
第一节:引言
在自然语言处理(NLP)的早期,我们习惯于使用标准的 RNN、LSTM 或 GRU。这些模型都有一个共同的特点:它们是“因果”的(Causal)。这意味着在处理每一个词(x(t))时,模型只能看到该词及其之前的上下文。
1.1 左侧上下文的局限性
想象一下,我们正在训练一个情感分类模型来处理电影评论。当模型读到下面这句话的中间部分时:
“The movie was terribly...”
在标准的单向 RNN 中,此时生成的隐状态(Hidden State)仅包含来自左侧的信息(Left Context)。对于“terribly”这个词,模型捕获到的语义通常是“极度地”、“糟糕地”。如果模型在此处停止,它很可能会给出一个负面的情感预测。
1.2 当“右侧”改变了一切
然而,当我们读完整个句子:
“The movie was terribly exciting!”
情况发生了逆转。这里的“terribly”并不是修饰“糟糕”,而是作为副词增强了“exciting(兴奋/精彩)”的程度。
这就是单向 RNN 的痛点所在:当前的词义往往是由它“身后”的词(Right Context)决定的。 在这个例子中,“exciting”不仅修改了“terribly”的情感极性,还决定了整个句子的最终走向。
1.3 什么是 Contextual Representation?
为了准确理解每一个词,我们需要一种上下文表示(Contextual Representation)。
单向表示: 只包含 x(1) 到 x(t) 的信息。
理想表示: 应该同时包含该词的“前世”(左侧)和“今生”(右侧)。
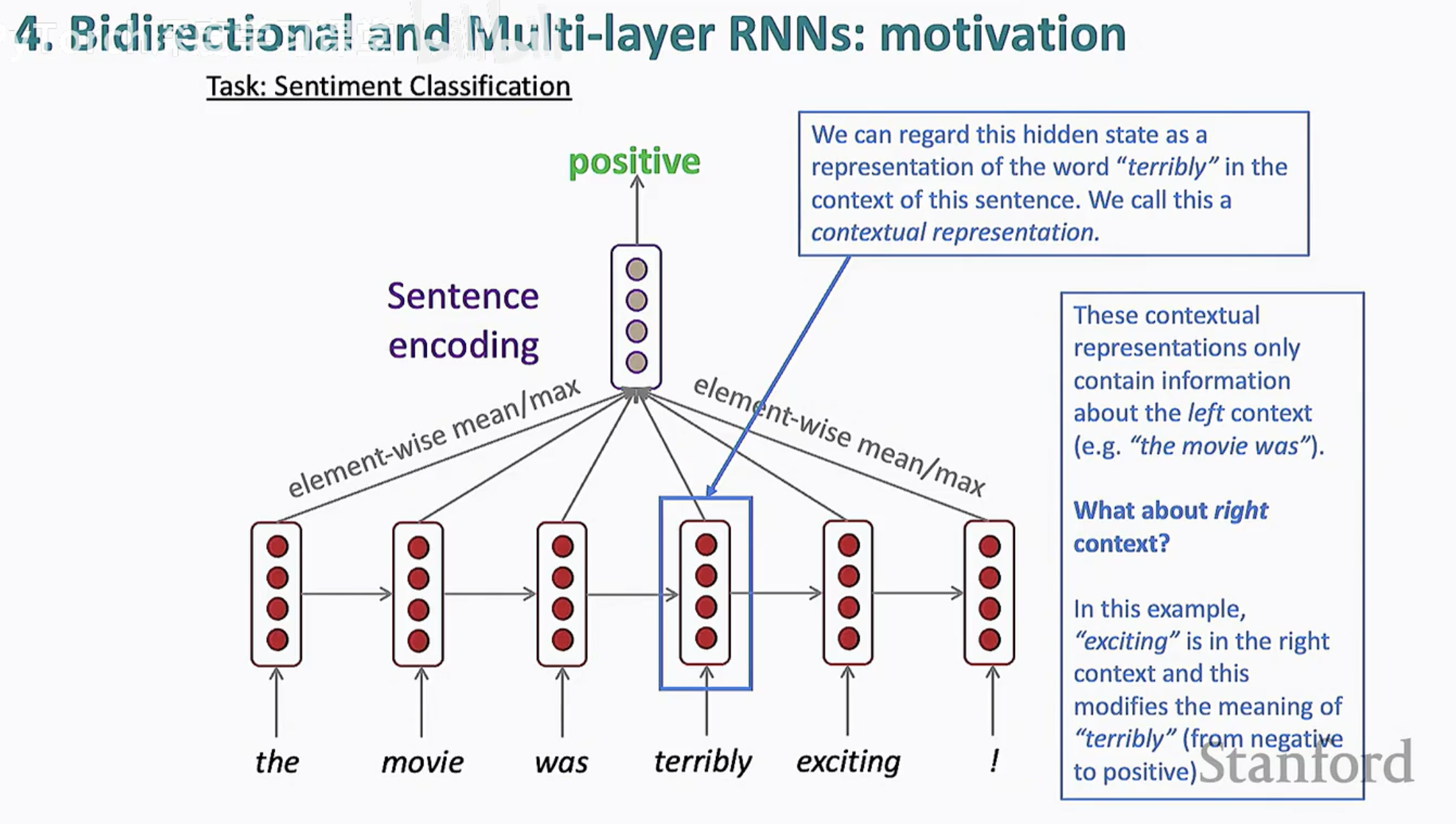
正如上图所示,如果我们希望对“terribly”进行句子编码(Sentence Encoding),仅仅依靠 element-wise mean/max 聚合左侧信息是不够的。我们需要一种机制,让模型能“预知未来”。
第二节:Bi-RNN的核心动机
在上一节中,我们看到了单向 RNN 的窘境:它像是一个只能回头看、不能向前看的旅人。为了解决这个问题,双向循环神经网络(Bi-RNN)提出了一个直观且强力的方案——既然“未来”的信息很重要,那我们就从未来“走回来”。
2.1 引入右侧上下文 (Right Context)
在处理句子 The movie was terribly exciting ! 时,我们不仅需要知道“terribly”之前发生了什么,更迫切地需要知道它之后跟着什么。
左侧上下文 (Left Context): 提供了
the movie was的背景。右侧上下文 (Right Context): 提供了
exciting !的关键补充。
只有将这两部分信息融合,我们对“terribly”这个词的理解才是完整的、具有上下文感知力(Context-aware)的。
2.2 双向流动的机制
Bi-RNN 的核心逻辑是将序列处理拆分为两个独立的方向:
前向传播 (Forward Pass): 按照正常的顺序(从左到右)读取单词。它负责收集词汇的“历史”信息。
后向传播 (Backward Pass): 按照相反的顺序(从右到左)读取单词。它负责收集词汇的“未来”信息。
当我们站在中间的词 terribly 这一步时,前向 RNN 告诉我们它前面有部电影,而后向 RNN 则告诉我们后面跟着“令人兴奋”这个词。

2.3 状态合并:1 + 1 > 2
在这张图中,你会发现每一个时间步(Timestep)现在都拥有了两个隐状态:一个红色的(前向)和一个绿色的(后向)。
Bi-RNN 的精妙之处在于将这两个向量进行拼接(Concatenation)。这个合并后的长向量(图中顶部的长方体)就是该词最终的 Contextual Representation。
核心逻辑: > 拼接后的隐藏状态 h(t) = [前向状态 ; 后向状态]
它不再是一个单纯的特征向量,而是一个同时“读过全文”的深度表示。
第三节:Bi-RNN 的架构与工作原理
在上一节,我们从概念上理解了 Bi-RNN 是通过“两条路”并行运作来实现双向性的。现在,让我们通过数学公式和更精细的图示,来彻底搞懂在每一个时间步 t,模型内部究竟发生了什么。

如上图所示,Bi-RNN 的核心在于“两层独立的隐状态”和“一次状态拼接”。
3.1 前向 RNN (Forward RNN):捕获历史
前向层 RNNFW 按照标准 RNN 的逻辑运作,它接收当前的输入 x(t),并结合上一个时间步(t-1)传来的隐状态 h(t-1) 来生成当前的隐状态。
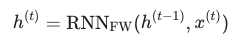
关键点: 公式中的箭头(->)表示这是一个因果(Causal)方向。h(t)包含的是 x(1) 到 x(t) 的左侧上下文信息。
3.2 后向 RNN (Backward RNN):预知未来
这是 Bi-RNN 的灵魂所在。后向层 RNNBW 拥有自己独立的参数。虽然它的输入也是 x(t),但它接收的是下一个时间步(t+1)传来的隐状态。
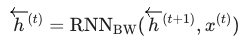
关键点: 公式中的反向箭头(<-)表示数据流向是从句子的末尾到开头。这意味着在计算 <-h(t) 时,模型实际上已经处理完了 x(t) 之后的所有单词(即右侧上下文)。
3.3 最终表示:隐状态的拼接
在时间步 t,我们得到了两个分别代表“过去”和“未来”的特征向量:h(t) 和 <-h(t)。
Bi-RNN 最终输出的上下文表示 h(t),是将这两个向量进行简单的拼接(Concatenation):
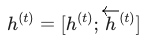
核心逻辑:
这是一个“状态级”的融合,而不是简单的相加或平均。
前向层计算 h(t)。
后向层计算 <-h(t)(这两个计算可以并行,因为它们互不依赖)。
将它们对齐拼接。
此时得到的 h(t),就是一个真正读懂了全文的上下文感知向量。
第四节:实践中的 Bi-RNN:从局部到全局
在理解了单个时间步的数学原理后,我们需要跳出来,观察 Bi-RNN 在处理整个序列时的“全景图”。为了方便工程实现和架构设计,研究者通常会使用一种更简洁的表示方法。
4.1 简化图示
在很多学术论文和技术文档中,你不会看到复杂的双层结构,而是看到如下面这张图所示的简洁表达:
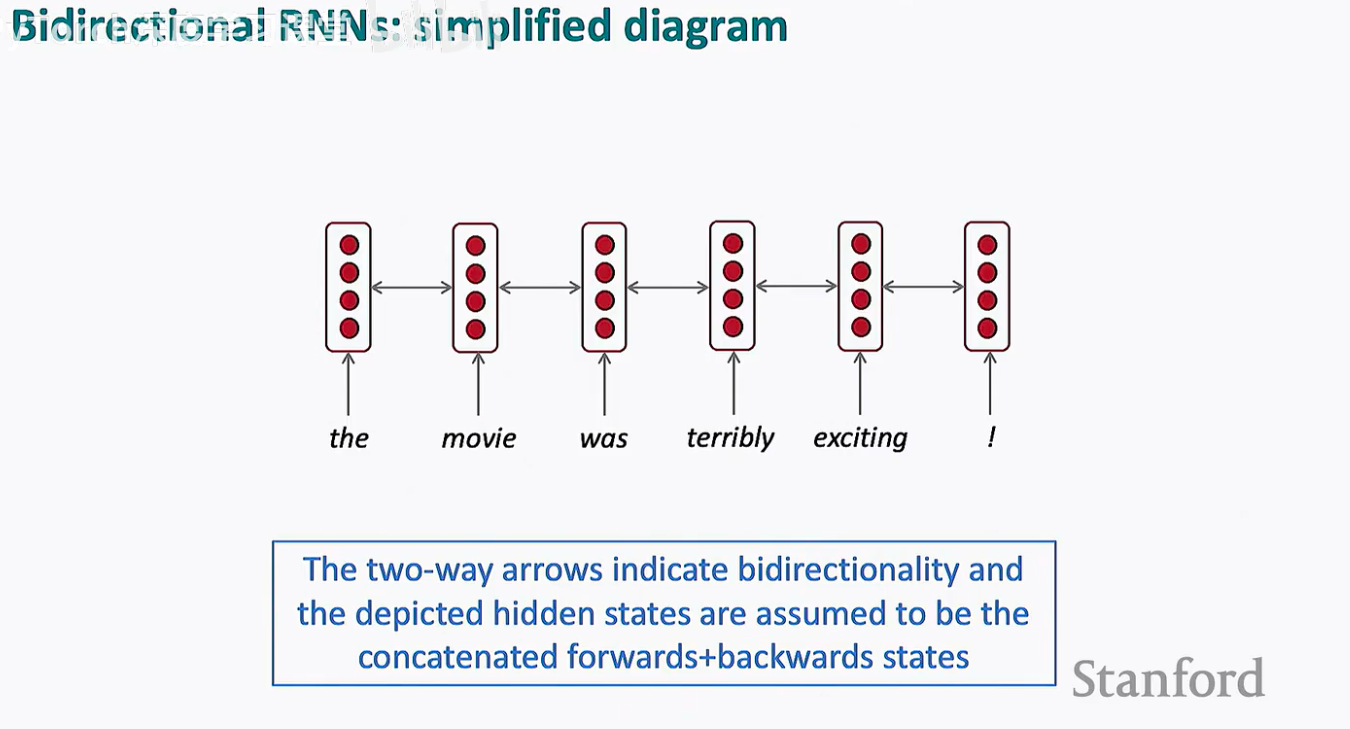
在这张简化图中,每个隐藏单元之间使用了双向箭头。这传达了两个核心信息:
信息的双向流动: 每个词的表示都深受其左右邻居的影响。
隐藏状态的复合性: 图中显示的每一个红色方块,实际上都默认是前向状态与后向状态拼接后的结果。
4.2 任务流:以情感分类为例
让我们回到最初的案例:判断 The movie was terribly exciting ! 的情感。Bi-RNN 的处理流程如下:
输入层: 将每个单词(或 Token)转化为词嵌入向量。
双向处理层: * 前向 RNN 从
The读到!。后向 RNN 从
!读到The。
特征融合: 在每个位置 t,将两路信息拼接,得到该位置的上下文向量。
池化/聚合 (Pooling): * 为了得到整个句子的表示(Sentence Encoding),我们通常对所有位置的 h(t) 进行 element-wise mean(求平均)或 max-pooling(求最大值)。
这意味着我们不仅利用了双向性来理解词义,还通过聚合操作把全句的信息浓缩到了一个向量中。
输出层: 将聚合后的向量输入分类器,最终输出分类结果(例如:Positive)。
4.3 为什么这种架构更鲁棒?
相比于单向模型,Bi-RNN 在实践中展示了极强的语义捕捉能力。它不再寄希望于模型在读到句尾时还能记住句首的所有细节,而是让每个词在生成时就“顺便”参考了全篇。
这种“全局视野”使得模型在处理长难句、多重否定或修饰语较多的句子时,准确率有了显著的提升。
第五节:Bi-RNN 的应用边界与未来
虽然 Bi-RNN 在情感分类、命名实体识别(NER)等任务中表现优异,但它并非万能药。理解它的局限性,才能明白为什么 NLP 领域后来会进化出 BERT 这样划时代模型。
5.1 先决条件:必须“预知未来”
Bi-RNN 有一个非常硬性的前提:在计算任何一个位置的隐状态之前,你必须已经拥有了整个输入序列。

如上图所示,Bi-RNN 仅适用于你能“看到全文”的情况。这在自然语言编码(Encoding)任务中非常强大,因为你可以一次性把整句话输入模型。
5.2 为什么 Bi-RNN 不能做“语言模型”?
语言模型(Language Modeling, LM)的核心任务是预测下一个词。
在生成文本时,我们是逐字产生的:先生成第一个词,再根据第一个词生成第二个词……
矛盾点: 在生成第 t 个词时,第 t+1 个及以后的词根本还没有产生!
由于 Backward RNN 需要从右往左读取信息,而在生成任务中,“右侧”的词尚未存在,因此 Bi-RNN 无法直接应用于标准的自回归文本生成任务。
5.3 承前启后:迈向 BERT 时代
尽管有上述限制,Bi-RNN 证明了一个真理:双向上下文(Bidirectionality)是极度强大的。
这种思想直接启发了后来的 BERT (Bidirectional Encoder Representations from Transformers)。虽然 BERT 抛弃了循环神经网络(RNN)的结构,转而使用 Transformer 架构,但它继承并弘扬了 Bi-RNN 的灵魂——通过特殊的“掩码(Masking)”机制,让模型在预训练阶段就学会同时利用左右两侧的信息。
总结:
如果你需要对已有的文本进行深度理解(如分类、翻译的编码端、序列标注),请默认使用双向结构。
如果你需要预测未来(如对话生成、续写文章),则必须回归单向(或使用特定的解码器结构)。