
第一节: 什么是语言模型? (Language Model Recap)
在深入探讨如何评价一个模型之前,我们首先需要明确:我们要评价的对象究竟是什么?
1.1 核心定义:预测未来
从本质上讲,语言模型 (Language Model, LM) 是一个极其简单的系统:它只做一件事——预测下一个词 (Predicts the next word)。
给定一段文本序列,语言模型会计算出每一个可能出现的词在当前语境下的概率分布。例如,当我们输入“我爱学习”时,一个优秀的语言模型会给“自然语言处理”或“深度学习”分配较高的概率,而给“挖掘机”分配较低的概率。
1.2 RNN 与 语言模型:工具与任务的关系
在学习过程中,我们经常将 循环神经网络 (RNN) 与语言模型放在一起讨论,但必须明确:RNN $\neq$ 语言模型。
RNN 是一种架构 (Family of neural networks):它的特点是可以处理任意长度的序列输入,并在每个时间步应用相同的权重。它可以被用来做翻译、做情感分析,甚至用来预测股票。
语言模型是一种任务 (Task):任何能够估计文本概率或生成文本的模型都可以称为语言模型。
虽然 RNN 因为其天然的序列处理能力,曾是构建语言模型的主流工具,但语言模型也可以通过 $n$-gram 或如今风靡全球的 Transformer 架构来实现。
1.3 现代 NLP 的基石
过去,语言建模仅被视为许多 NLP 任务(如语音识别、机器翻译)中的一个子组件。然而,随着深度学习的发展,情况发生了根本性的变化。
现在的 NLP 领域几乎完全重构在语言建模之上。从某种意义上说,“预测下一个词”已经成为了通往通用人工智能的路径。正如 GPT-3,它的本质就是一个体量巨大的语言模型。

第二节:困惑度定义
既然语言模型的核心是预测概率,那么评价模型好坏最直接的标准就是:它给测试集中的真实文本分配了多大的概率?
一个完美的模型应该能以 100% 的确定性预测出下一个词;而一个糟糕的模型则会感到“困惑”。为了量化这种“困惑”程度,我们引入了困惑度 (Perplexity)。
2.1 直观理解:分支因子
从直观上看,困惑度可以理解为模型在预测下一个词时,平均面临多少个“等可能性”的选择。
如果困惑度是 10,说明模型在预测时,其不确定性相当于在 10 个等可能的备选词中做选择。
困惑度越低,说明模型越确定,模型质量也就越高。
2.2 形式化定义
在数学上,困惑度被定义为测试集概率的倒数,并根据序列长度 T 进行了几何平均(归一化)。
其公式如下:

这里的逻辑非常优美:
取倒数:我们希望 PLM(概率)越大越好,那么它的倒数(困惑度)就是越小越好。
累乘:代表整个语料库(Corpus)发生的总概率。
1/T 次方:由于不同句子的长度不同,直接比概率大小是不公平的。通过开 T 次方根,我们得到了每个词的平均概率倒数,从而让不同长度的文本具有可比性。
2.3 为什么使用几何平均?
可能会好奇,为什么不是简单的算术平均?在处理概率问题时,由于概率是连乘的关系,几何平均能更好地反映模型在整个序列上的平均性能,防止某个极小概率的词(模型极度意外的情况)导致整个评价指标剧烈波动。
第三节:困惑度与交叉熵 (Cross-Entropy) 的深层联系
在实际训练深度学习模型时,我们通常不会直接优化“困惑度”,而是最小化交叉熵损失函数 $J(\theta)$。那么,我们在 TensorBoard 里看到的 Loss 值,和这篇博客讨论的 Perplexity 之间到底是什么关系?
3.1 对数大法:从乘积到求和
由于计算机在处理大量小概率连乘时容易产生“算术下溢”(数值变得无限接近于零),数学家和工程师更倾向于在对数空间下操作。
通过对困惑度公式取对数,我们可以将原本复杂的几何平均转化为算术平均:
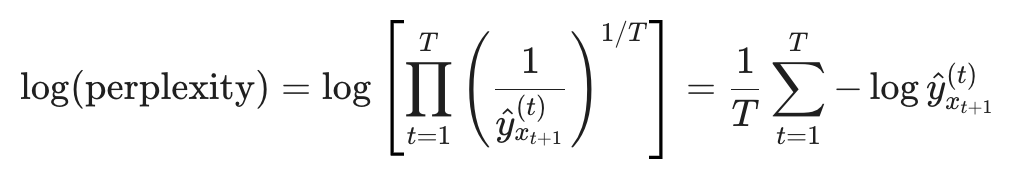
观察等式右边,这恰恰就是我们在训练模型时定义的平均交叉熵损失 J(θ)。
3.2 指数关系:exp J(θ)
通过上面的推导,我们可以得出一个极其重要的结论:困惑度实际上就是交叉熵损失的指数函数。
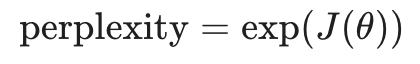
这意味着:
如果模型交叉熵损失 J(θ) = 0,那么困惑度为 e0 = 1(代表完美预测,毫无困惑)。
交叉熵损失越小,困惑度就越低,模型对语言的建模能力就越强。

3.3 为什么我们需要两个指标?
既然它们互为函数关系,为什么不只看 Loss?
直观性:Loss 是一个抽象的数值,而困惑度具有物理意义(即前文提到的“分支因子”)。告诉别人“模型在 10 个词里犹豫”比说“Loss 是 2.3”要形象得多。
历史传承:在深度学习兴起之前,NLP 领域就已经广泛使用困惑度来评价 n-gram 模型了。
第四节:案例对比:从 n-gram 到深度 RNN 的演进
理论上的推导最终需要回归到实验数据的验证。为了证明 RNN 及其变体在语言建模上的优越性,研究人员通常会将它们与传统的统计模型进行困惑度(Perplexity)的横向对比。
4.1 基准线:传统的 n-gram 模型
在深度学习普及之前,Interpolated Kneser-Ney (KN) 5-gram 被视为语言建模的黄金标准。在典型的语料库(如 Chelba et al., 2013 的研究)中,这种模型的困惑度大约在 67.6 左右。
这意味着,即使是当时最顶尖的统计模型,在预测下一个词时,其不确定性依然相当于在约 68 个等可能的选项中做抉择。
4.2 RNN 的突破
随着循环神经网络的引入,这一数字开始大幅下降。通过下表我们可以观察到技术的迭代轨迹:

4.3 数据背后的逻辑
从表中我们可以读出两个核心趋势:
架构的红利:从简单的 RNN 到 LSTM (Long Short-Term Memory),困惑度从 50 多降到了 40 左右。这是因为 LSTM 能够更好地捕捉句子长距离的语义关联(例如,段首的主语决定了段末的谓语形式)。
规模的力量:当我们观察“Ours small”与“Ours large”的对比时,可以发现仅仅通过增加层数(从 1 层到 2 层)和参数量,困惑度就从 43.9 优化到了 39.8。这一逻辑在后来的 GPT 系列模型中被发挥到了极致——通过海量参数进一步压低困惑度。
4.4 结论:越低,越懂人类
表格右侧的绿色箭头直观地告诉我们:困惑度越低,性能越好。每一次困惑度的下降,都代表着模型离人类的表达习惯又近了一步,预测变得更加精准。