
一、聚类的定义
聚类是一种常见的数据分析方法,它通过将数据集中的对象分组,使同一组内的对象相似度高,而不同组之间的对象相似度低。
通俗理解:
就像把一堆不同颜色和形状的玩具进行分类,把红色的玩具放一堆,蓝色的玩具放一堆,形状相似的也归到一起,这样就可以更清晰地了解玩具的组成情况。
在实际应用中,聚类可以帮助我们发现数据中的结构和模式,比如在市场分析中,可以根据消费者的购买行为将他们分为不同的群体,从而制定更有针对性的营销策略;在图像识别中,可以将相似的图像归为一类,以便更好地进行分类和识别。聚类算法有很多种,常见的有K-means算法、层次聚类算法等,它们各有特点和适用场景,可以根据具体的数据和需求进行选择。
二、机器学习中的监督学习与无监督学习
监督学习
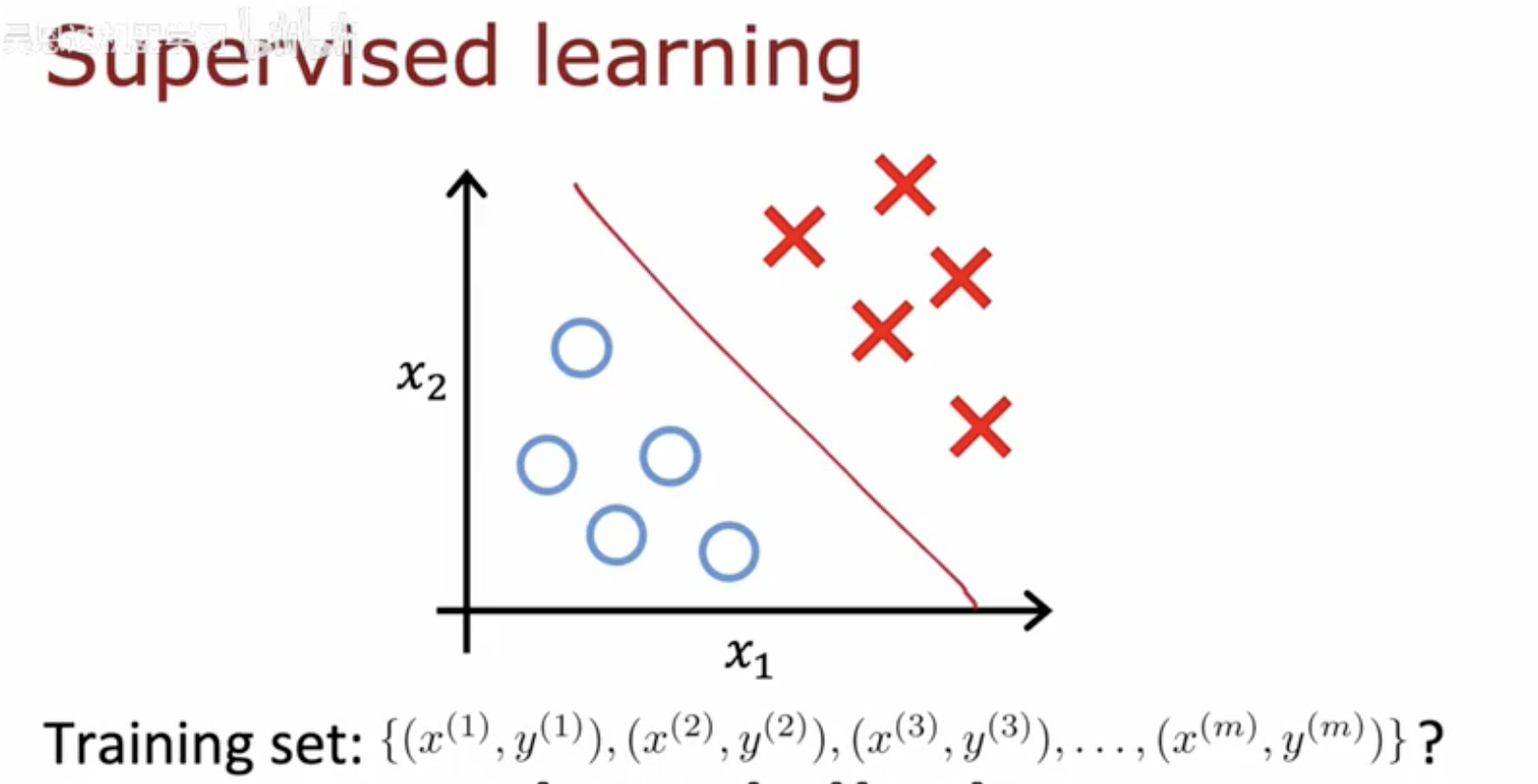
在监督学习中,我们有一个训练集,其中包含了一系列的数据点以及它们对应的标签。这些数据点通常表示为 (x(1),y(1)),(x(2),y(2)),(x(3),y(3)),…,(x(m),y(m)),其中 x(i) 是特征向量,而 y(i) 是对应的标签。监督学习的目标是学习一个模型,该模型能够根据输入的特征向量 x 来预测输出标签 y。
图中展示了一个简单的二维特征空间,其中 x1 和 x2 是特征。图中的蓝色圆圈和红色叉号代表两类不同的数据点,它们分别对应于不同的标签。红色的直线是模型学习到的决策边界,它将特征空间分割成两部分,使得同类的数据点尽可能地被分到同一侧。监督学习算法会尝试找到这样的决策边界,以便能够准确地对新的、未见过的数据点进行分类。
无监督学习
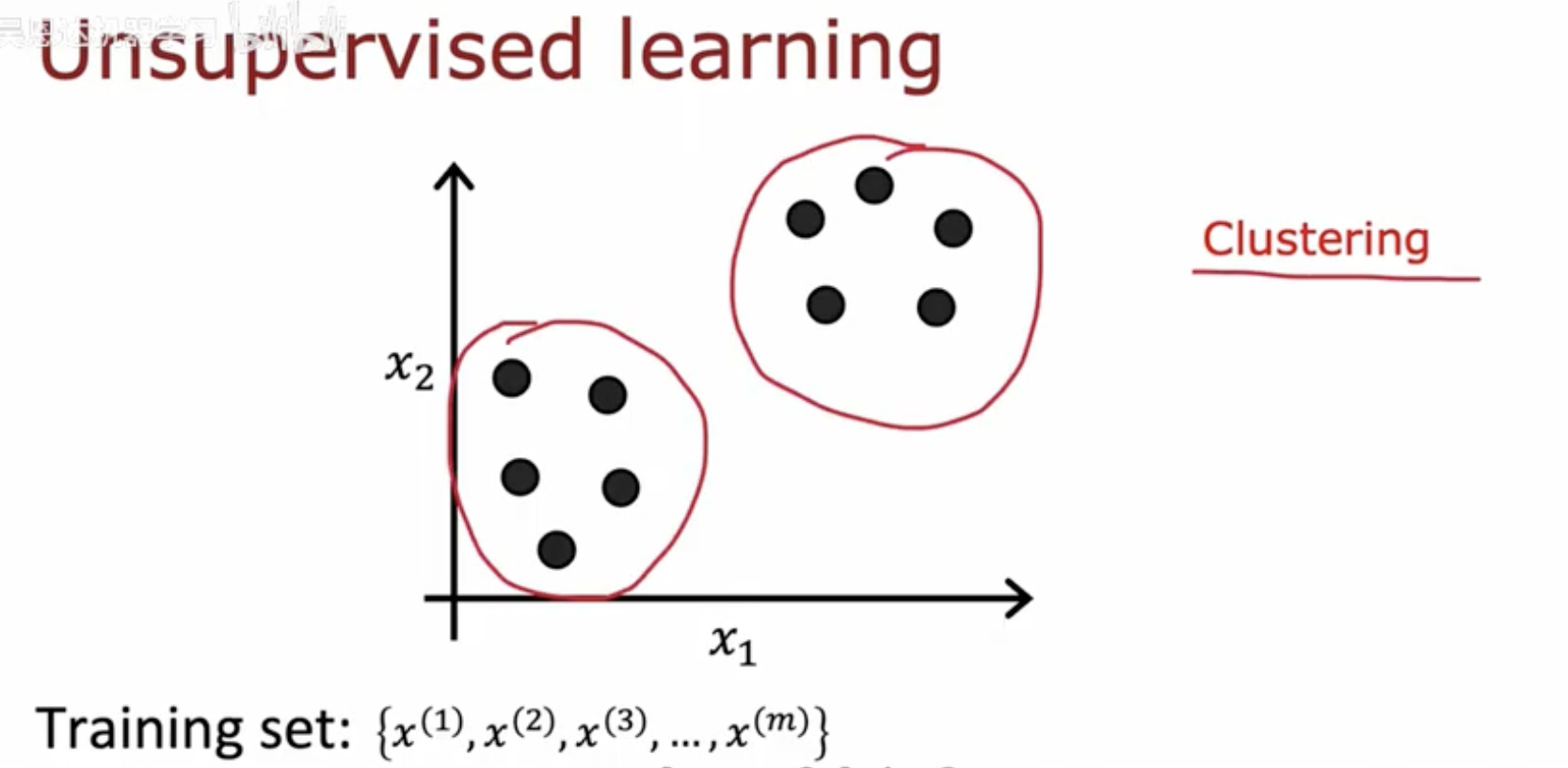
无监督学习与监督学习不同,它不依赖于预先标记的数据。在无监督学习中,我们只有一系列的数据点 x(1),x(2),x(3),…,x(m),没有对应的标签。无监督学习的目标是发现数据中的结构和模式,例如将相似的数据点分组在一起。
图中展示了一个无监督学习的示例,即聚类。在这个例子中,我们有两个不同的聚类,每个聚类用一个红色的椭圆圈出。聚类算法试图将特征空间中相似的数据点分组在一起,形成不同的簇。图中的黑色圆点被分为两个簇,每个簇内的点在特征空间中彼此更接近,而不同簇之间的点则相对较远。聚类可以帮助我们理解数据的内在结构,发现数据中的自然分组,这对于探索性数据分析和数据可视化等任务非常有用。
三、聚类分析的应用领域

新闻分组
左上角的截图显示了新闻文章的分组。聚类分析可以用于将相似的新闻文章归为一类,帮助用户更快地找到他们感兴趣的内容。这种技术可以提高信息检索的效率和相关性。
DNA分析
左下角的图像展示了DNA分析中的聚类应用。通过聚类分析,研究人员可以将具有相似基因表达模式的样本分组,这有助于识别不同疾病或生物特征的模式。
市场细分
右上角的图示说明了市场细分的概念。聚类分析可以帮助企业根据消费者的行为和偏好将市场划分为不同的细分市场,从而制定更有针对性的营销策略。
天文学数据分析
右下角的图像是一张星系的天文照片,展示了聚类分析在天文学数据分析中的应用。通过聚类分析,天文学家可以识别和分类不同的星系类型,研究它们的形成和演化过程。
这些应用展示了聚类分析在多个领域的广泛适用性和重要性。