
第一节:RNN 的核心架构
1.1 为什么我们需要 RNN?
在处理图像识别或简单分类任务时,传统的全连接神经网络(DNN)和卷积神经网络(CNN)表现卓越。但在处理序列数据(如自然语言、语音、股票走势)时,它们会面临两个致命的缺陷:
输入长度固定:传统模型要求输入向量的维度必须预先设定,但现实中的句子长度千差万别。
缺乏时序记忆:传统的网络每一层之间是独立的,它无法理解“当前词语的含义往往取决于之前的词语”。
为了解决这些问题,循环神经网络(Recurrent Neural Networks, RNN) 应运而生。它的核心思想非常朴素:在不同的时间步(Timesteps)重复使用相同的参数 W。
1.2 权值共享的艺术
RNN 的本质是一族神经架构,其最显著的特征就是“循环”。
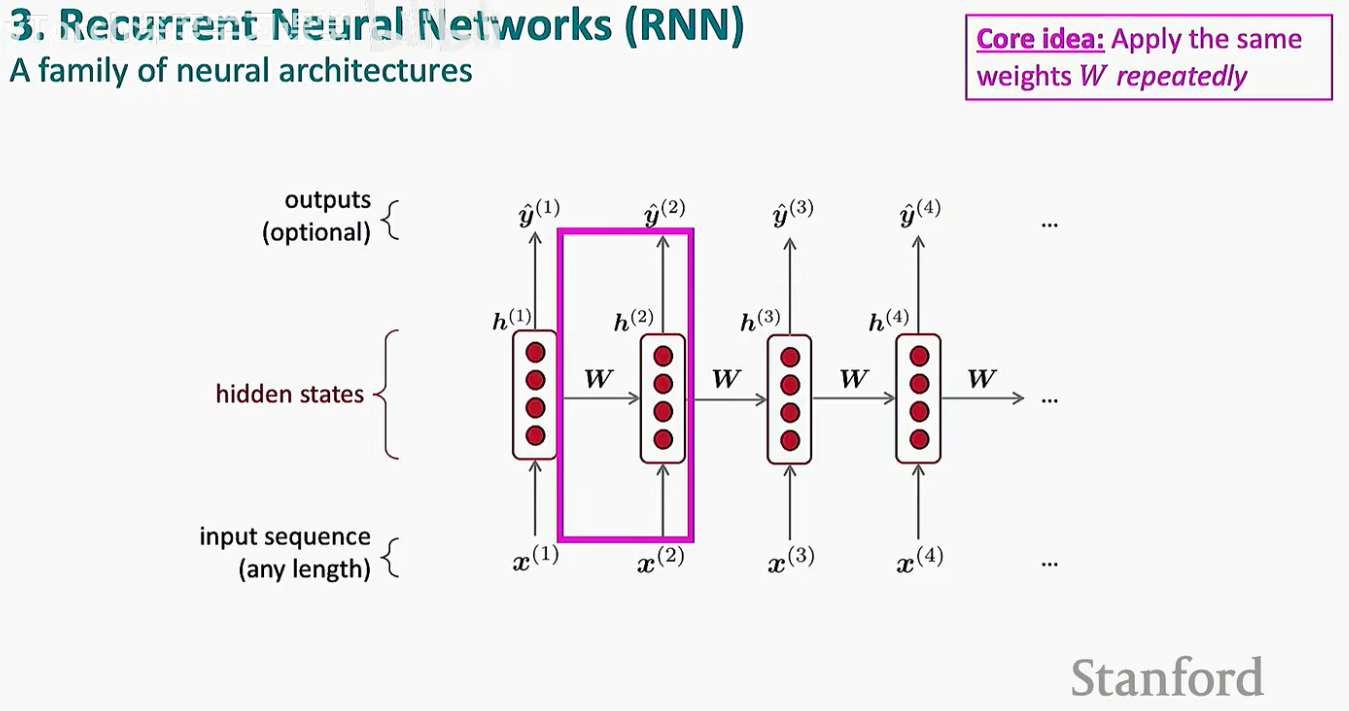
如上图所示,RNN 的运行逻辑可以概括为以下几点:
输入序列:我们可以输入任意长度的序列 x(1), x(2), ... , x(t)。
隐藏状态(Hidden States):这是 RNN 的“灵魂”。每一个时间步都会产生一个隐藏状态 h(t),它就像是一个内存(Memory),存储了从序列开头到当前时刻的所有有用信息。
参数共享:注意图中连接隐藏状态的权重 W。无论序列多长,我们都使用同一个 W。这种对称性不仅极大地减少了需要训练的参数量,还让模型能够处理它在训练时从未见过的超长序列。
1.3 核心计算公式
在每一个时间步 t,RNN 实际上在做两件事:
接收当前的输入 x(t)。
接收上一时刻传下来的“记忆” h(t-1)。
通过一个非线性激活函数(通常是 tanh 或 ReLU),它会将这两者融合,生成新的记忆 h(t):
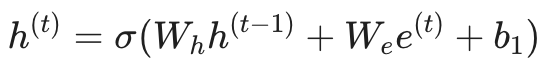
这种结构意味着,当前的隐藏状态 h(t) 理论上包含了之前所有步骤的信息。
第二节:构建 RNN 语言模型 (RNN-LM)
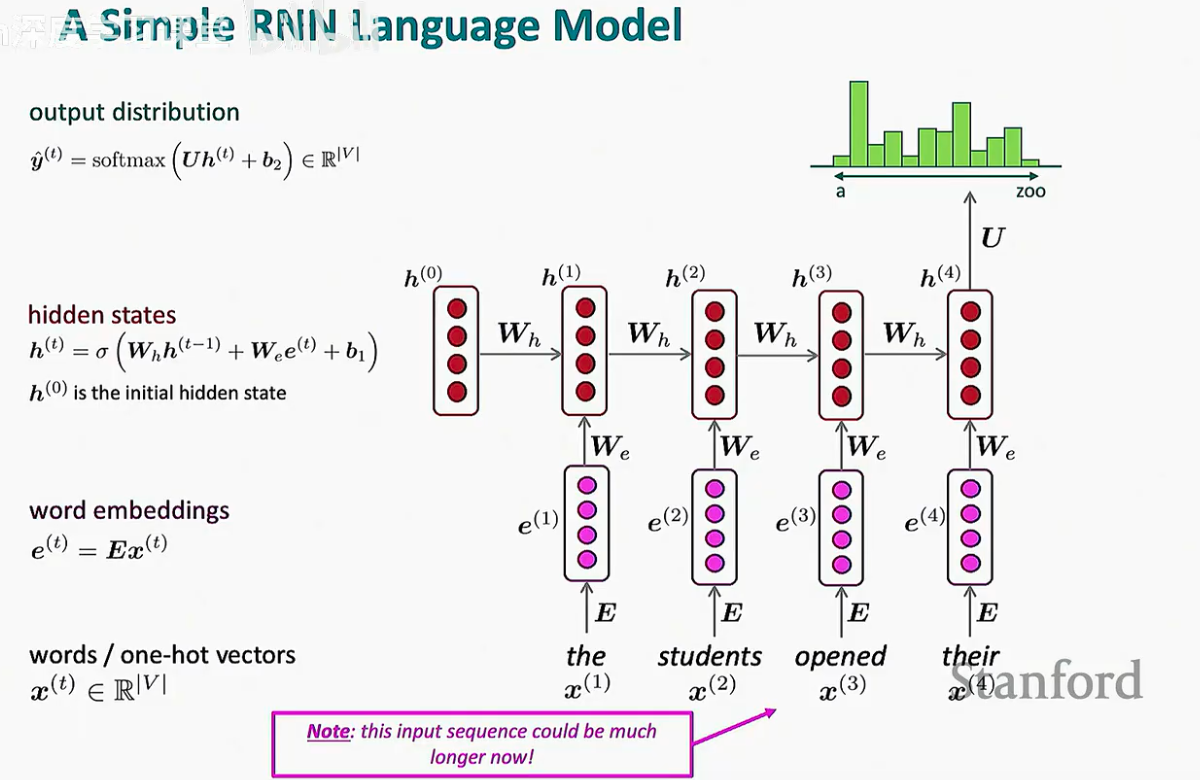
要让 RNN 读懂文字并预测未来,我们需要将其结构具象化。一个完整的 RNN 语言模型通常包含四个核心层次:输入层、嵌入层、隐藏层和输出层。
2.1 从单词到向量:词嵌入(Word Embeddings)
计算机无法直接理解字符。首先,我们将单词表示为独热编码(One-hot vector) x(t)。
为了捕捉词与词之间的语义关系,模型会通过一个嵌入矩阵 E 将高维稀疏的独热向量转换为低维稠密的词嵌入向量 e(t):
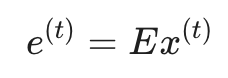
2.2 隐藏状态:捕捉语境
正如我们在第一节提到的,隐藏状态 h(t) 是模型的“短期记忆”。在语言模型中,它通过以下公式更新:
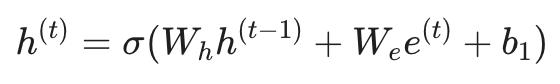
这里,We 决定了模型如何看待当前读入的词,Wh 则决定了模型如何保留之前的语境信息。
2.3 输出分布:预测下一个词
为了预测下一个单词,我们需要将隐藏状态 h(t) 映射回词表大小的维度。这时,我们会引入一个新的权重矩阵 U:
线性映射:计算得分向量 U h(t) + b2。
归一化:通过 Softmax 函数将得分转化为概率分布 ^y(t)。
^y(t) 中的每一个维度都代表了词表中某个词作为下一个词出现的概率。例如,如果模型读到了 "the students opened their",^y(t) 在 "books" 或 "laptops" 上的概率值应当显著高于 "zoo"。
2.4 RNN 的天然优势
相比于传统的 n-gram 模型,RNN 语言模型展现出了极强的灵活性:
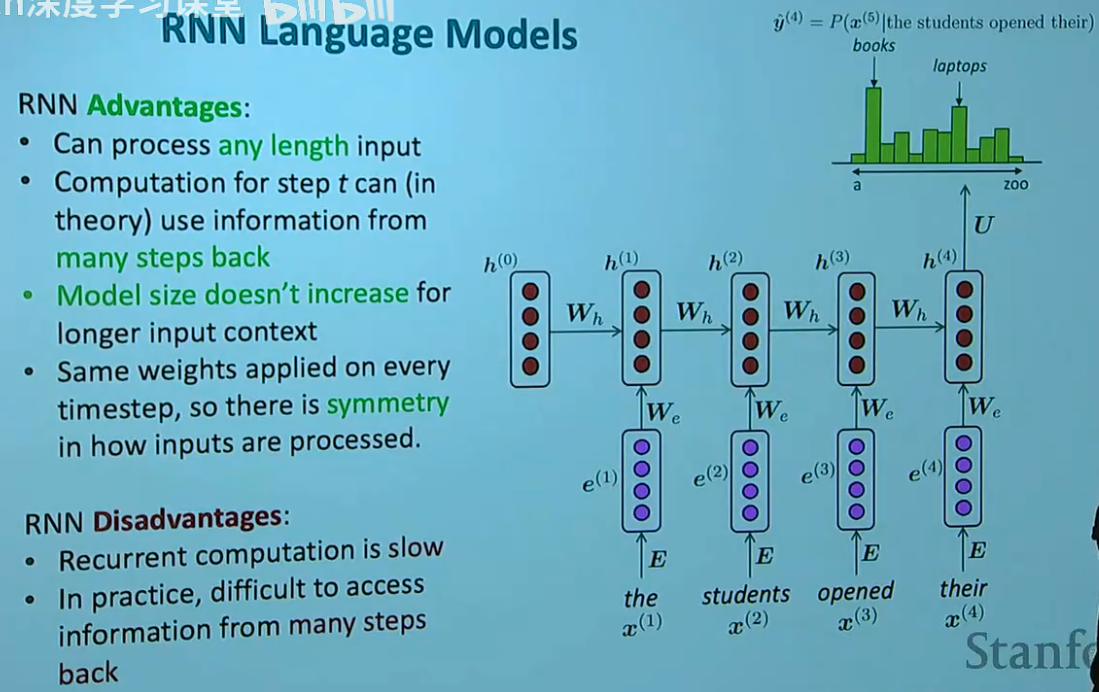
处理任意长度:无论句子由 5 个词还是 50 个词组成,模型架构始终如一。
长程依赖(理论上):由于 $h(t) 的存在,第 t 步的预测可以利用许多步之前的历史信息。
参数效率:参数 Wh, We, U 在所有时间步都是共享的,这使得模型非常精简。
第三节:损失函数与 Teacher Forcing
训练一个 RNN 语言模型的过程,本质上是教会模型在给定之前所有单词的情况下,最大化正确预测下一个单词的概率。
3.1 损失函数:交叉熵 (Cross-Entropy)
在每一个时间步 t,模型都会输出一个概率分布 ^y(t)。而我们手中拥有语料库中的真实单词 x(t+1)。
为了衡量模型的预测有多准,我们使用交叉熵损失函数。

单步损失:在第 t 步,损失值 J(t)(θ) 是预测分布 ^y(t) 与真实单词的独热向量 y(t) 之间的交叉熵。实际上,它等同于真实单词对应位置概率的负对数 -log ^y(t)xt+1。
总体损失:我们将整个训练集(或一个句子)中所有时间步的损失取平均值,得到最终需要优化的 J(θ)。
3.2 训练利器:Teacher Forcing
在训练 RNN 时,我们采用一种名为 “Teacher Forcing” 的策略。
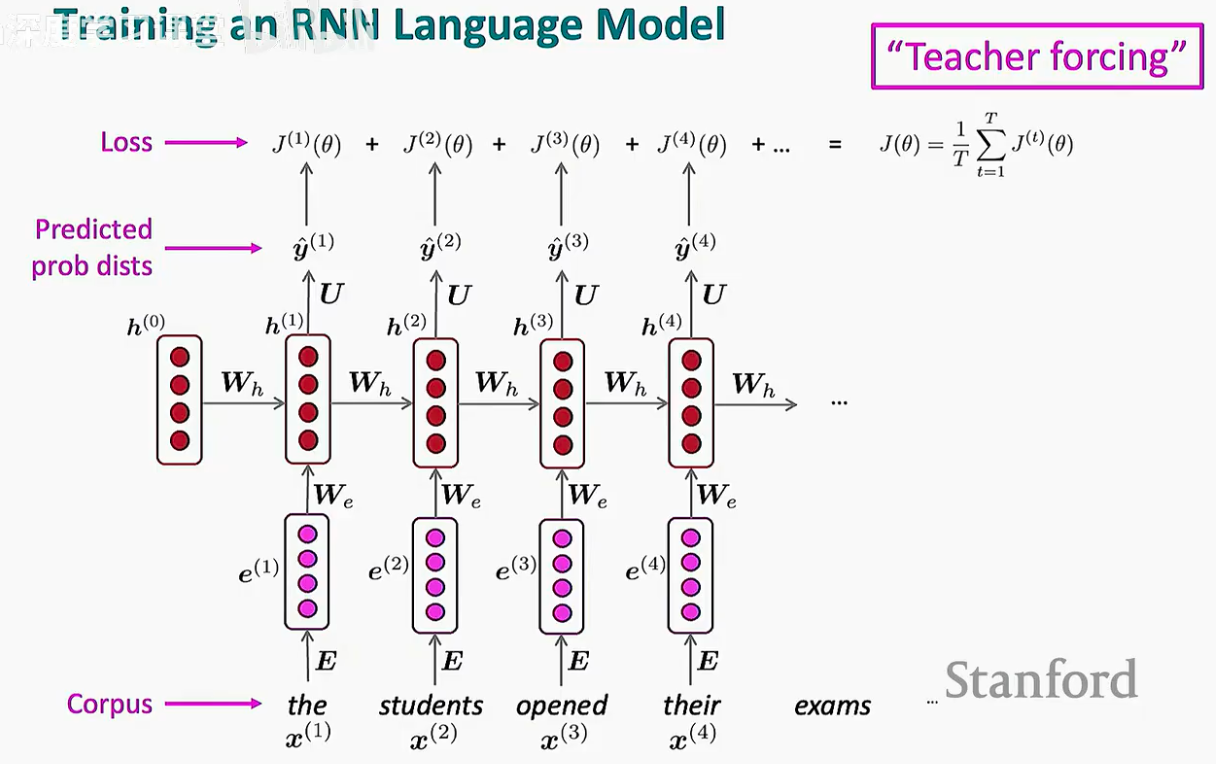
这种方法的逻辑是:在训练阶段,即使模型在 t=1 时预测错了(比如把 "the" 预测成了 "a"),在 t=2 时,我们依然强行将真实的单词 "students" 喂给模型。这就像有一位老师在旁边,实时纠正学生的错误,防止错误在序列中累积,从而加快模型的收敛速度。
3.3 内存开销与小批量训练 (SGD)
虽然理论上我们可以一次性计算整个语料库的损失,但在工程实践中这是不可行的。

内存瓶颈:由于 RNN 的计算链条很长,保存所有时间步的中间变量(用于后续计算梯度)会迅速耗尽显存。
解决方案:我们通常将语料库切分为一个个句子(Sentence)或文档(Document),并使用随机梯度下降(SGD)。我们会计算一个 Batch(批次)句子的损失 J(θ),更新一次权重,然后周而复始。
第四节:随时间反向传播 (BPTT)
在 RNN 中,更新参数的算法被称为 随时间反向传播(Backpropagation Through Time, BPTT)。
4.1 梯度的累加规律
当我们计算总损失 J(t) 对权重矩阵 Wh 的偏导数时,必须考虑到 Wh 在时间轴上的每一次“现身”。
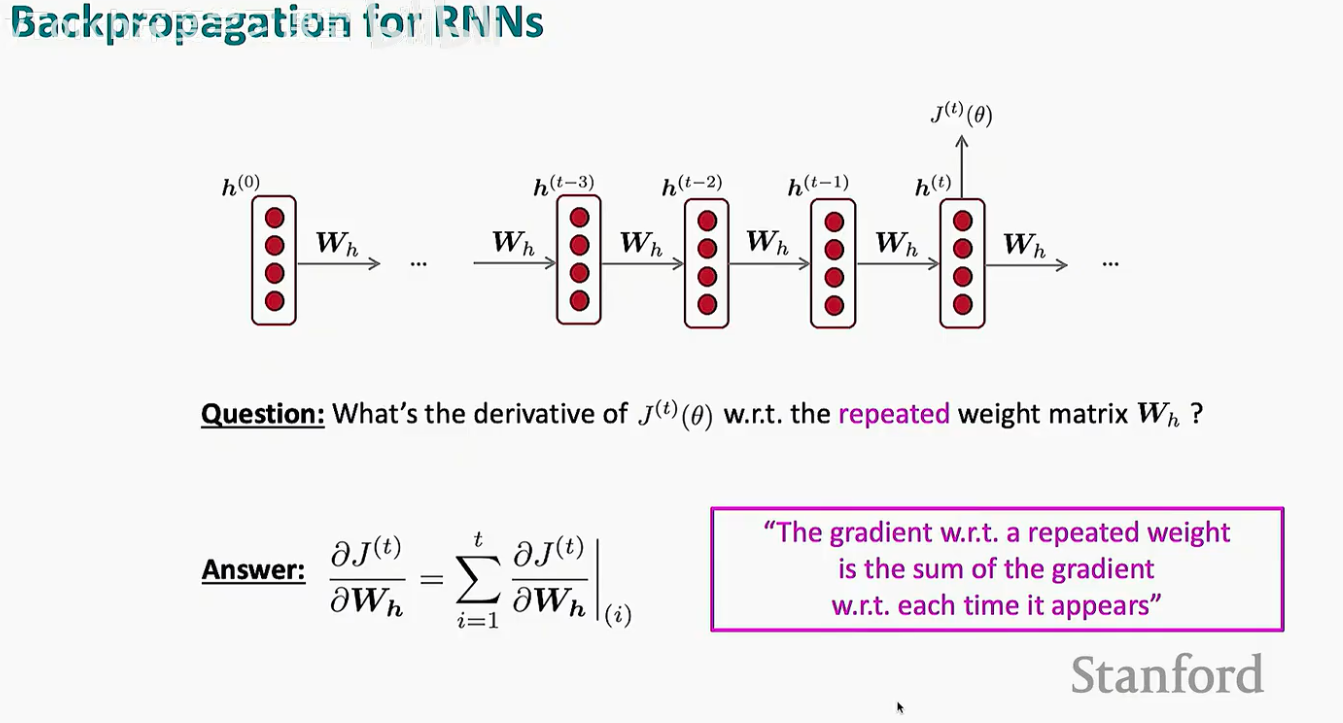
数学推导告诉我们:
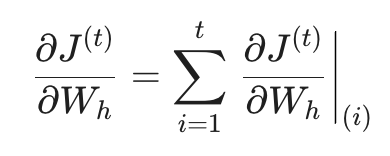
这意味着,为了更新 Wh,我们需要沿着时间轴一路向后回溯,把从当前时刻 t 到初始时刻 1 的所有梯度贡献全部累加起来。
4.2 多元微积分链式法则的应用
由于 h(t) 取决于 h(t-1),而 h(t-1) 又取决于 h(t-2),梯度的回传就像在推导一连串的多米诺骨牌。

通过多变量链式法则,我们可以清晰地看到梯度是如何流动的。每一时刻的记忆都在为最终的预测做贡献,因此每一时刻的参数也都应该根据最终的误差进行调整。
4.3 现实中的挑战:截断式 BPTT (Truncated BPTT)
在处理极长序列(例如一整本书)时,BPTT 会面临两个严重问题:
计算极其耗时:每更新一次参数都要回溯到序列开头。
梯度消失/爆炸:梯度在长距离传播中会不断连乘,导致数值变得极小或极大(我们将在后续章节详细讨论)。
实践技巧:为了保持训练效率,我们通常会进行“截断”。例如,只向前回溯 20 个时间步左右。虽然这牺牲了模型捕捉超长距离依赖的能力,但极大地提升了训练的稳定性。
第五节:文本生成
在训练阶段,我们使用了 Teacher Forcing。但在生成阶段,模型必须学会“独立行走”。
5.1 生成机制:反复采样(Repeated Sampling)
RNN 生成文本的过程被称为 “Generating roll outs”。它的核心逻辑是一个循环:
输入起始词:给模型一个起始符号(如
<s>)。预测分布:模型输出下一个词的概率分布 ^y(1)。
采样(Sample):我们根据这个概率分布随机抽取一个词(例如抽到了 "my")。
反馈循环:关键点来了! 我们将刚才抽到的词 "my" 作为下一步的输入喂回给模型,生成 ^y(2)。
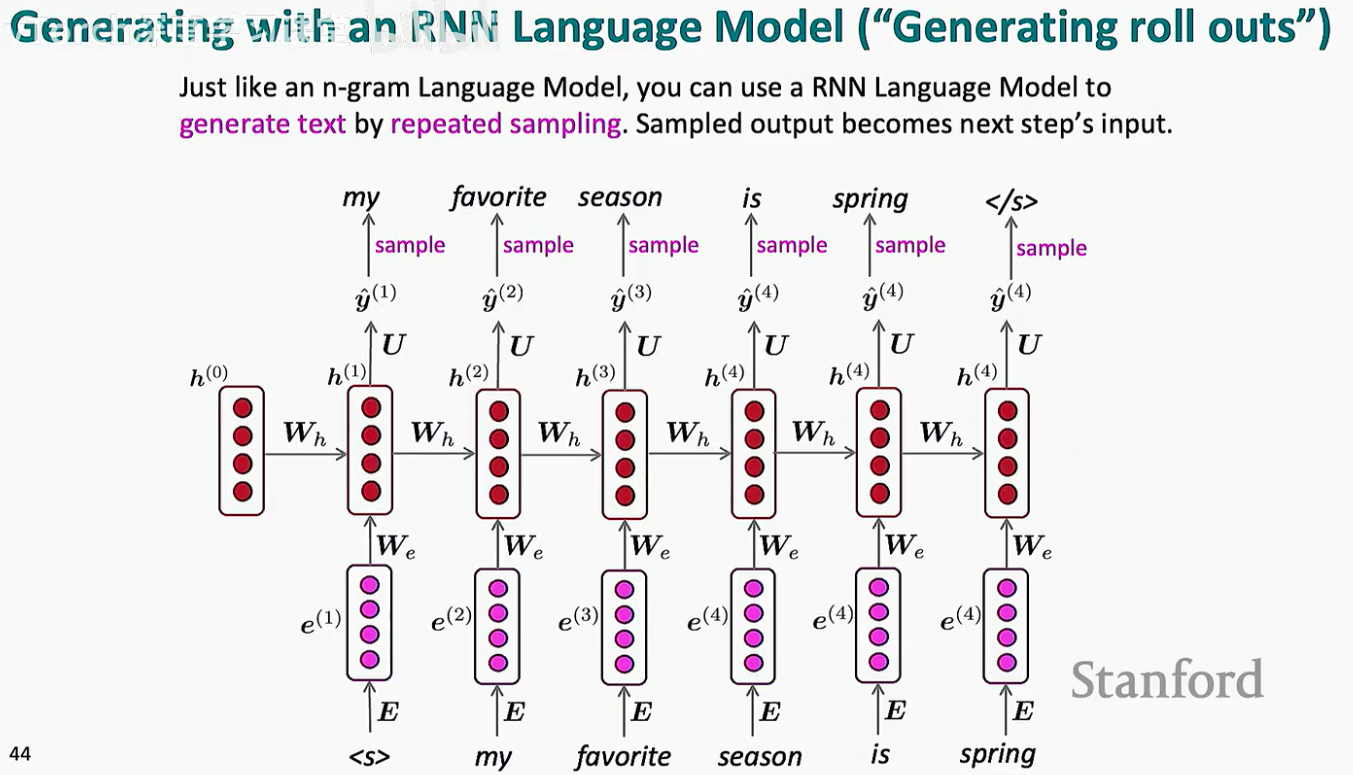
这个过程会一直持续下去,直到模型输出了停止符号(如 </s>)或者达到了预设的长度上限。
5.2 风格迁移:不仅仅是预测
由于 RNN 学习的是概率分布,它会捕捉到训练语料中特有的遣词造句风格。如果你用莎士比亚的剧本训练它,它会写出优美的十四行诗;如果你用代码训练它,它能写出看起来有模有样的 C 语言函数。
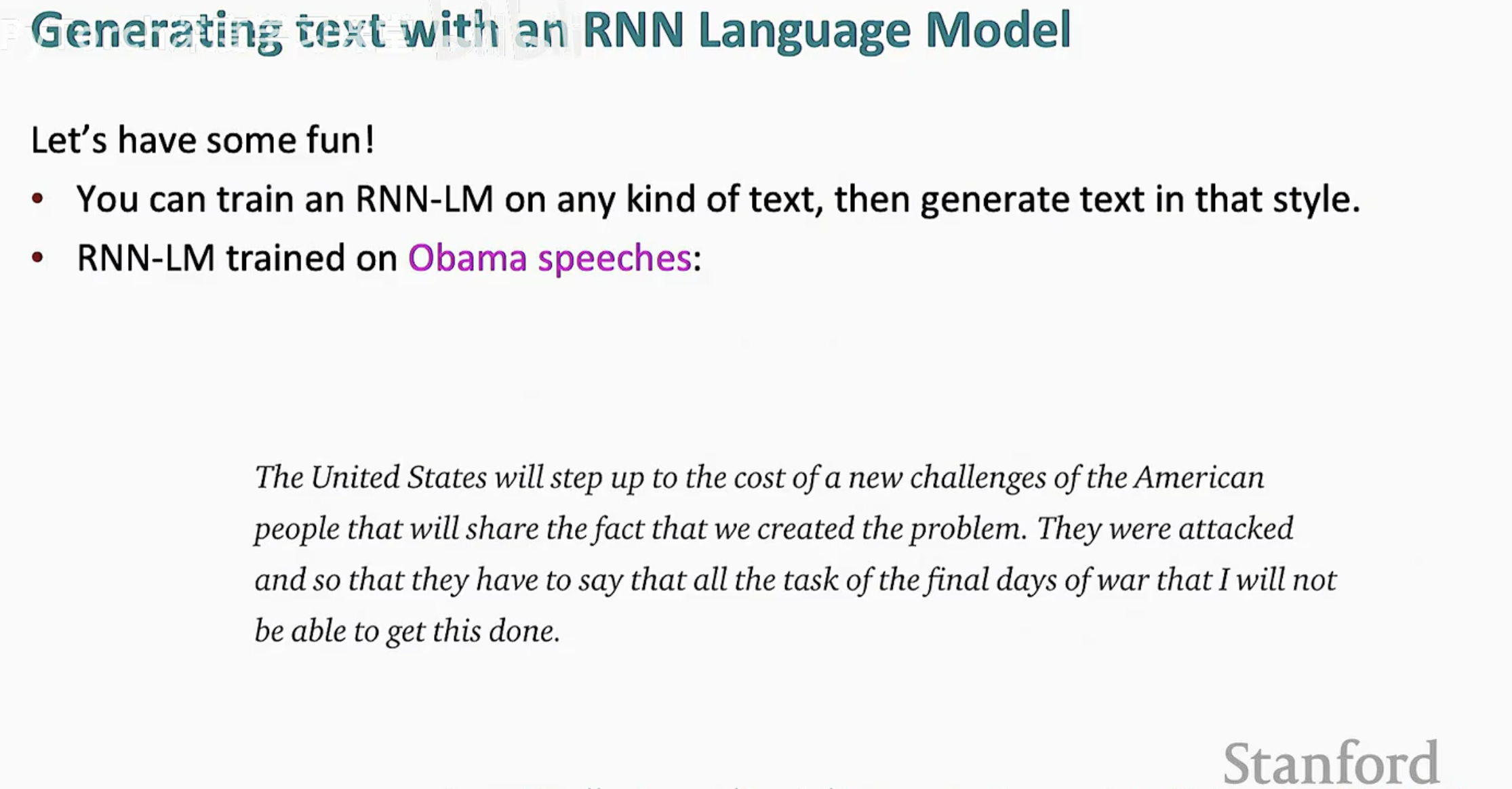
正如上图所示,虽然生成的内容在逻辑上可能不够连贯(毕竟它只关注局部的概率),但其语法结构和用词风格却模仿得惟妙惟肖。

5.3 从生成到创作
这种“根据上文预测下文”的能力,是现代大语言模型(如 GPT 系列)最基础的基因。虽然现代模型使用的是更复杂的 Transformer 架构,但其自回归生成(Autoregressive Generation)的核心思想,依然源自于我们今天讨论的 RNN。