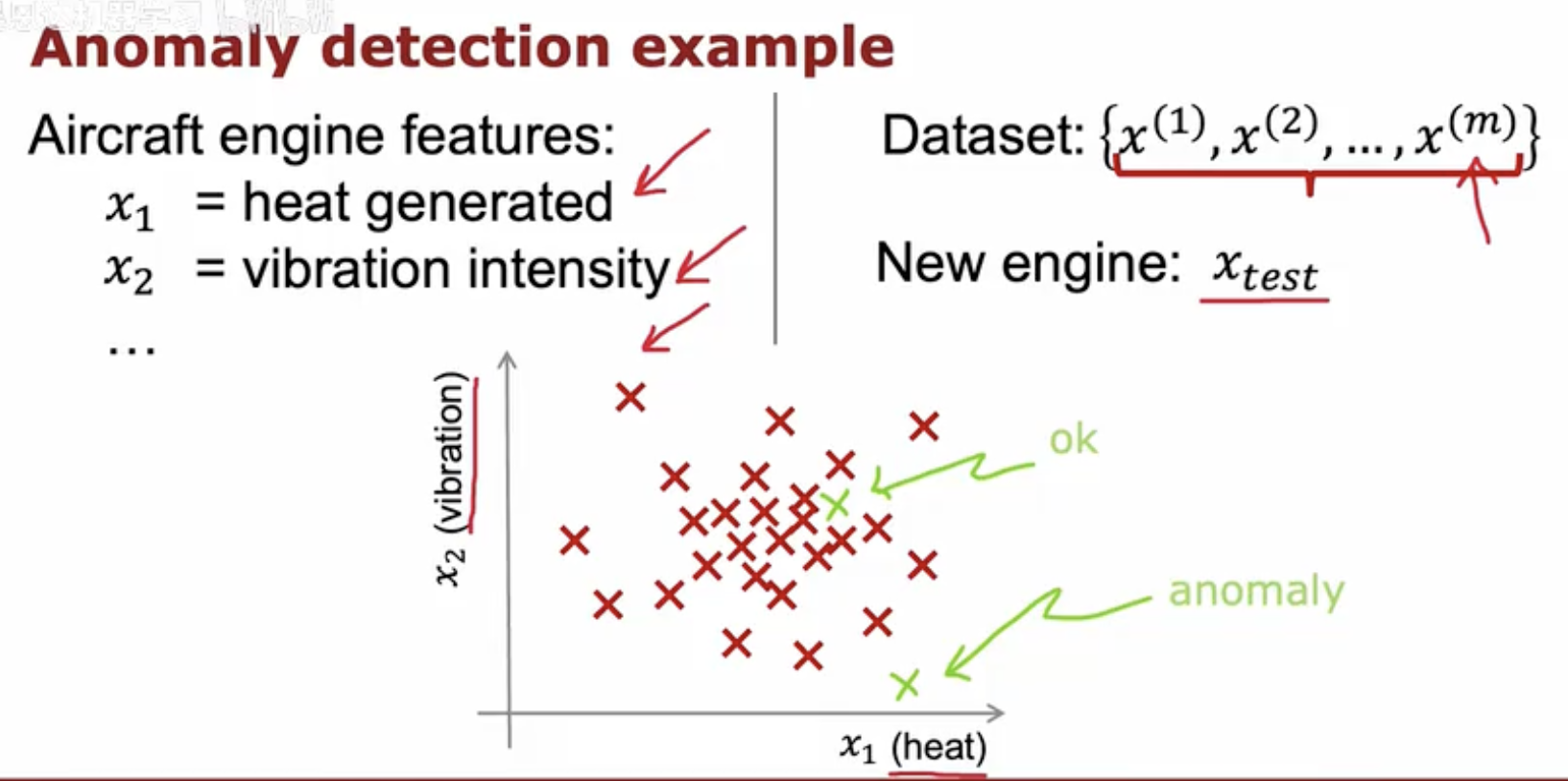
这幅图片展示了一个关于飞机引擎异常检测的例子。图中,横轴 x1 代表引擎产生的热量,纵轴 x2 代表振动强度。图中的“X”标记表示从数据集中收集的飞机引擎特征数据点,这些数据点形成了一个聚类,代表正常运行的引擎特征。
右上角的箭头指向一个新的引擎测试数据点 xtest,这个数据点位于正常数据点聚类之外,被标记为“异常”。这说明该测试引擎在热量和振动强度上与正常引擎有显著差异,可能是一个需要进一步检查的异常情况。通过这种方式,异常检测可以帮助识别出可能存在问题的引擎,从而进行及时的维护或修理。
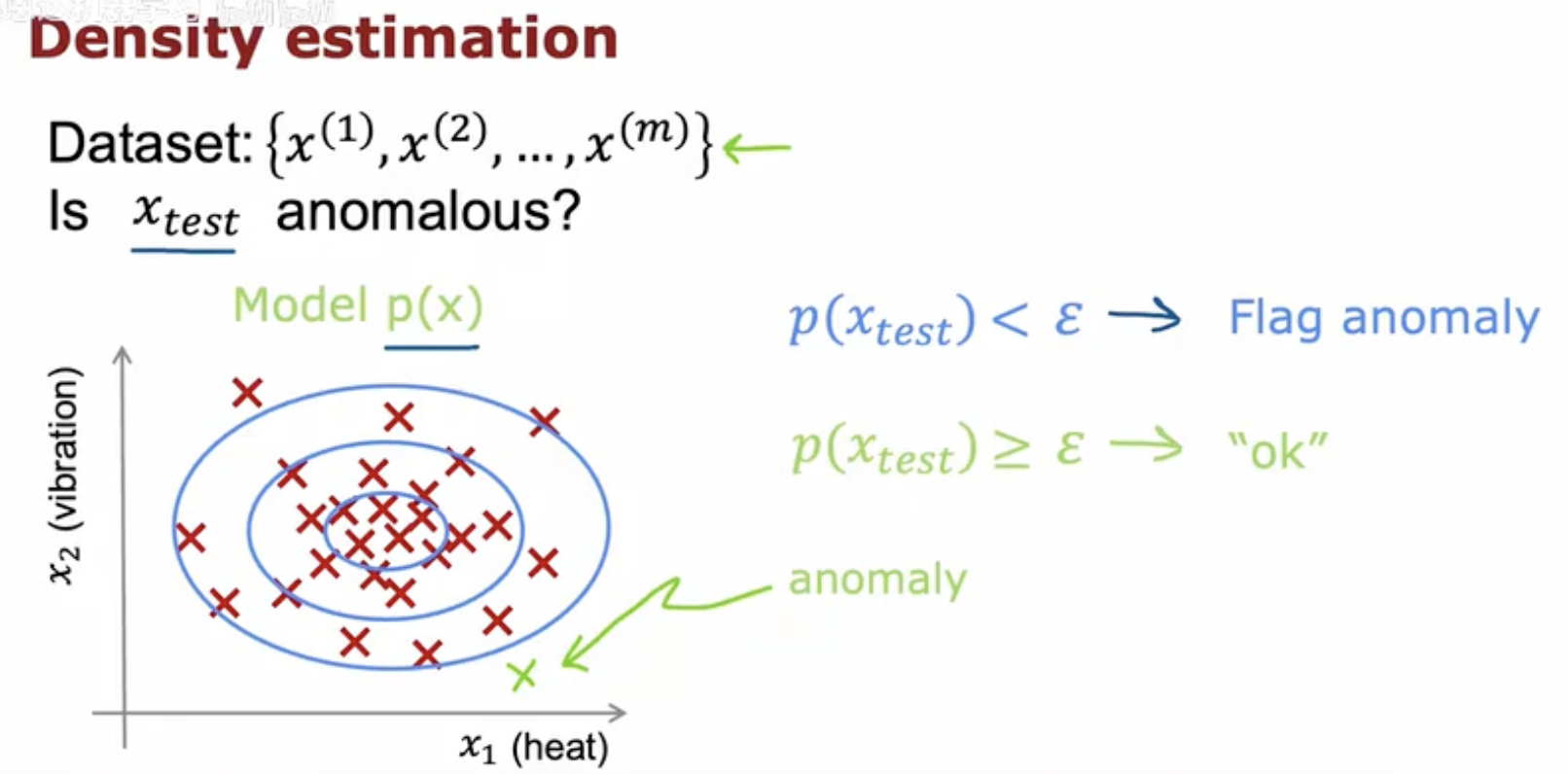
这幅图继续展示了异常检测的过程,特别是如何使用密度估计来确定测试样本 xtest 是否为异常。图中显示了通过模型 p(x) 估计出的数据点在特征空间中的密度分布,用蓝色椭圆表示正常数据点的集中区域。
在这个密度模型中,xtest 位于椭圆之外,表明其在特征空间中的位置与大多数数据点相比是异常的。根据密度估计的结果,如果 p(xtest) 小于设定的阈值 ε,则 xtest 被标记为异常;如果 p(xtest) 大于或等于 ε,则认为 xtest 是正常的。图中用箭头和文字清晰地展示了这一决策过程,其中“Flag anomaly”表示标记异常,“ok”表示正常。这种方法利用了数据点在特征空间中的分布特性来识别异常,是一种有效的异常检测技术。

这幅图提供了两个异常检测的示例。
第一个示例是欺诈检测:
x(i) 表示用户 i 的活动特征。
从数据中建立模型 p(x)。
通过检查 p(x)<ε 来识别不寻常的用户,其中 ε 是一个阈值。
第二个示例是监控数据中心的计算机:
x(i) 表示机器 i 的特征。
特征包括:
x1:内存使用情况。
x2:每秒磁盘访问次数。
x3:CPU负载。
x4:CPU负载/网络流量。
这些特征用于监控和检测异常行为。