
第一节:什么是语言模型?
在自然语言处理(NLP)的广阔领域中,语言模型(Language Modeling) 是最基础且最重要的核心任务之一。简单来说,它的目标是让计算机能够理解和生成人类的语言序列。
1. 核心任务:预测下一个词
语言模型的核心任务非常直观:给定一段已经出现的词序列,预测下一个可能出现的词是什么。
想象一下,当你输入一段话:
“The students opened their ____”
作为一个具备语言直觉的人类,你可能会立刻想到“books”、“laptops”、“exams”或者更具哲学意味的“minds”。语言模型的工作就是通过数学方式,为所有可能的单词分配一个概率,告诉你哪一个词在当前语境下最合理。

图中展示了语言模型如何根据前文预测后续单词的概率分布。
2. 数学形式化表达
为了让计算机能够处理这个任务,我们需要将其定义为数学概率模型。
假设我们有一组词序列 x(1), x(2), ... , x(t)。我们的目标是计算下一个词 x(t+1) 的概率分布。用条件概率公式表示为:
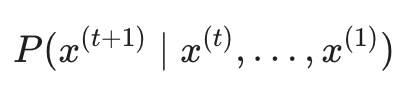
其中,x(t+1) 可以是词汇表 V = {w1, ... , w|V|}$ 中的任意一个单词。任何能够计算出这个概率分布的系统,都被称为语言模型。
3. 为整段文本赋予概率
除了预测下一个词,语言模型还可以用来评估一整段文本出现的可能性。
当你读到一句话时,语言模型可以告诉你这句话在现实语言场景中“听起来有多自然”。根据概率论的链式法则 (Chain Rule),一个包含 T 个词的文本序列的联合概率可以分解为:

利用连乘符号可以简写为:
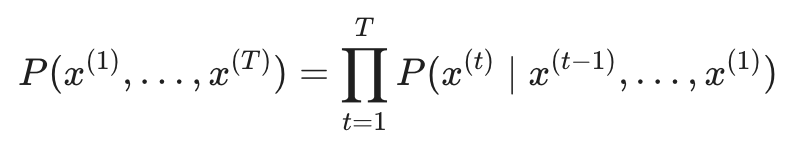

图中展示了利用条件概率乘积计算整段文本概率的数学推导过程。
这意味着,如果一个模型能够精准地预测“下一个词”,它也就具备了衡量整段话逻辑合理性的能力。这正是后续我们讨论机器翻译、语音识别纠错以及自动文本生成等技术的核心基石。
第二节:n-gram 语言模型核心思想
既然我们已经定义了语言模型的目标是计算条件概率,接下来的问题是:如何高效地学习和估算这些概率?在深度学习普及之前,最主流的解决方案就是 n-gram 语言模型。
1. 什么是 n-gram?
n-gram 是指文本中 n 个连续单词组成的序列(或称之为“分块”)。根据 n 取值的不同,我们有不同的称呼:
unigrams (1-gram): 单个单词,如 "the", "students", "opened"。
bigrams (2-gram): 连续的两个词,如 "the students", "students opened"。
trigrams (3-gram): 连续三个词,如 "the students opened", "students opened their"。
four-grams (4-gram): 连续四个词,如 "the students opened their"。

图中展示了在相同句子下,不同 n 值所对应的单词分块方式。
2. 马尔可夫假设 (Markov Assumption)
在上一节中,我们看到计算 P(x(t+1) | x(t), ... , x(1)) 需要考虑前面出现的所有词。然而在实际应用中,随着序列变长,计算和存储这个全量上下文的概率会变得极其困难。
为了简化问题,我们引入了马尔可夫假设 (Markov Assumption):
我们假定当前词的出现概率只取决于它前面的 n-1 个词。
如果是 bigram 模型,当前词只受前一个词影响。
如果是 trigram 模型,当前词受前两个词影响。
数学表达式如下:
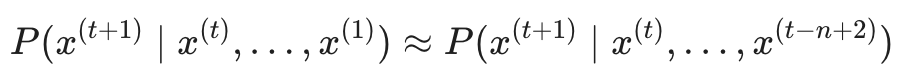
3. 如何估算这些概率?
有了马尔可夫假设,我们就可以通过在大规模语料库(Corpus)中统计不同词组出现的频率,来近似计算条件概率。
根据条件概率的定义:
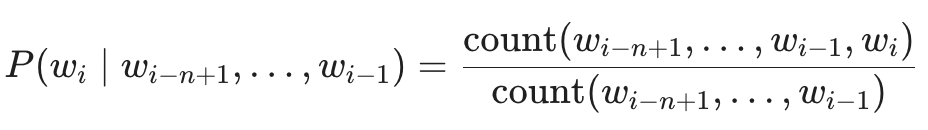
简单来说,就是用 “n-gram 出现的总次数” 除以 “前 n-1 个词作为前缀出现的总次数”。
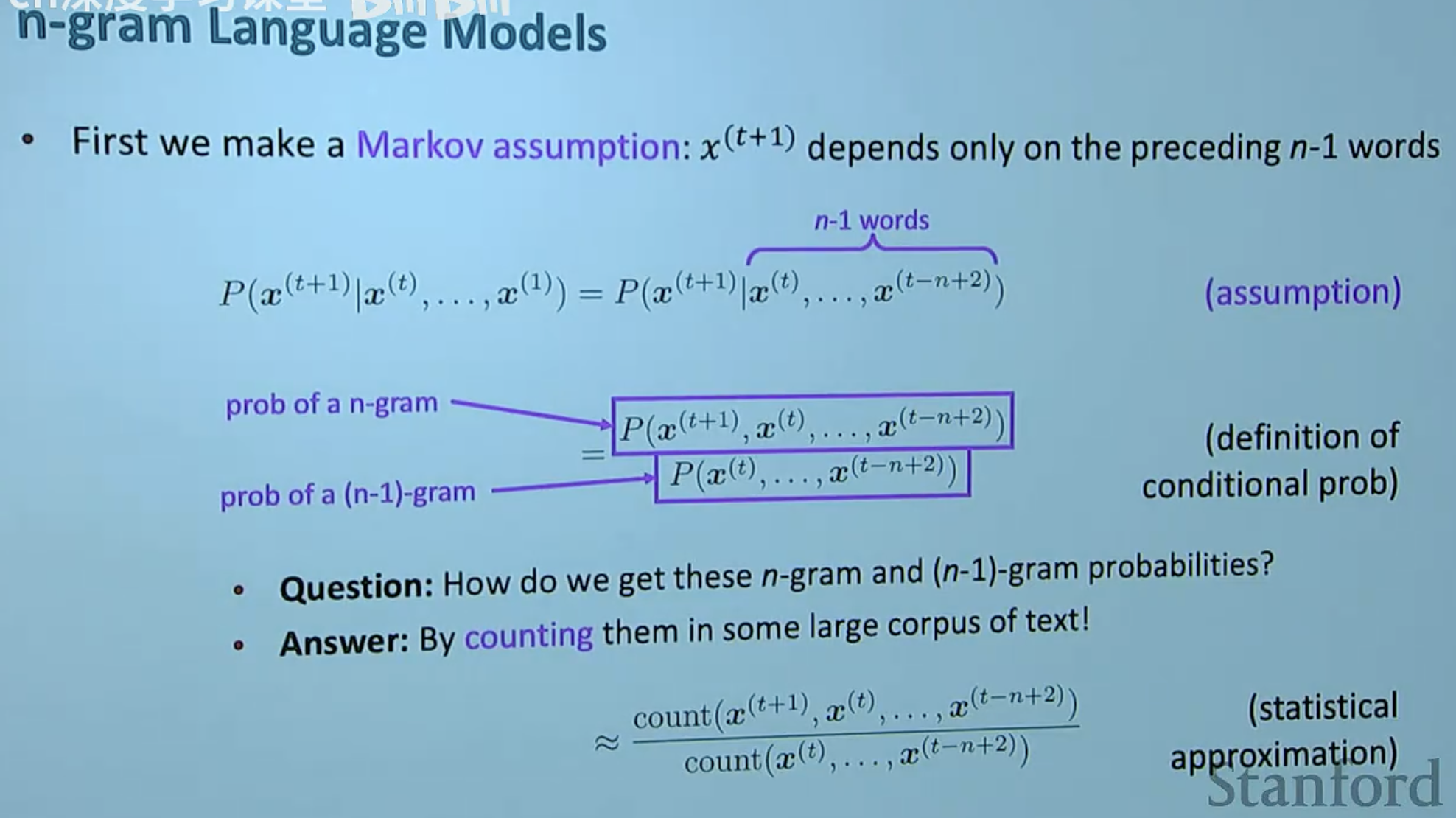
图中详细展示了基于马尔可夫假设的条件概率定义及其统计近似公式。
这种基于统计频率的方法非常直观:如果在你的语料库里,“students opened their books” 出现了 400 次,而 “students opened their” 总共出现了 1000 次,那么在该语料库下,模型预测下一个词是 “books” 的概率就是 0.4。
第三节:n-gram 模型实例演练
为了更直观地理解统计概率是如何运作的,让我们代入一个具体的场景。假设我们正在训练一个 4-gram 语言模型,并试图预测句子 "the students opened their ____" 的下一个词。
1. 寻找预测条件
根据我们上一节提到的马尔可夫假设,4-gram 模型在预测下一个词时,只会关注当前词之前的 3 个词(即 n-1 个词)。
因此,模型会丢弃更远处的背景信息。例如,即使原文是 "As the proctor started the clock, the students opened their ____",模型也会直接“无视”掉关于监考老师(proctor)和时钟(clock)的描述,仅仅根据 "students opened their" 来进行计算。

图中红线部分展示了被模型丢弃的远端上下文,以及被保留的条件前缀。
2. 基于语料库的统计计算
假设我们在一个包含数百万句子的庞大语料库中进行统计,得到了以下数据:
"students opened their" 出现的总次数 = 1000 次
"students opened their books" 出现的次数 = 400 次
"students opened their exams" 出现的次数 = 100 次
根据极大似然估计(MLE),我们可以算出不同后续词的概率:

3. 这种“丢弃”合理吗?
在上面的例子中,我们注意到一个潜在的问题:丢弃“proctor(监考老师)”这个上下文是否明智?
如果上下文包含“监考老师”,那么下一个词是 "exams" 的概率理应比 "books" 更高。
但由于 n-gram 模型的窗口限制(n=4),模型无法感知到较远位置的关键词,从而可能做出次优的预测。
这暴露了 n-gram 模型的一个核心矛盾:
增加 n 值:可以保留更多上下文,使预测更精准。
减小 n 值:模型更简单,但容易丢失长距离的逻辑关联。
然而,单纯地增加 n 并不是万能药,它会直接引出我们下一节要讨论的噩梦——稀疏性问题。
第四节:稀疏性问题与对策
在理想情况下,语料库越大,我们的模型就越准。但在现实中,无论语料库多么庞大,n-gram 模型都会不可避免地撞上一面墙——稀疏性(Sparsity)。当 n 逐渐增大时,特定词组出现的频率会迅速稀释,导致数学计算陷入困境。
1. 稀疏性问题 1:分子为 0
问题描述:如果前缀 "students opened their" 在数据中出现过,但 "students opened their w"(其中 w 是某个具体的词,如 "tablets")从未出现过,该怎么办?
由于 count = 0,模型会分配 P(w) = 0。这意味着在模型看来,这种情况在宇宙中是绝对不可能发生的。这显然不合理,因为这仅仅是因为我们的训练数据没覆盖到,而不是语言本身逻辑不通。
(部分)解决方案:平滑 (Smoothing)
我们会给词汇表 V 中的每一个单词都加上一个极其微小的正数 delta。这样即使某个组合没见过,它也会拥有一个微小但非零的概率。
2. 稀疏性问题 2:分母为 0
问题描述:如果连前缀 "students opened their" 本身都从未在训练数据中出现过呢?
此时分母为 0,数学公式将无法计算,我们甚至没法为一个新词 w 计算任何概率。
(部分)解决方案:回退 (Backoff)
如果我们没见过 "students opened their",那我们就退而求其次,只去查最近的两个词:"opened their"。如果连这也没见过,就只查 "their"。通过降低 n 的值来寻找匹配的统计数据。
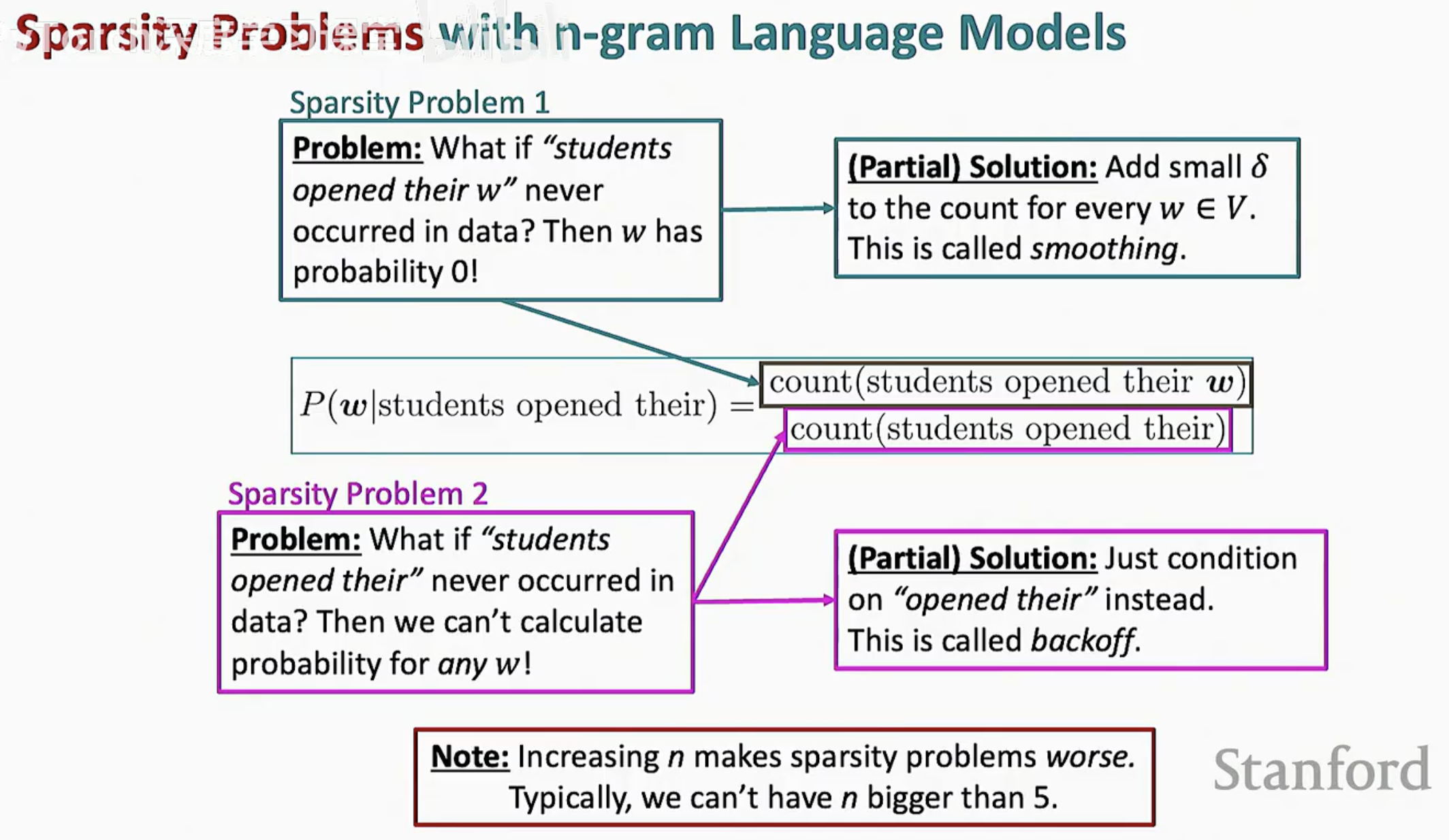
图中总结了两种稀疏性问题的表现及其对应的补救措施。
3. n 值的权衡与限制
你可能会想:既然 n 越大上下文越清晰,那我们用 10-gram 不行吗?
不幸的是,增加 n 会使稀疏性问题呈指数级恶化。当 n 增大时,特定序列出现的概率会变得极低,模型体积也会因为要存储海量的组合计数而变得臃肿不堪。
核心结论:在实际应用中,n 通常不能大于 5。这是一个在“上下文捕捉能力”与“计算可行性”之间妥协的结果。
第五节:文本生成与模型评估
既然语言模型能够预测下一个词的概率分布,我们就可以利用它来“写文章”。这一过程被称为文本生成 (Text Generation)。
1. 生成逻辑:采样 (Sampling)
利用 n-gram 模型生成文本的过程是一个循环迭代的过程:
输入初始语料:给定一个初始上下文(例如 "today the")。
获取概率分布:模型根据当前上下文计算词汇表中所有单词的概率。
采样 (Sample):根据概率分布随机选择一个词(概率越高,被选中的机会越大)。
滚动更新:将选中的词加入上下文,滑动窗口,继续预测下一个词。

图中展示了模型根据 "today the" 得到的概率分布,并采样选中了 "price"。
随着窗口不断向右滑动,模型会基于最新的 n-1 个词持续生成后续内容。


这两张图展示了生成过程的连续性:从预测 "price" 之后,接着预测出 "of",再预测出 "gold"。
2. 效果评估:通顺但“无脑”?
当我们让一个基于大规模语料训练的 n-gram 模型自由发挥时,会得到一个非常有趣的现象。

图中展示了一段由 n-gram 模型生成的长文本示例。
通过观察生成的文本,我们可以得出两个核心结论:
惊人的语法正确性 (Grammatical):由于模型学习了大量局部词组搭配,生成的短句往往非常符合语法习惯。
严重的逻辑不连贯 (Incoherent):由于 n-gram 模型只能看到最近的几个词,它会“转头就忘”。一旦生成的内容超过了窗口长度(例如 4 或 5 个词),前后的逻辑就会迅速脱钩,导致整段话读起来不知所云。
3. 迈向神经网络的桥梁
n-gram 语言模型作为 NLP 历史上的功勋臣子,虽然简单直观且易于解释,但其稀疏性问题和有限的上下文窗口限制了它的进一步发展。
为了解决这些痛点,研究者们开始思考:
是否可以用连续向量(词嵌入)来解决稀疏性,让模型理解词与词之间的相似性?
是否可以用神经网络来捕捉更长跨度的依赖关系?
这正是从传统的统计语言模型向现代深度学习模型(如 RNN, Transformer)跨越的关键动因。