
第一节:绪论——优化算法在神经网络训练中的核心地位
在深度学习的范畴内,模型训练的本质是一个在大规模参数空间内寻找最优解的非凸优化问题。优化器(Optimizer)作为连接模型架构与数据特征的桥梁,其核心任务是通过计算损失函数 L 对模型参数 θ 的梯度,利用特定的更新规则使目标函数最小化。
1.1 目标函数优化与梯度的数学框架
神经网络的训练过程通常遵循风险最小化原则。给定训练集,我们通过反向传播(Backpropagation)获取梯度 。最基础的更新公式可以表示为:
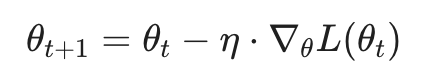
其中 η 代表学习率(Learning Rate),它是决定优化轨迹平稳性与收敛速度的关键超参数。
1.2 收敛性与泛化性的权衡
一个优秀的优化器不仅需要具备高效的收敛性(即在有限的迭代次数内到达局部极小值点),还必须具备良好的泛化能力(即确保模型在未见过的测试集上依然表现优异)。
训练效率:自适应算法通过动态调整步长来加速跨越平坦区域。
性能表现:传统方法如带动量的 SGD 往往能在精细调优后获得更高的预测精度。
1.3 工业界与学术界的优化范式
在实际应用中,选择优化器并非盲目追求算法的复杂程度。如斯坦福 CS 课程中所强调的,基础的随机梯度下降(SGD)在许多场景下依然是不可或缺的基准。然而,随着模型规模的爆炸式增长(如 Transformer 架构),具有参数级差异化学习率的自适应优化器逐渐成为了现代深度学习的工业标准。

第二节:随机梯度下降 (SGD) 及其启发式调优
在深度学习的发展历程中,随机梯度下降(Stochastic Gradient Descent, SGD)始终是各类复杂优化算法的基准。虽然其数学表达简洁,但在高维非凸优化空间中,SGD 的表现高度依赖于超参数的启发式配置。
2.1 SGD 算法原理与批处理机制
SGD 的核心逻辑在于利用小批量(Mini-batch)数据产生的梯度估计值来代替全局梯度。其参数更新公式为:
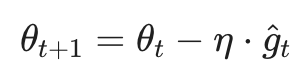
其中 ^gt 是在时间步 t 基于样本子集计算的梯度。相比于全量梯度下降(Batch Gradient Descent),SGD 引入的统计噪声(Statistical Noise)能起到正则化的作用,帮助模型逃离尖锐的局部极小值点,从而提升泛化性能。
2.2 学习率调度策略 (Learning Rate Scheduling)
如截图所述,“Plain SGD will work just fine!” 但前提是必须进行精细的手动调优(Hand-tuning)。
2.2.1 初始学习率的选择
初始学习率决定了训练早期的稳定性。过大的 $\eta$ 会导致损失函数震荡甚至发散;过小的 η 则会导致收敛速度极其缓慢,容易陷入平坦区域。
2.2.2 衰减机制与分段函数
截图提出了一个经典的策略:“Start it higher and halve it every k epochs”(以较高的初始值开始,每经过 k 个轮次将其减半)。这种分段常数衰减(Step Decay)的内在机理是:
前期:保持较大的步长,快速跨越损失函数的高能区域。
后期:减小步长,使模型在最优解附近进行更精细的搜索,降低残余误差。
2.3 数据洗牌 (Shuffling) 与采样随机性
截图特别强调了数据应是 "shuffled or sampled"。在每一轮训练(Epoch)开始前对数据进行随机洗牌,是为了确保每个 Batch 的梯度估计是无偏的。如果数据存在特定的序列相关性(例如分类任务中按类别排列),不进行洗牌会导致模型在各类别间产生灾难性遗忘或振荡,破坏收敛的平稳性。
2.4 动量机制(Momentum)的引入
虽然截图中未详细展开,但在学术界讨论 SGD 时,通常默认包含动量项。动量通过累积历史梯度方向来加速具有一致梯度的维度,并抑制高频震荡:
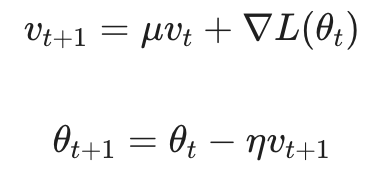
这种方法在保持 SGD 泛化优势的同时,显著提升了收敛效率。
第三节:自适应学习率算法的演变逻辑
自适应优化器的核心思想是打破“全局单一学习率”的局限,根据每个参数的历史梯度信息,自动调整其更新步长。这种“因材施教”的策略在大规模稀疏数据和深层网络中具有显著优势。
3.1 全局学习率在非凸优化中的局限性
在复杂的神经网络中,不同层的参数往往具有截然不同的梯度量级。
病态曲率(Ill-conditioned curvature):损失函数表面往往呈现出类似于“长峡谷”的形态。在某些维度上(坡度陡峭),梯度极大,容易引发震荡;而在另一些维度上(坡度平缓),梯度极小,导致更新停滞。
稀疏特征挑战:在处理文本或分类数据时,某些特征(如长尾词)出现的频率极低。若采用统一学习率,这些稀疏特征对应的参数将无法得到充分的训练。
3.2 自适应机制:二阶动量的引入
截图指出,这些优化器通过 “Accumulated gradient”(累积梯度)来缩放每个参数的调整量。其数学本质是引入了二阶动量 vt(即梯度平方的累积):

参数更新公式演变为:
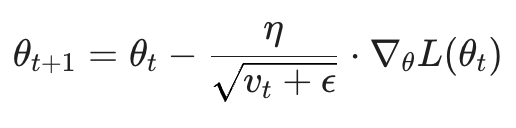
其中 ε 是为了保证数值稳定性的极小常数。这种机制实现了:
频繁更新的参数:累积梯度平方和较大,学习率被自动压缩,防止震荡。
罕见更新的参数:累积梯度平方和较小,学习率相对放大,加速收敛。
3.3 从“手动调优”到“自动感知”
相比于第二节提到的手动衰减(Hand-tuning),自适应优化器提供了一种微分化参数级学习率(Differential per-parameter learning rates)。
这一转变解决了两个痛点:
降低超参数敏感度:虽然仍需设置初始学习率(如图所建议的 0.001),但算法对初始值的容错性显著提高。
消除担忧(To avoid worry):对于非专家用户,自适应算法提供了“开箱即用”的体验,减少了在训练过程中频繁监控并手动调整学习率的需求。
第四节:自适应学习率家族的技术路径分析
图中列举了从 Adagrad 到 Adam 的演进过程。这些算法通过不同的方式处理“累积梯度”(Accumulated Gradient),以平衡收敛速度与训练稳定性。
4.1 Adagrad:早期自适应尝试与“早期停滞”现象
Adagrad 是自适应学习率的先驱,其核心在于对每个参数的学习率除以其历史梯度平方和的平方根。
技术优势:在处理稀疏数据(如自然语言处理中的低频词)时表现优异,能为更新频率低的参数提供更大的步长。
局限性解析:如截图所述,Adagrad 倾向于 “Stall early”(早期停滞)。由于分母中的梯度平方和是单调递增的,导致有效学习率随时间迅速衰减至极小值。在训练后期,即使尚未到达最优点,模型也可能因步长过小而停止更新。
4.2 RMSprop:引入衰减因子解决单调递减问题
为了克服 Adagrad 的停滞问题,RMSprop 引入了指数移动平均(Exponential Moving Average, EMA)。它不再无限制地累积历史梯度,而是通过一个衰减速率(通常为 0.9)来“遗忘”较远的梯度信息:

这种改进使得学习率能够根据当前的梯度量级动态调整,从而有效应对非平稳目标函数,使训练能够持续进行。
4.3 Adam:一阶动量与二阶动量的融合
截图将 Adam 描述为 “A fairly good, safe place to begin in many cases”(在多数情况下是一个稳妥的起点)。Adam(Adaptive Moment Estimation)结合了 Momentum 的惯性和 RMSprop 的自适应缩放:
一阶动量(mt):利用梯度的指数移动平均来平滑优化路径,减少震荡。
二阶动量(vt):动态调整每个参数的学习率。
偏差修正(Bias Correction):通过修正初期由于初始化为零导致的估计偏差,确保训练初期的稳定性。
4.4 初始学习率的经验法则
尽管这些优化器被称为“自适应”,但它们仍保留了全局初始学习率这一超参数。
经验阈值:图中建议 “Start them with an initial learning rate, around 0.001”。
调优策略:相比于 SGD 对学习率的极端敏感,Adam 等算法在 0.001 附近通常能表现出较强的稳健性(Robustness),这正是其作为“通用首选”的原因。
第五节:现代优化器的结构演进:AdamW 与 NAdamW
图在列表末尾标注了两个进阶版本。特别是 AdamW,它纠正了深度学习框架中长期存在的一个实现误区,从而显著提升了模型的泛化能力。
5.1 权重衰减(Weight Decay)的解耦优化
在传统的 SGD 中,L2 正则化等同于权重衰减。但在 Adam 等自适应算法中,直接加入 L2 正则化会导致正则化项被二阶动量(梯度平方和)缩放。
失效机理:如果一个参数的梯度很大,其自适应学习率就会变小,导致 L2 惩罚项也被相应缩小。这使得正则化在更新频繁的参数上失效。
AdamW 的解决方案:将权重衰减从梯度更新中解耦(Decoupled)出来,直接作用于参数更新步骤:

这种改进确保了无论梯度如何变化,权重衰减的强度始终保持一致。这也是为什么在现代 NLP 任务(如 BERT、GPT 系列)中,AdamW 是默认的优化器选择。
5.2 NAdamW:Nesterov 加速梯度与动量的结合
图提到 NAdamW 对于速度(Nesterov acceleration)有更好的表现。
Nesterov 算子(NAG):传统动量是基于当前梯度的累积,而 Nesterov 则是“先跨一步,再求梯度”。这种“前瞻性”的机制允许优化器在损失平面下坡时更早地减速,从而减少超调(Overshoot)。
应用场景:NAdamW 将 AdamW 的稳定自适应性与 Nesterov 的快速收敛特性结合。实验表明,在需要精细特征捕捉的任务中,它往往比标准 Adam 表现更优。
5.3 词向量(Word Vectors)与稀疏更新
图特别标注了 NAdamW 在 Word Vectors (W) 任务中的优势。
在处理高维稀疏的学习任务(如大规模嵌入层更新)时,Nesterov 带来的预测性更新能够更有效地调整那些分布极其不均匀的词向量空间,从而在相同的迭代次数下获得更具表征能力的向量表示。