
一、引言

在机器学习的广阔体系中,分类(Classification)与聚类(Clustering)是两种看似相似但本质不同的任务。二者都涉及对数据进行分组或划分,但在学习方式、目标与所需信息上存在根本差异。
分类是一种有监督学习(Supervised Learning)方法,它依赖于已标注的数据集(Labeled Data)。模型通过学习历史样本的特征与标签之间的映射关系,从而能够对新的样本进行类别预测。典型例子包括垃圾邮件识别、疾病诊断、信用风险预测等任务。
与之相对,聚类是一种无监督学习(Unsupervised Learning)方法,它不需要预先提供类别标签,而是通过算法自动发现数据中的结构或模式。换句话说,聚类的目标不是“预测”类别,而是“发现”潜在的类别。
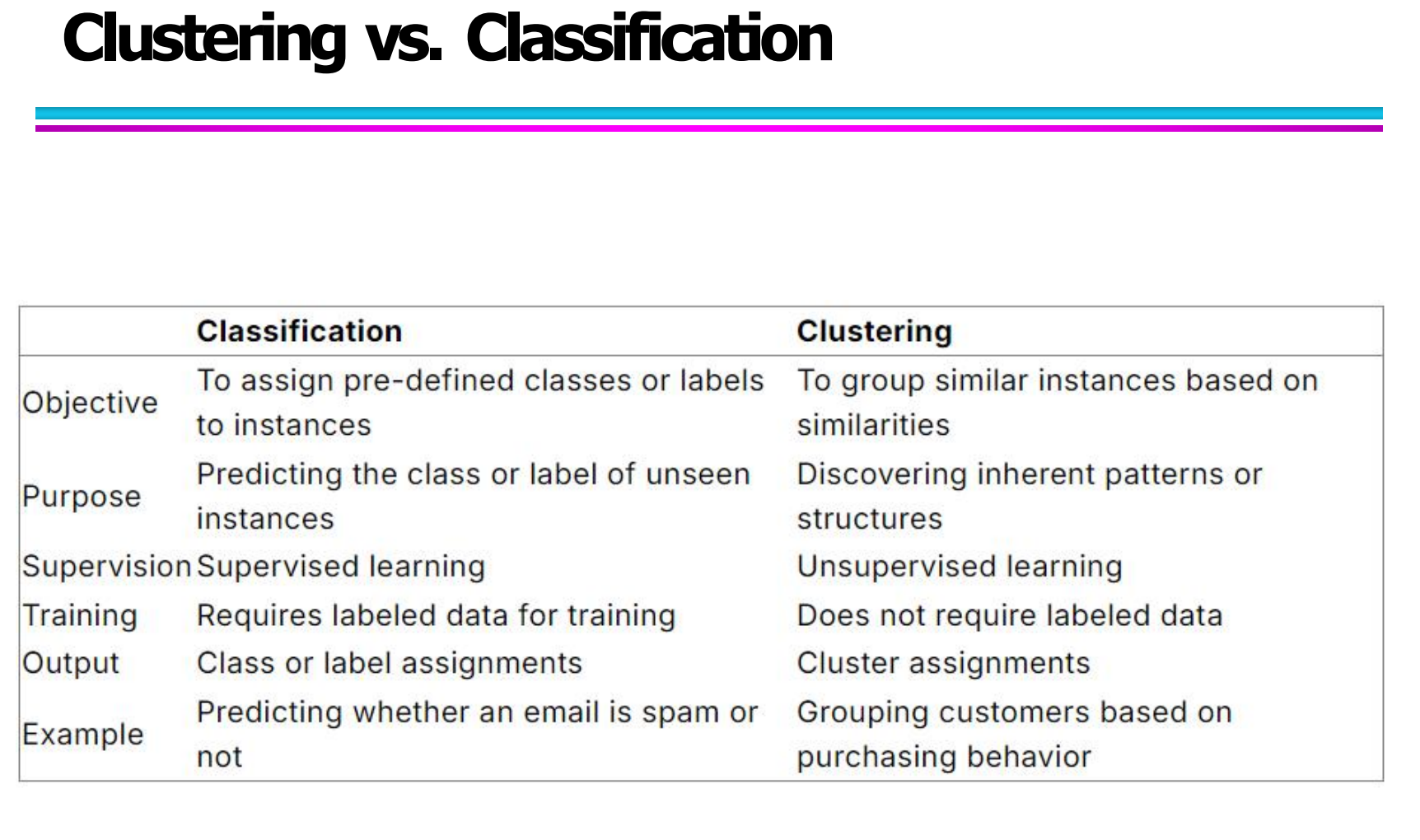
上图清晰展示了两者在学习目标、训练方式与输出结果上的差异:
分类需要人工提供标签,模型负责学习并预测新的样本标签;
聚类则完全依赖数据自身的特征相似性,将相似的数据对象分为同一组。
可以说,分类是“老师指导下的学习”,而聚类更像是“自我发现的过程”。两者虽然方法不同,却都在数据挖掘与智能分析中占据重要位置。
二、工作机制对比

从算法的工作原理来看,分类(Classification)与聚类(Clustering)在数据处理方式与目标逻辑上存在显著区别。
在分类任务中,算法的目标是建立一个能够区分不同类别的决策边界(Decision Boundary)。
假设我们有一组带标签的数据点,如上图所示,其中蓝色圆点代表“儿童”,绿色三角代表“成人”。模型的任务就是找到一条最合适的分界线,使两类样本在这条边界的两侧被准确地区分开。
无论是使用逻辑回归、支持向量机,还是神经网络,本质上都在寻找这样一个函数:
让输入特征(如身高、体重)映射到对应的类别标签。
这意味着分类模型必须依赖于已有的标签信息。它通过“监督”学习来优化决策边界,使预测误差最小。换句话说,分类是“根据已有答案学习如何答题”。
而聚类任务则完全不同。它没有任何标签或先验类别,模型要做的是探索数据的结构。
仍以身高与体重为例,聚类算法(如 K-Means、DBSCAN)会计算样本点之间的距离或相似度,进而自动将相似的数据聚合到一起。例如,K-Means 会通过反复计算“簇心(Cluster Center)”和样本的距离,不断调整分组,直到整体差异最小。
聚类的结果往往揭示了数据中的潜在结构,例如:
某一群顾客在消费习惯上高度相似;
某些病人拥有相似的症状模式;
某些文本自然形成语义上的主题聚类。
与分类不同,聚类的结果是探索性的(Exploratory),而非确定性的。算法不会告诉你“这是儿童还是成人”,而是告诉你“这些人之间的特征非常相似,可能属于同一组”。
因此我们可以总结出两者的关键逻辑差别:
分类:从标签出发 → 学习映射关系 → 预测未知标签。
聚类:从数据出发 → 寻找内部结构 → 发现潜在模式。
三、实际应用
分类与聚类虽然在学习方式上截然不同,但在现实世界中,它们都扮演着极为重要的角色。二者的区别不仅体现在算法上,更体现在使用场景与目标任务上。
1. 分类的应用场景(Applications of Classification)
分类算法在生活与工业中几乎无处不在,它适用于那些数据标签明确且可枚举的任务。
常见应用包括:
垃圾邮件识别(Spam Detection)
邮件系统通过分析邮件内容、发件人、关键词等特征,将邮件划分为“正常邮件”或“垃圾邮件”。
模型的训练依赖大量已标注样本,这正体现了有监督学习的本质。信用风险评估(Credit Scoring)
银行或金融机构通过客户的收入、资产、还款记录等特征来判断其是否属于“高风险”或“低风险”用户,从而决定是否放贷。图像与语音识别(Image & Speech Recognition)
深度学习推动了分类算法在多媒体领域的爆发。模型可以区分图像中的猫与狗、识别语音中的不同指令,甚至区分医疗影像中的良性与恶性病变。医疗诊断与疾病分类(Medical Diagnosis)
医学图像分析模型可根据影像特征自动判定疾病类型,帮助医生提高诊断效率。
2. 聚类的应用场景(Applications of Clustering)
聚类的优势在于“探索未知结构”,因此更适用于没有明确标签或需要发现潜在规律的任务。
典型应用包括:
客户分群(Customer Segmentation)
电商或营销领域常利用聚类算法分析客户的购物行为、消费频率、价格敏感度等,从而自动形成“高价值客户”“潜力客户”“价格敏感客户”等群体,为精准营销提供依据。文本主题发现(Topic Discovery)
在自然语言处理中,聚类可用于发现新闻报道或社交媒体内容中的主题结构。例如,算法能自动识别“体育”“政治”“科技”等主题群组,而无需人工标注。异常检测(Anomaly Detection)
聚类还可辅助检测异常样本:当某些数据点远离所有簇中心时,它们可能代表欺诈交易、系统故障或安全入侵。图像压缩与特征提取(Image Compression & Feature Extraction)
在图像处理中,聚类算法可用于像素分组或特征提取,例如使用 K-Means 对颜色分布进行简化,以减少数据维度或压缩存储空间。


四、总结
通过前面的分析可以看出,分类(Classification)与聚类(Clustering)虽然都在处理“如何划分数据”的问题,但它们在学习方式、输入信息和应用目的上存在根本性差别。
分类是一种典型的有监督学习(Supervised Learning)。它依赖于带标签的数据,模型在训练阶段“学习”特征与类别之间的对应关系,目标是对新的样本进行准确预测。它回答的问题是:“这个样本属于哪一类?”——因此,分类的本质是预测与判断。
聚类则属于无监督学习(Unsupervised Learning)。它不需要任何人工标签,而是通过数据本身的相似性来自动形成分组,寻找隐藏在数据内部的结构。它回答的问题是:“这些样本之间有什么共同点?”——因此,聚类的本质是探索与发现。
从结果来看:
分类的输出是预定义的标签集合,如“是/否”“高/中/低风险”等;
聚类的输出是算法自动形成的簇结构,簇的数量与边界往往由数据分布决定。
从思维角度来看:
分类是从“已知”出发,用过去的数据推测未来;
聚类是从“未知”出发,用数据的结构去理解世界。
在实践中,分类与聚类常常结合使用。例如,在客户分析中,企业先利用聚类算法发现客户的潜在分组模式,再通过分类模型识别新客户属于哪个群体,从而实现自动化的群体归属预测。
总而言之,分类与聚类分别代表了监督学习与无监督学习的两种核心思维。前者帮助我们利用已有知识做出决策,后者则让我们从数据中发现新知识。二者相辅相成,共同构成了机器学习中最基础、也是最重要的分析框架。