
第一节:重新定义“深度”——从一维到二维的跨越
在谈论深度学习时,我们经常听到“深层网络”这个词。但在循环神经网络(RNN)的语境下,“深度”其实有两个截然不同的维度。
RNN 的第一种深度:时间轴上的展开
即便是一个最简单的单层 RNN,它本身也已经是“深”的。 当我们处理一个长序列(比如一句话或一段音频)时,RNN 会随着时间的推移不断“展开”(Unroll)。每一个时间步的隐藏状态都依赖于前一个时间步,这意味着信息在时间轴上穿梭了数十次甚至上百次。
这种深度解决了时序依赖的问题,让模型能够“记住”过去发生的事情。
RNN 的第二种深度:空间轴上的堆叠
然而,仅仅在时间上延伸是不够的。为了让网络能够捕捉到更复杂的特征,我们需要在另一个维度上加深它——这就是多层 RNN(Multi-layer RNNs),也被形象地称为堆叠 RNN(Stacked RNNs)。
单层 RNN:就像是一个通才,试图在一个维度内同时处理原始输入、语法结构和高层语义。
多层 RNN:通过将多个 RNN 层垂直叠加,我们让模型拥有了“分工”的能力。
这种结构允许网络构建分层表示(Hierarchical Representations):
底层 RNN(Lower RNNs):负责提取低级特征(例如词与词之间的基本连接)。
高层 RNN(Higher RNNs):在底层特征的基础上,进一步提取高级特征(例如整个句子的情感倾向或逻辑意图)。

第二节:解剖多层 RNN
在第一节中,我们建立了“堆叠”的概念。现在,让我们对准这个堆叠结构,看看当一个序列(比如一个句子)输入时,其内部到底发生了什么。
1. 核心流动:从 hi 到 xi+1
理解多层 RNN 的关键在于四个字:层间传递。
在一个标准的单层 RNN 中,每个时间步的输入是 xt,输出是隐藏状态 ht(这个 ht 也会传递给下一个时间步)。
在多层 RNN 中,这个逻辑发生了一个优雅的垂直延伸:
第 1 层:它的输入是原始的外部输入序列 X(例如一个句子的所有词)。这一层计算出自己的隐藏状态序列 H1。
第 2 层:它的输入不再是原始序列 X,而是第 1 层的隐藏状态序列 H1。第二层对这些已经经过处理的信息再次进行循环处理,计算出自己的隐藏状态序列 H2。
第 i+1 层:以此类推,任何一个中间层(第 i+1 层)的输入,都是它直接下层(第 i 层)在同一时间步产生的隐藏状态。
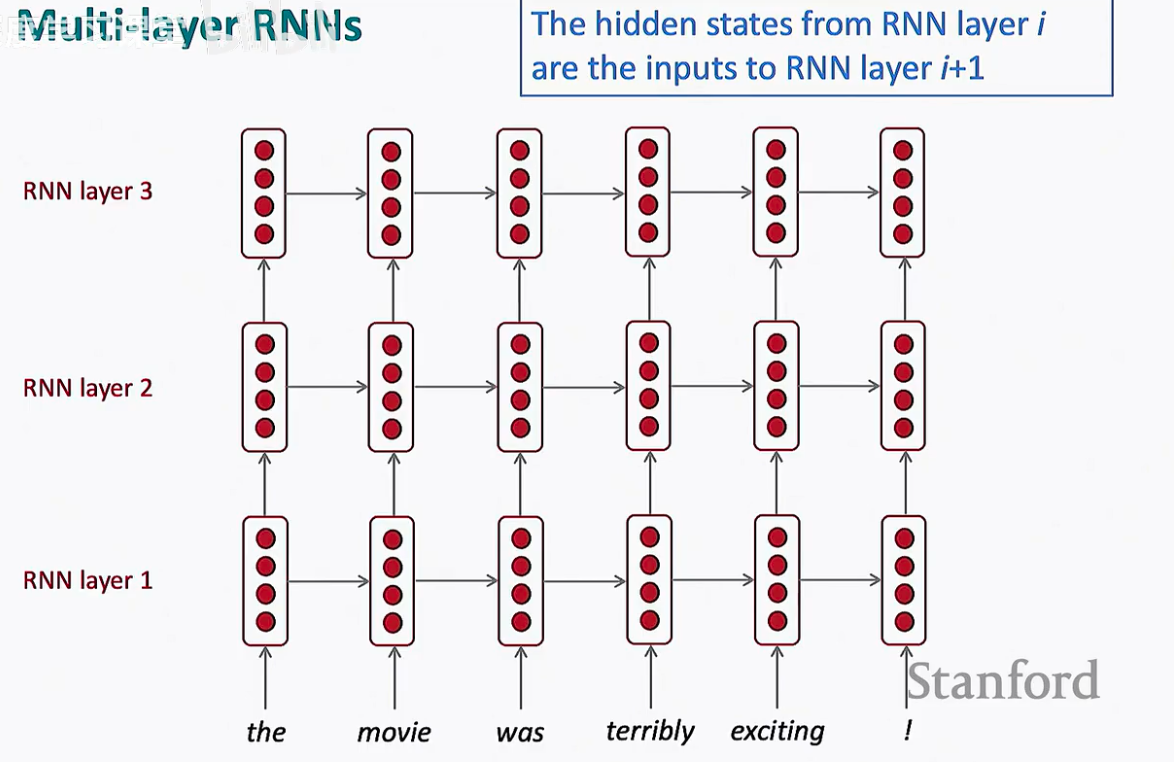
水平箭头:代表同一层内的信息跨时间传递(记住过去)。
垂直箭头:代表信息从低层传向高层(深化理解)。
2. 特征分层的技术实现
通过这种垂直传递,多层 RNN 实现了一个非常强大的功能:特征的分层计算。
正如我们在引言中提到的:
底层(RNN layer 1):它最接近原始数据,其计算更偏向于低级特征。比如在 NLP 中,layer 1 可能更多地捕捉词法信息(词的类型、词形变化)。
高层(如 RNN layer 3):它的输入已经是经过底层初步抽象处理的信息。它能够站在更高的视角,整合更长距离的信息,从而计算出高级特征(例如复杂的句法结构、语义倾向、上下文意图)。
这种设计不仅更符合人类认知世界的逻辑(从具体到抽象),也在数学上被证明具有更强的表达能力,能够解决单层网络无法胜任的复杂问题。
第三节:实战中的多层 RNN
在理解了多层 RNN 的架构后,一个自然而然的问题是:既然多层更好,那是不是层数越多越好? 在实际应用中,答案往往是需要“适度”。
1. 性能的权衡:为什么不追求“无限深”?
虽然增加层数能让网络计算出更复杂的表示,效果通常优于单纯增加单层隐藏层的维度,但 RNN 的深度受到两个主要因素的制约:
计算成本:RNN 的序列依赖特性使得它难以并行化。增加层数会成倍增加计算开销和推理延迟。
训练难度:随着层数加深,梯度在跨层传递时也会面临消失或爆炸的问题,导致模型难以收敛。
2. 实战中的经验值(以神经机器翻译 NMT 为例)
根据 Britz et al. (2017) 的研究,在处理复杂的翻译任务时,研究者们总结出了一些黄金法则:
Encoder(编码器):通常 2 到 4 层 是最佳平衡点。
Decoder(解码器):通常 4 层 的效果最好。
边际递减效应:通常从 1 层增加到 2 层会有显著的性能提升;从 2 层增加到 3 层可能有小幅改善;但再往后增加,提升往往微乎其微,甚至可能因为过拟合而导致性能下降。

3. 跳跃连接(Skip-connections)
如果你确实需要训练更深层的 RNN(例如 8 层甚至更多),简单的堆叠往往会失效。这时,我们需要引入跳跃连接(Skip-connections)或稠密连接(Dense-connections)。
这种技术允许信息绕过某些中间层,直接从低层传递到高层。这不仅能有效缓解梯度消失问题,还能让高层模型直接观察到原始输入特征,从而保持信息的完整性。
4. 从 RNN 到 Transformer
尽管多层 RNN 在很多任务中表现卓越,但它的深度通常止步于 4-8 层。相比之下,如今主流的 Transformer模型(如 BERT)通常拥有 12 层甚至 24 层。
为什么 Transformer 能做得这么深?这主要归功于它抛弃了时序递归,转而采用全注意力机制,并配合了极其强大的残差连接(Residual Connections)。在接下来的学习中,我们会发现 Transformer 实际上是将这种“多层堆叠”的思想推向了极致。