

该论文发表在 ICNLSP 2025(第 8 届国际自然语言与语音处理会议,The 8th International Conference on Natural Language and Speech Processing)。
1. 引言
在快速发展的自然语言处理(NLP)时代,大型语言模型(LLMs)正渗透到几乎所有应用场景和领域。在多数任务中,它们展现出强大的生成能力与良好的文本理解力。然而在医疗等关键领域,这些模型仍存在产生幻觉的倾向。当前LLM通常依据通用基准进行评估,其对医疗领域的评估往往存在不足。自动事实核查领域的尖端技术包括基于自然语言推理(NLI)结合DeBERTa模型,或通过链式推理(CoT) 以大型语言模型作为裁决者。鉴于在医学等关键领域中事实准确性的重要性,采用多种技术进行事实核查具有重要意义。因此提出"一致投票"机制:只有当两种技术均支持某原子事实时,才认定该事实准确无误。
幻觉通常可分为输入冲突型、上下文冲突型和事实冲突型。本论文研究重点在于事实冲突型幻觉,即输出中的事实与世界知识相矛盾的情况。此外 ,本论文工作基于CoT的事实核查方法FActScore。 对其进行改造以支持用户提供的锚定文档,(也就是说把FActScore方法改造成不仅可以外在查询,也可以把上传的特定文档里查询)使其适用于RAG和摘要生成等任务。提出自动事实核查基准FActBench 1,具有以下贡献:
• 采用原子事实对六种当代大型语言模型进行事实核查,涵盖四类生成任务:文本摘要、通俗摘要、检索增强生成(RAG)及开放式生成。
• 实验中对比了内在(依据验证文档)与外在(维基百科数据集)两种事实核查技术。
• 最终预测采用领域专家评估作为基准,同时评估了自然语言推理(NLI)、知识转移(CoT)及一致性投票(UnVot)三种方法。
2. 相关工作
幻觉是自然语言生成(NLG)任务中常见的问题,例如抽象化生成、摘要生成、生成式问答或对话生成。幻觉检测与模型输出事实性评估问题密切相关。 可通过分析模型逻辑值的不确定性或借助外部知识库对模型输出进行事实核查来检测幻觉现象。
近期研究:
通过问答(QA)或自然语言推理(NLI)方法进行评估。
最新方法通过向大型语言模型(LLMs)直接查询评分来实现评估(如G-Eval)。
基于原子事实的真实性评估生成文本(如 FActScore)。
无需外部知识的事实核查方法,通过利用词元级不确定性识别输出中潜在事实错误的生成段落 。
引入Provenance技术,利用NLI模型结合上下文验证RAG输出的事实准确性。
FactCHD基准测试框架,用于检测通用领域、科学领域、健康领域及COVID-19领域中存在事实冲突的幻觉文本。
3. FActBench:基准测试
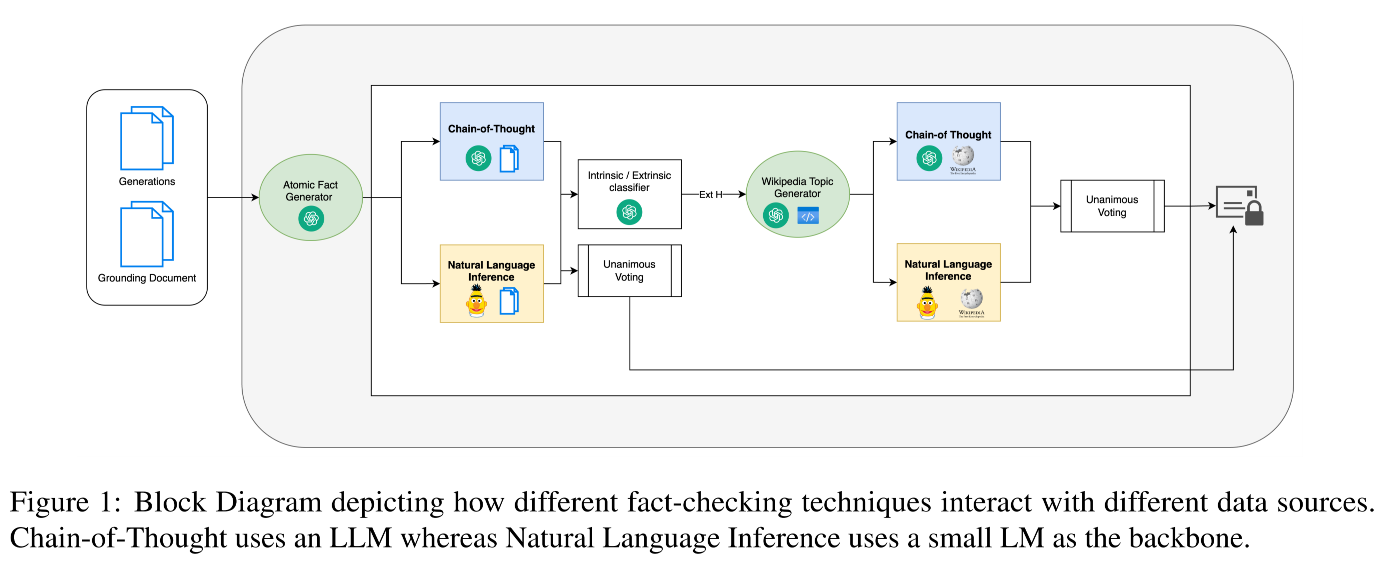
在基准测试中,采用两种最先进的技术——NLI 和 CoT。
原子事实分解:遵循 FActScore 的方法,将模型生成的所有文本(Generations)分解为一系列“原子事实”(Atomic Facts),作为后续核查的最小单元 。
混合核查机制:
内在核查(Intrinsic):首先检查原子事实是否得到原始“参考文档”(Grounding Document)的支持 。
外在核查(Extrinsic):如果某个事实在参考文档中未被提及或被标记为幻觉,则会进一步通过维基百科(Wikipedia Dump)等外部知识库进行核查 。这种设计是为了防止模型说出了参考文档之外但客观正确的事实被误判为幻觉 。
3.1 技术
基线 (Baseline):FActScore作为基线,遵循其在维基百科上无基准文档的外部验证流程。选用该指标的原因在于其近年在生成式NLP领域论文中的广泛应用。
自然语言推理 (NLI):使用 DeBERTa-v3 模型作为骨干,预测前提(生成文本)与假设(参考答案/知识库)之间的逻辑关系 。如果预测为“蕴含”(Entailment)则视为正确,若为“矛盾”(Contradiction)则视为幻觉 。通过预测矛盾原子事实的NLI类别进行外部验证,具体方法为:相关维基百科上下文作为假设。
NLI旨在预测前提与假设之间的逻辑关系,包括蕴含、矛盾及中立立场。
思维链 (CoT):基于 FActScore 进行了改进,使其支持用户提供的参考文档 。它使用 GPT-4o mini 作为核心架构,通过检索维基百科相关条目(以维基百科数据集作为知识源)或直接比对参考文档来进行事实核查 。FActScore通过用户定义的主题从维基百科检索最相关段落,实现外部事实核查功能。 还集成基于LLM的主题生成器,因此在评估时无需手动定义主题 。(就是说改进了FActScore,使其不仅可以通过维基百科来核查,还可以通过输入的“参考文档”(Grounding Document)进行核查)
一致投票机制 (Unanimous Voting, UnVot):只有当 NLI 和 CoT 两种技术同时判定某个事实正确时,才认为该原子事实是准确的 。
人类评估(Human Evaluation):通过与领域专家判断的相关性来评估CoT、NLI和UnVot技术。我们招募了8名具有医学背景的内部雇员担任标注员。 随机抽取80个生成文本(每项任务20个)进行人工标注,确保每个文本由两名标注员评估。标注员遵循相同混合标准,同时参考原始文章和维基百科进行事实核查。要求标注员为每个生成文本评定1至100分,以评估文本的事实准确性。
链式推理采用大型语言模型,而自然语言推理则以小型语言模型为基础架构。
3.2 任务 (Tasks)

各任务在相应数据集上的推理过程中,文章平均词数(#W)与生成token数(#Gen W)。Summ = 文本摘要,LaySumm = 总结摘要,RAG = 检索增强生成,Gen = 开放式生成。
文本摘要 (Text Summarization):将长篇科学医学文章(数据集:PubMed)总结为包含目标、方法和临床意义等关键点的摘要 。(考察大型语言模型将长篇科学论文浓缩为摘要的能力)
通俗摘要 (Lay Summarization):针对非专业读者,使用通俗易懂的语言总结医学研究(数据集:PLOS) 。(通俗摘要要求模型能为生物医学文章生成通俗易懂的摘要)
检索增强生成 (RAG):一个旨在反映生物医学专家真实信息需求的生物医学问答(QA)数据集BioASQ-QA。 问题由专家撰写,证据源自PubMed。本论文采用摘要子集——1130个问题配对PubMed人工筛选的证据片段及基于这些片段的人工撰写的"理想答案"。将黄金片段作为输入提供给大型语言模型(LLM),并提示其生成给定问题的答案,从而模拟RAG管道。
开放式生成 (Open-ended Generation):在此场景下不使用上下文,仅基于模型知识提示其生成答案。再次采用RAG任务中的BioASQ数据集——将1130个问题作为输入,通过提示大型语言模型直接回答问题。
3.3 模型 (Models)
Llama3.1 8b、 Llama3.1 70b、Mistral 7b、Mixtral 8x7b、Gemma2 9b 以及闭源模型GPT-4o mini。
4. 结果与讨论
4.1 与人类评估的相关性

*标记表示先进行内在核查后再进行外在核查的最终评分
维基百科为知识来源的Baseline严重低估了生成文本的正确性,而采用CoT则存在高估现象。总体而言,UnVot评分与领域专家判断的相关性最佳。该结果适用于文本摘要,通俗摘要,RAG。而开放式生成则是Baseline最佳。
UnVot与人类判断的高相关性是一项重要发现。雇佣人类标注员(尤其是领域专家)往往耗资巨大且耗时费力。当某些实验室、研究团队或应用场景难以或无法找到人类标注员时,拥有与人类评分直觉高度相关的评估指标便能提供足够可靠的替代方案。
4.2 任务与大语言模型性能
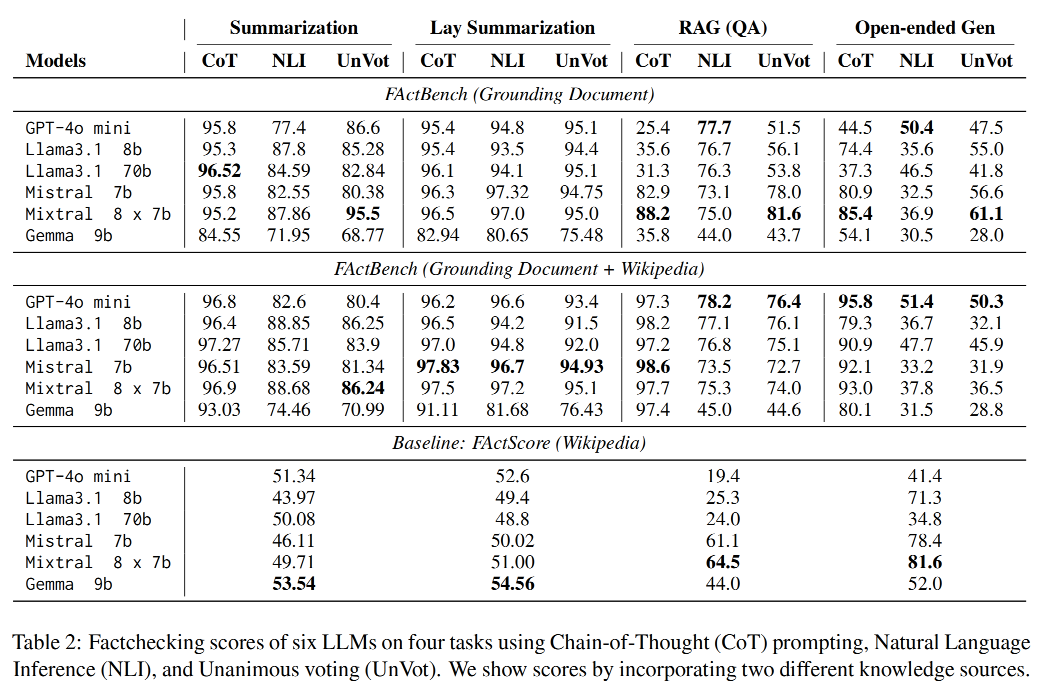
从任务角度看,当被要求执行开放式任务时,大型语言模型更容易产生幻觉(评分比Baseline低)。
在医疗领域生成文本时,大型语言模型表现欠佳。
在其他基于上下文的任务中,当提供正确语境和支持性文档时,这些模型展现出理解医疗等复杂领域的良好能力。
在各任务内部,大型语言模型的表现基本一致。
通俗摘要任务在事实准确性方面表现最佳,这可能源于通俗文本采用简明术语和表述的特性,有效降低了复杂科学术语混淆引发幻觉的可能性。
不同规模的模型在性能上并无显著差异。然而,Mistral和Mixtral在两项摘要任务中均表现优异。尽管Mixtral在仅使用基础文档的两项问答任务中表现最佳,但经过外部验证后,GPT凭借其预训练知识中对维基百科的高认知度脱颖而出。 两款Llama模型表现接近Mixtral,而Gemma在所有任务中均表现最差。
5. 结论
提出一项基准测试,通过医疗领域的4项任务对当代大型语言模型进行评估。探讨了作为事实核查技术的链式推理、自然语言推理和一致性投票。通过领域专家评估,证明一致性投票技术最为可靠。 还评估了两种知识来源(即锚定文档与维基百科)的有效性,发现使用多个知识源可提升事实准确性评分。最后发现,LLM在医疗领域开放式生成任务中普遍存在事实错误,而在摘要生成和RAG等任务中表现更可靠——后两者会为LLM提供部分上下文进行生成。
大语言模型提示词
