

该论文发表在 CIKM 2025 (第 34 届 ACM 信息与知识管理国际会议,The 34th ACM International Conference on Information and Knowledge Management)。
1. 引言
在信息获取便捷的时代,互联网已成为人们寻求健康相关问题答案的主要资源。然而便捷性伴随风险:公众难以区分科学验证的健康建议与缺乏依据的宣称,可能导致错误自诊和有害健康决策。 理想的医疗指导来源应基于可信的同行评审科学研究,但在日益庞大且动态变化的医学研究领域中进行筛选实属不易。
即使是医学研究人员也难以跟上最新发现的步伐,他们需要能够轻松掌握研究发展全貌的工具。此外,某些研究在后面可能会得出相互矛盾的结果的情况也屡见不鲜。传统检索工具难以系统性整合这些分歧结论,导致难以把握特定医学议题的整体共识。现有学术数据库检索工具(如谷歌学术)虽能提供相关文献概览,却无法评估其对核心问题的立场——即支持或反驳特定假说。
为应对这些挑战,推出MedSEBA系统,该系统旨在运用自然语言处理 (NLP)技术及大型语言模型(LLMs)的生成能力,为复杂医学问题提供基于证据的综合解答。本系统的核心优势在于输出结果的可靠性—所有答案均基于知名医学学术数据库PubMed检索到的医学最新最相关研究成果进行验证。与多数检索工具不同,该系统仅以医学论文为依据,并直接引用来源文献中的相关句段。
系统向用户呈现结构化答案,包含核心论据、反映当前研究支持或反驳特定论点的共识评估,以及展示该问题研究演变历程的时间轴图表。这些可视化呈现使系统对希望快速了解现有研究对其潜在研究假设支持程度的医学研究者极具吸引力。
2. 相关工作与系统
2.1 立场(支持程度)
一些系统(如EvidenceMiner、PubTator或LitSense)虽然可以检索数据库(如PubMed)并给定查询相关的文献,但是他们无法揭示研究成果对查询的立场。比如查询“吃维生素C是否可以治疗感冒”,就只能查到相关的文献,无法回答“是”或者“不是”。
2.2 不同来源和论据的对比概述
这个系统应用场景涉及到自动事实核查。虽然已经有了一些实时事实验证系统(如ClaimBuster和CoVerifi),但是他们通常仅提供最终标签(比如“是”或“否”),没有呈现不同来源和论据的综合视图。像论文中所说“柏林是德国的首都”是明确事实,尚可接受。但是类似于“吃维生素C是否可以治疗感冒”这种复杂问题,相关研究可能随着时间推移会得到不同结论,或者因为临床分析会存在分歧。
2.3 生成式搜索的缺陷
生成式搜索是基于检索到的文献和参考文献,针对给定输入提示生成长篇解答与摘要。一些大规模语言模型(如ChatGPT、Gemini)可以支持。但是通常仅提供参考文献的链接,既未标注与输入问题直接相关的段落,也未附带立场标签和清晰的核心论据。
3. 架构
3.1 核心工作流程

3.1.1 文献检索
Expand & optimize query:将输入的问题转化为针对PubMed搜索引擎优化的查询(查询词)。采用基于生物医学文本训练的SciSpacy库进行高级文本处理,执行命名实体识别(NER),检测相关医学概念,并提出同义词及关联实体。
Search academic database:根据PubMed内部相关性排序机制检索出50篇最相关的论文,作为候选。
Re-rank by similarity to the query:采用句子转化器模型(BMRetriever)将查询词与50篇候选文献转化为向量,然后进行余弦相似度计算,选取最高的20篇文献(10篇存在覆盖不足的问题,而30篇则包含过多噪声)。
Get additional metadata:针对每篇最相关的论文,系统调用外部API获取PubMed API缺失的信息(如被引次数、发表平台信息等)向用户展示。最新研究表明,被引次数更多且出版日期更接近的研究,能更可靠地预测医疗声明的真实性。
诸如出版年份、发表渠道(期刊或会议)以及被引次数等元数据,是衡量研究流行度与相关性的通用指标。
3.1.2 答案合成
Generate summary,determine stance labels:最终选定20项研究后,通过详细提示语由大型语言模型(GPT-4o)生成综合摘要。并且引用具体检索到的研究来支撑论述。所有20篇研究的摘要均编号后作为输入传递给模型。

答案以可点击的参考文献形式呈现,摘要下方按研究分类列出20项研究。
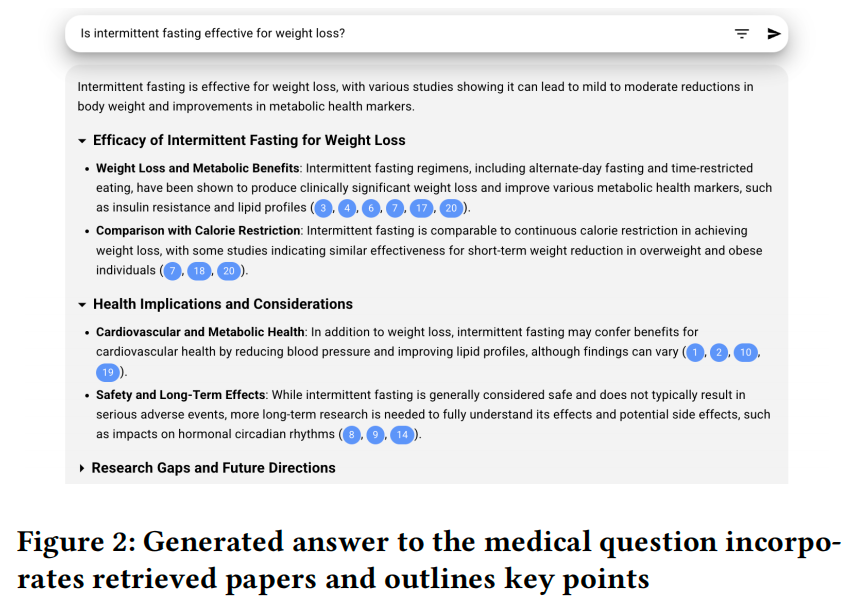

每个研究框包含:研究名称与摘要、相关元数据、对研究问题的立场、以及AI生成的简要摘要。而立场的判定采用的是ChatGPT-4o模型,通过提示词评估论文结论是否支持、反驳或无关乎问题陈述。
虽然也尝试了自然语言推理(NLI)进行微调的编码器模型(如DeBERTa~v3),但由于训练数据在该应用场景中的标签偏移,该模型频繁预测为中性类别(“信息不足")。
因此发现GPT-4o作为立场预测器更为可靠。最后再次采用句子嵌入模型BMRetriever,从每篇论文中识别出直接回应用户查询的最相关句子。
3.1.3 数据来源
PubMed已被证实是验证科学主张和解答医学问题的可靠知识来源。使用公共PubMed API获取文档,主要原因是硬件和存储资源需求降低。尤其是海量文档规模及每次查询计算所有嵌入向量余弦相似度非常耗时间。其次原因是信息时效性——若使用本地数据集的话需要定期更新,而调用API始终可以获取最新研究成果。
3.2 文档页面
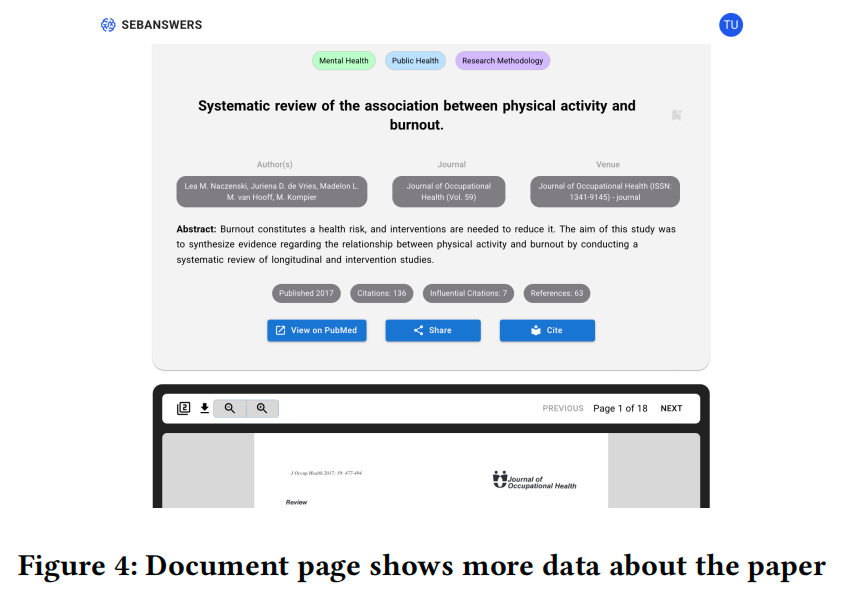
用户可点击用于生成答案的20份文献之一,对其进行详细查阅。文献页面显示前一步检索到的元数据以及论文生成的核心主题(标签)。
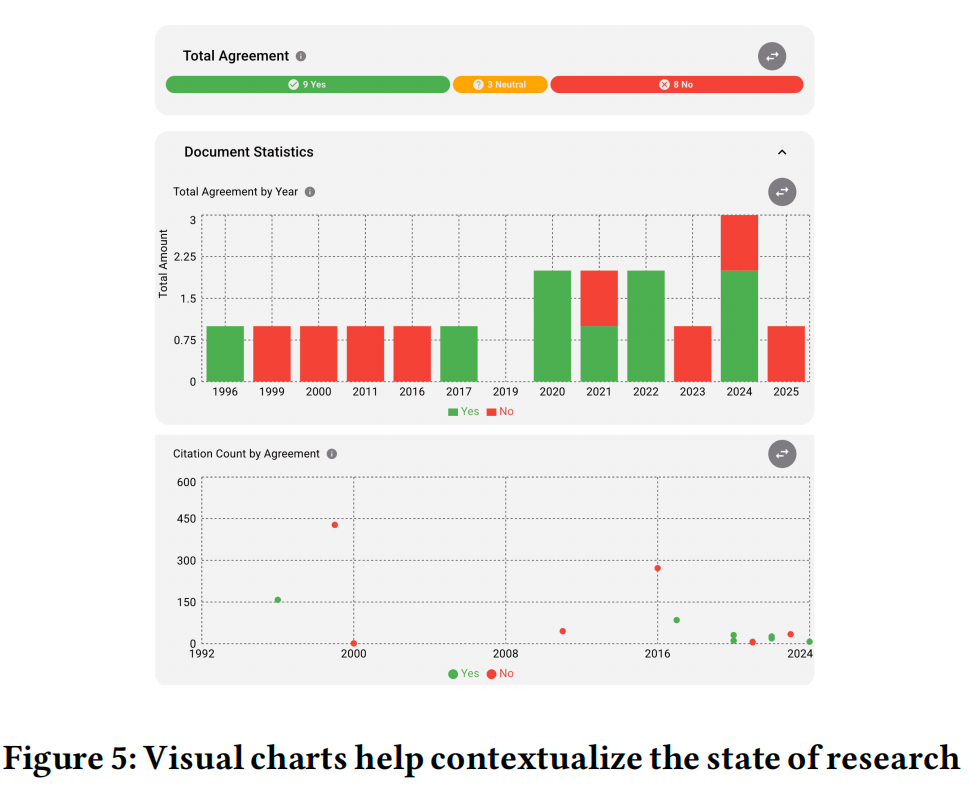
3.3 可视化图表
Plot charts,display results:第一张展示20篇精选文献的立场标签(支持、反驳、中立)的分布情况。第二张展展示每个重点年份均标注支持/反驳标签。第三张图绘制了每项研究的被引次数。这三张图表对普通用户和研究人员具实用价值。
4. 不足
摘要的完整性(根据用户调研得到的结果),因摘要篇幅限制导致部分研究被遗漏,以及从研究摘要中筛选最相关句子的能力。