
一、引言
推荐系统在现代互联网应用中扮演着至关重要的角色,它们能够帮助用户从海量信息中快速找到感兴趣的内容。传统的推荐方法主要包括两类:协同过滤(Collaborative Filtering) 和 基于内容的过滤(Content-based Filtering)。其中,基于内容的过滤方法通过分析用户特征与物品特征之间的匹配关系,来实现个性化推荐。
然而,传统的基于内容的推荐在处理复杂特征时存在局限性。随着深度学习的发展,我们可以借助神经网络自动提取和学习用户与物品的低维表示(embeddings),这种方法不仅提升了推荐的精度,还能更好地捕捉特征之间的非线性关系。
在本文中,我们将介绍 Deep learning for content-based filtering 的基本思路,展示其网络结构、训练方式以及如何利用学到的向量表示来进行推荐和相似性检索。
二、神经网络结构
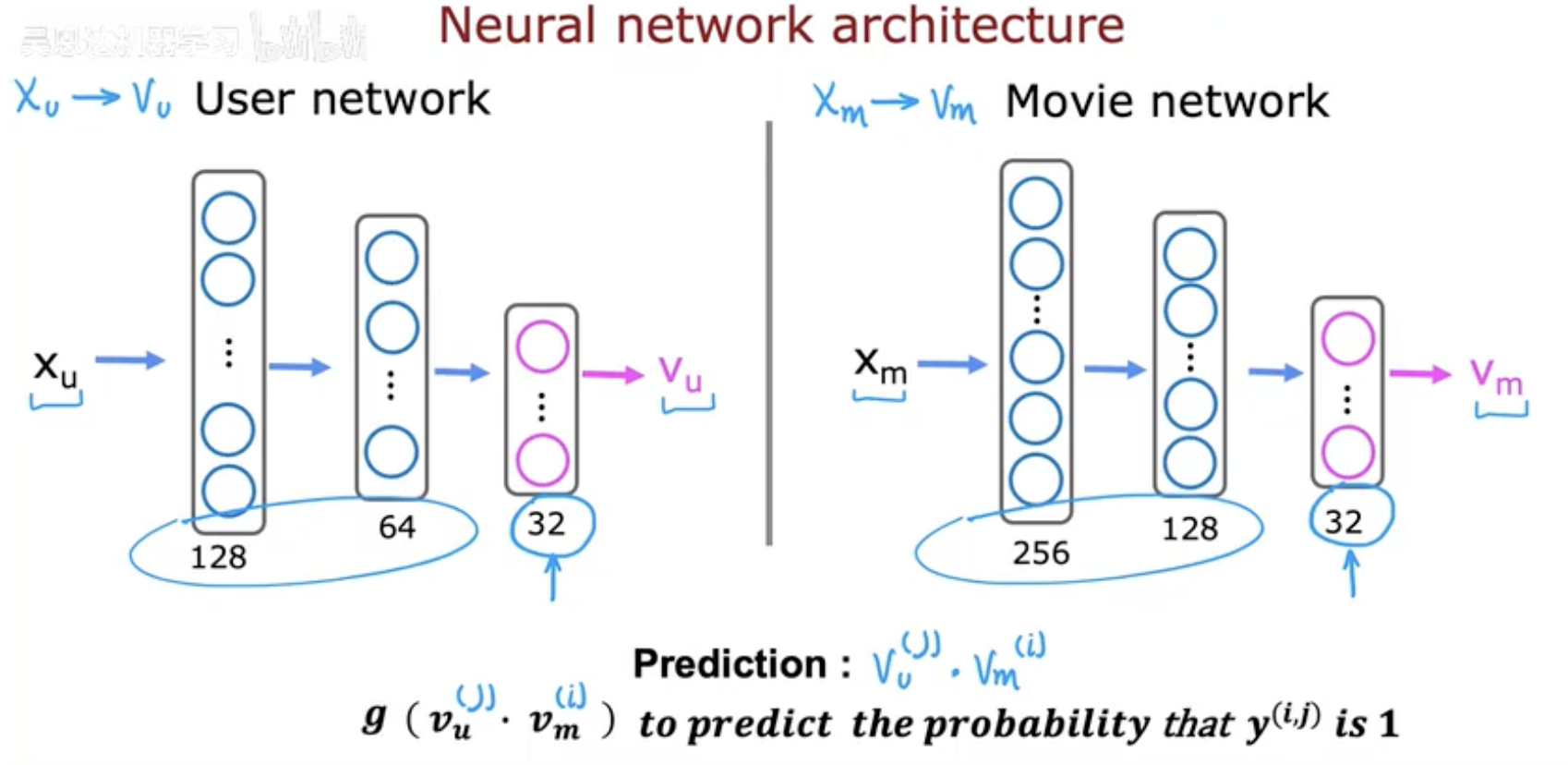
在深度学习的基于内容的推荐方法中,用户和物品的数据首先会被转化为特征向量:
用户特征向量:记作 xu,包含用户的年龄、性别、观看历史、偏好等。
物品特征向量:记作 xm,例如电影的类型、年份、主演、平均评分等。
然后,用户向量和物品向量会分别输入到两个独立的神经网络中:
User Network(用户网络):将输入的用户特征 xu 映射到一个低维的用户表示向量 vu。在图中,输入层维度较大,经过隐藏层逐步压缩,最终得到一个长度为 32 的向量。
Movie Network(物品网络):将输入的电影特征 xm 映射到物品表示向量 vm。同样,输入特征维度较高,经过层层网络降维,最后也得到一个长度为 32 的向量。
这两个网络可以看作是“特征抽取器”,它们的目标是将复杂的高维特征压缩成紧凑的低维表示,从而便于后续计算。
最终,我们将用户向量 vu 与物品向量 vm 进行点积(dot product),并通过一个函数 g(vu⋅vm) 来预测用户是否会喜欢该物品。
这张图形象地展示了 并行的双塔网络结构(two-tower model):一边处理用户,一边处理物品,最后在向量空间中对齐,从而实现匹配预测。
三、预测与损失函数
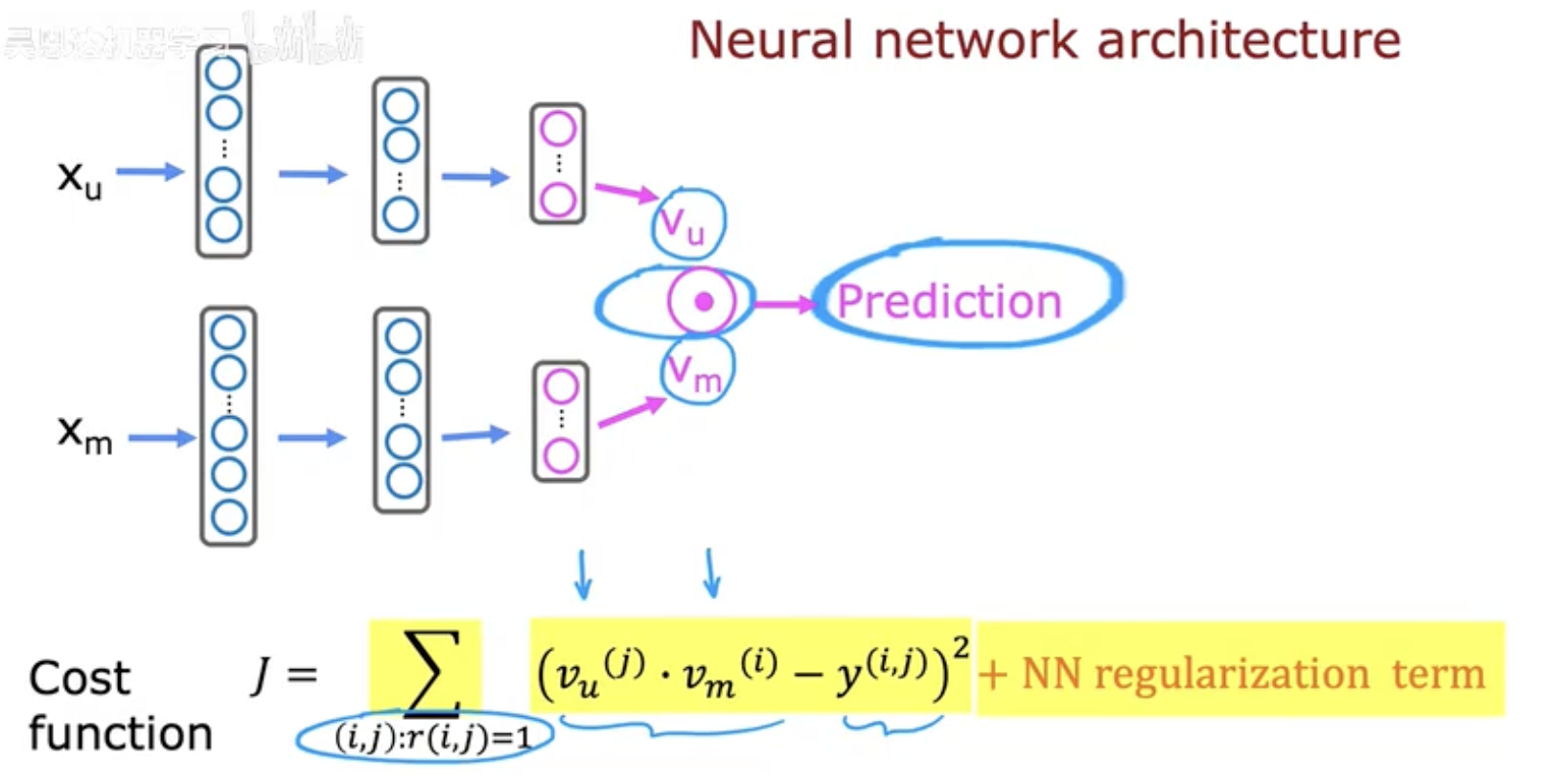
当用户向量 vu 和物品向量 vm 被神经网络分别学习出来后,我们需要一个方法来预测用户是否会喜欢某个物品。
3.1 预测(Prediction)
通过 点积运算 vu⋅vm,我们可以计算用户与物品的匹配程度。
点积值越大,说明用户与该物品在向量空间中的相似度越高,也就意味着用户更有可能喜欢它。
在图中,这个结果会进一步输入一个预测函数 g(vu⋅vm),通常是 sigmoid函数 或 softmax函数,用于输出一个概率值:
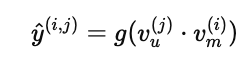
其中,y^(i,j) 表示用户 j 喜欢物品 i 的概率。
3.2 损失函数(Cost Function)
为了让模型学会更准确的预测,我们需要定义一个损失函数。常见的选择是 平方误差损失:
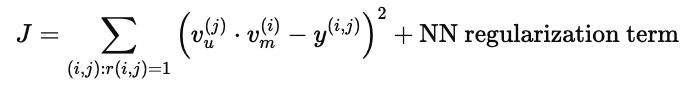
r(i,j):表示用户 j 是否对物品 i 有过评分。
y(i,j):用户 j 对物品 i 的真实反馈(例如评分、点击或喜欢标记)。
正则化项:防止模型过拟合,保证学习到的向量在新样本上也能表现良好。
这张图清晰地展示了预测流程:用户向量 vu 和物品向量 vm 经过点积得到预测值,再与真实反馈进行比较,通过损失函数指导网络的更新。
四、学习到的向量表示

在经过神经网络的训练之后,每个用户和每个物品都会被表示为一个低维向量,这些向量是模型自动学习得到的。
4.1 用户向量 vu(j)
每个用户 j 会对应一个向量 vu(j),其长度在图中设定为 32。
这个向量浓缩了用户的兴趣偏好信息,例如某用户可能更偏爱动作片,而另一个用户可能更喜欢浪漫片。
与原始的用户特征(年龄、性别、国家等)不同,vu(j) 是一种抽象的表示,能更好地反映用户与物品的交互关系。
4.2 物品向量 vm(i)
每个物品 i(如一部电影)会对应一个向量 vm(i),同样长度为 32。
它融合了该物品的特征(如电影的类型、年份、主演等),最终形成一个紧凑的表示。
例如,动作片和浪漫片的向量可能分布在不同的区域,而两部同类型电影的向量会更接近。
4.3 相似度计算
一旦用户和物品的向量被学出,我们就能通过向量运算来计算相似度:
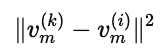
如果两个物品的向量距离很小,就说明它们相似,可以推荐给有相关兴趣的用户。
这种方法还能帮助实现“查找相似物品”的功能,比如推荐与某部电影风格接近的其他影片。
4.4 预计算的优势
在实践中,所有用户和物品的向量可以提前计算好并存储,这样在实时推荐时只需要做快速的向量运算,大大提高了推荐系统的响应速度。
五、总结
在本文中,我们介绍了 Deep learning for content-based filtering 的核心思想与实现方法:
神经网络结构
用户特征和物品特征通过独立的神经网络分别映射为低维向量(embedding)。
这种双塔模型(two-tower model)能够灵活处理高维、稀疏和多样化的特征。
预测与损失函数
用户向量与物品向量通过点积得到预测值。
损失函数衡量预测值与真实反馈的差异,并通过正则化防止过拟合。
学习到的向量表示
用户向量反映了用户的兴趣偏好。
物品向量提炼了物品的核心特征。
通过向量运算,可以实现用户-物品匹配和物品-物品相似性检索。
优势:
能捕捉复杂的非线性关系,比传统的线性基于内容过滤更强大;
可扩展到多模态信息(文本、图像、音频),提高推荐的丰富度;
向量化表示便于大规模检索,支持实时推荐。
挑战:
对计算资源的需求更高,训练和存储成本较大;
需要大量的用户和物品特征数据,冷启动时仍可能受限;
参数调优和模型结构设计复杂。
一句话总结:
深度学习为基于内容的过滤赋予了更强大的表示能力和预测能力,使推荐系统在面对大规模数据和复杂特征时表现更出色,是现代推荐系统的重要方向之一。