
一、引言
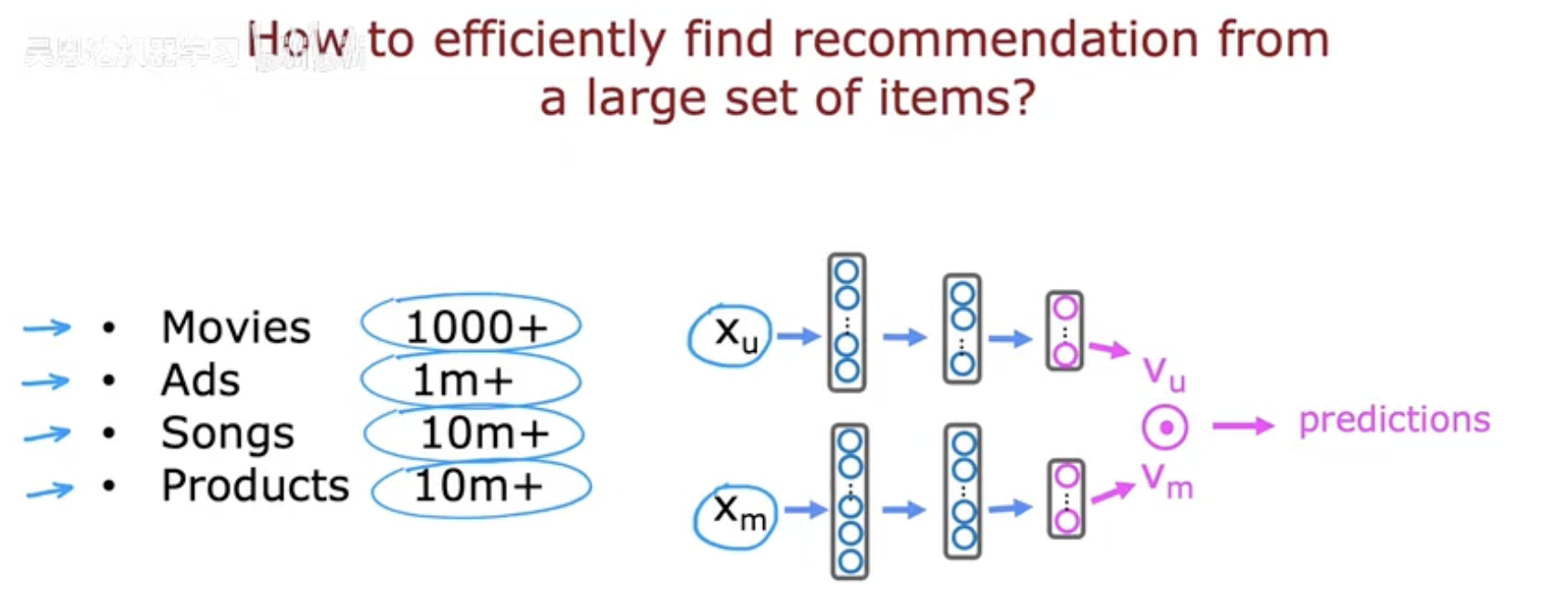
在现代推荐系统中,应用场景的规模往往非常庞大。比如:
电影平台可能拥有上千部以上的电影;
广告推荐系统需要从上百万广告中挑选;
音乐平台的歌曲数量轻松超过一千万;
电商平台更是有上千万的商品等待推荐。
在这样的大目录中,推荐系统需要在极短的时间内为用户找到最合适的内容。如果没有高效的方法,系统可能会陷入性能瓶颈:要么计算开销过大,要么推荐结果不够精准。
为了解决这一挑战,研究者和工程师们通常采用一种高效的思路:
👉 先缩小范围,再做精细化选择。
这意味着推荐系统不会直接在所有候选项目中逐一比较,而是通过一系列机制先快速筛选出一个较小的候选集,然后再进一步做更精确的排序和预测。这样既能保证推荐的效率,也能兼顾推荐的质量。
二、两步法:检索与排序
在面对千万级别的候选集合时,推荐系统通常采用 Retrieval(检索)+ Ranking(排序) 的两步策略。这种方法将大规模推荐问题拆解为两个阶段,从而在效率与效果之间取得平衡。

2.1 检索阶段(Retrieval)
在检索阶段,系统的目标是从海量候选集中,快速生成一个较小的候选集(例如几百个项目),这些项目需要满足基本的相关性。
常见的方式包括:
基于相似度的检索:例如,对于用户最近看过的 10 部电影,找到最相似的 10 部电影;
基于热门类别的检索:对于用户观看最多的 3 个类别,从中找出 Top-N 项;
基于全局热门的检索:例如当前国家/地区的 Top20 热门项目。
这个阶段的重点是 覆盖广、召回快,确保不会错过潜在的高相关候选。
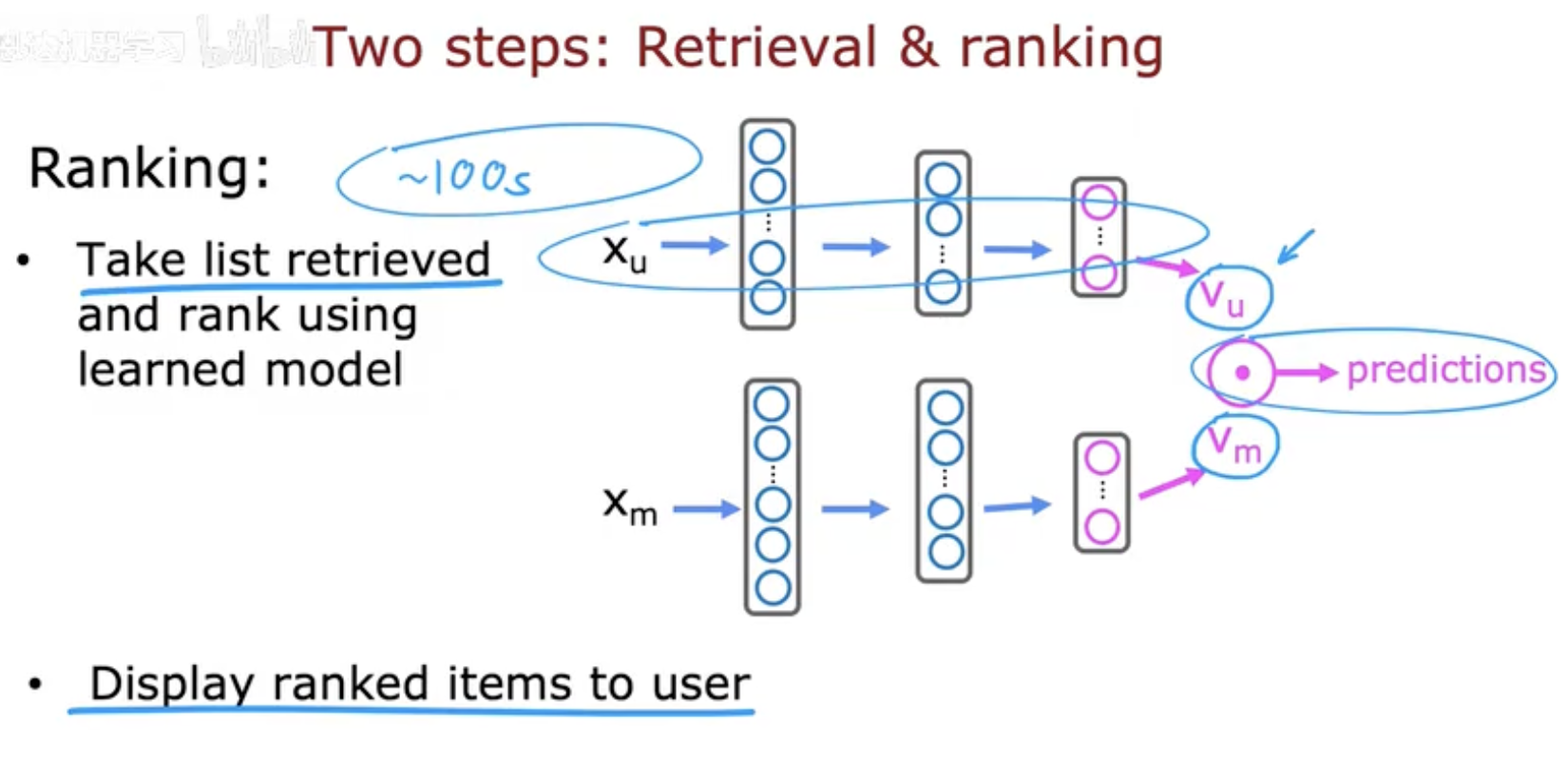
2.2 排序阶段(Ranking)
检索出来的候选集数量虽然已经减少,但仍然可能有几百甚至上千个项目。排序阶段的任务就是利用更加复杂和精确的模型,对这些候选进行打分和排名。
使用用户和物品的深度向量表示(embedding),结合用户的历史行为和上下文信息;
将候选项目逐一输入模型,得到预测分数;
最终选出得分最高的一小部分,展示给用户。
这个阶段注重的是 精准性和个性化,是决定最终推荐体验好坏的关键。
三、检索与排序的权衡问题

在大规模推荐系统中,检索和排序之间始终存在一个核心矛盾:
更多的检索候选 → 更高的覆盖率,用户可能会得到更相关的推荐;
更少的检索候选 → 系统计算量减少,推荐速度更快。
3.1 检索数量对性能的影响
检索更多项目:例如从候选池中取 500 个项目进入排序阶段,能够保证较高的召回率,但计算开销显著增加,导致推荐响应变慢;
检索较少项目:例如只取 100 个项目进入排序,响应速度快,但可能遗漏一些相关候选。
因此,需要根据业务目标来调整检索规模。
3.2 Trade-off(权衡)的优化
为了找到最佳平衡点,推荐系统通常会通过 离线实验 和 在线 A/B 测试 来评估不同检索规模的效果:
在离线实验中,比较不同检索数量对覆盖率、点击率预测准确度等指标的影响;
在在线实验中,直接观察用户在真实环境下的互动表现,比如点击率、停留时长、转化率等。
通过这样的实验,可以找到一个合适的 检索数量,既保证了推荐的相关性,又不至于让系统延迟过高。
四、总结
在海量候选项目的背景下,推荐系统必须在 效率 与 效果 之间找到平衡。
第一节我们看到,大规模目录(如电影、广告、音乐、商品)带来了巨大的计算挑战。
第二节介绍了经典的 检索 + 排序 两步法,将问题分解为“快速缩小范围”和“精细化选择”,有效兼顾了速度与准确性。
第三节进一步探讨了检索与排序之间的权衡,强调了通过实验不断优化,才能在不同场景下找到最优的检索规模。
最终,一个成熟的推荐系统往往需要结合 大规模检索 与 个性化排序,并不断迭代优化,才能在保持系统响应速度的同时,为用户提供真正精准且令人满意的推荐。