
一、强化学习定义
强化学习(Reinforcement Learning, RL)是一种机器学习方法,它强调智能体(Agent)通过与环境(Environment)的交互来学习。智能体在每个时刻会根据当前的状态(State, s)选择一个动作(Action, a),环境则会反馈一个奖励(Reward, r)以及下一个状态。通过不断尝试与反馈,智能体逐渐学会一个策略(Policy),从而最大化长期回报。
强化学习不同于监督学习,它没有“标准答案”可以直接参考,而是通过试错和反馈来优化行为。也不同于无监督学习,因为它有明确的目标:最大化累积奖励。
在这一过程中,有几个核心要素:
状态(State, s): 环境的描述,比如棋盘布局、机器人位置。
动作(Action, a): 智能体在某一状态下能采取的行为。
奖励(Reward, r): 环境对动作的反馈,可能是正数(鼓励)也可能是负数(惩罚)。
策略(Policy, π): 智能体的决策规则,定义在某一状态下选择哪个动作。
价值函数(Value Function): 衡量状态或动作未来累积回报的期望值。
总结来说,强化学习的关键就在于:智能体如何通过不断探索和利用经验,学会最优的策略,从而在复杂的环境中做出良好的决策。
二、从直升机控制到强化学习
在强化学习的早期研究中,一个典型案例就是自主直升机(Autonomous Helicopter)的控制问题。直升机本身是一个非常复杂的动态系统,要让它在空中平稳飞行,需要同时处理多个维度的信息:
GPS:提供位置坐标。
加速度计(Accelerometers):检测加速度和姿态变化。
罗盘(Compass):提供航向信息。
机载计算机(Computer):实时处理传感器数据并决定控制动作。

问题在于:即使有了这些传感器,如何操纵直升机仍然十分困难。传统方法依赖专家设计算法控制每一个细节,而强化学习则提供了新的思路:通过试错学习飞行策略。
在强化学习框架下:
状态 s:直升机的位置、速度、角度等参数。
动作 a:控制杆的移动,例如上升、下降、左转或右转。
奖励 r:如果直升机保持平稳飞行,则给正奖励(+1);如果飞行不稳定甚至坠毁,则给负奖励(-1000)。
这样,直升机不再需要明确的控制公式,而是通过不断试验和反馈,学习到在各种情况下如何调整动作,最终实现稳定飞行。
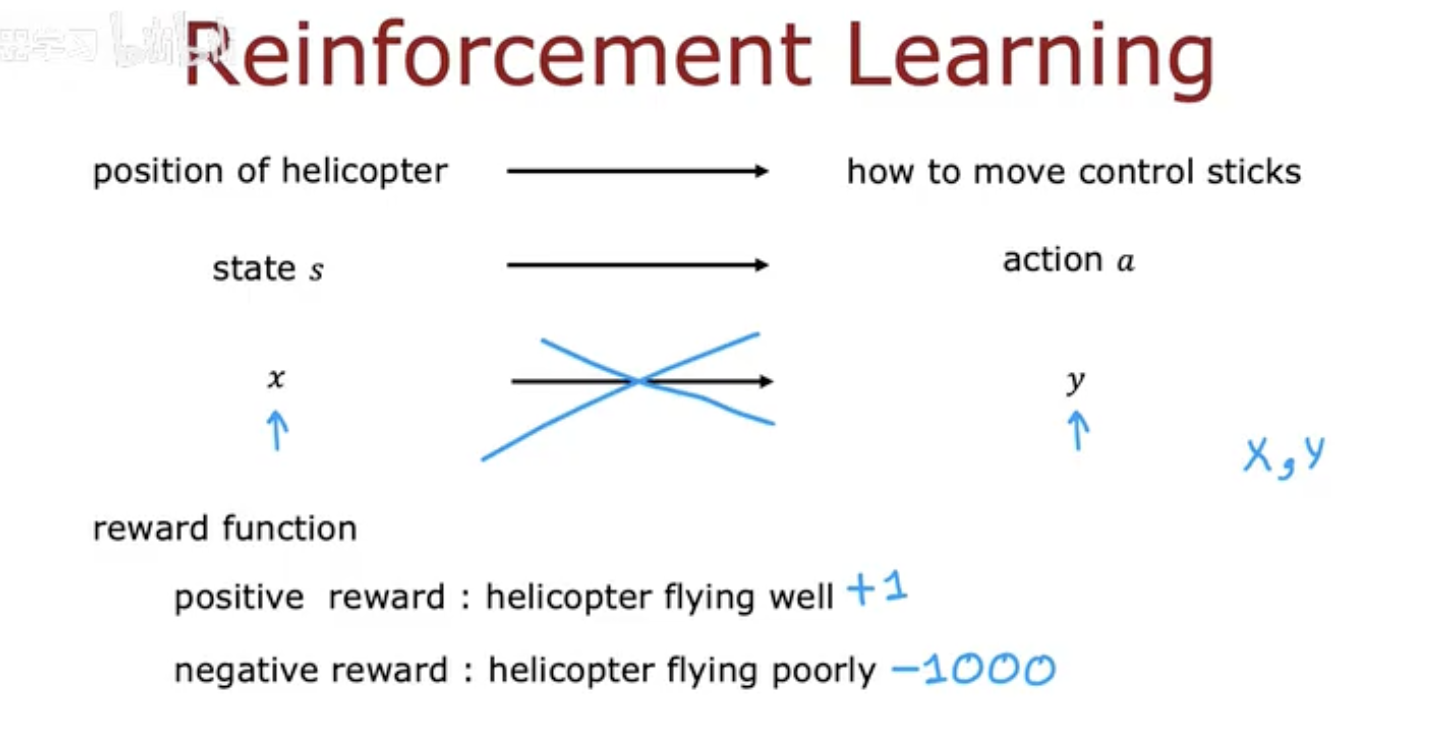
这个案例很好地展示了强化学习的本质:即便在复杂的动态系统中,智能体也能通过与环境的交互逐渐改进决策。
三、强化学习的应用场景

强化学习并不仅仅停留在学术实验或直升机控制的案例中,它在现实世界中有着广泛的应用场景:
机器人控制(Controlling robots)
机器人在复杂环境中需要做出连续决策,例如机械臂的抓取动作、四足机器人在不平地形上的行走。强化学习能让机器人通过试错逐渐找到最优策略,从而适应各种复杂环境。工厂优化(Factory optimization)
在现代工业中,生产线如何调度、资源如何分配往往会直接影响效率和成本。强化学习能根据历史数据和实时反馈不断调整策略,实现自动化的优化调度。金融交易(Financial trading)
金融市场充满不确定性。通过强化学习,智能体可以在模拟环境中学习买卖股票的策略,在风险与收益之间找到平衡。游戏(Playing games)
从国际象棋、围棋到电子游戏,强化学习已经展现了惊人的成果。AlphaGo 就是经典案例,它通过自我对弈学习到超越人类顶尖选手的下棋策略。
四、火星探测车与强化学习流程
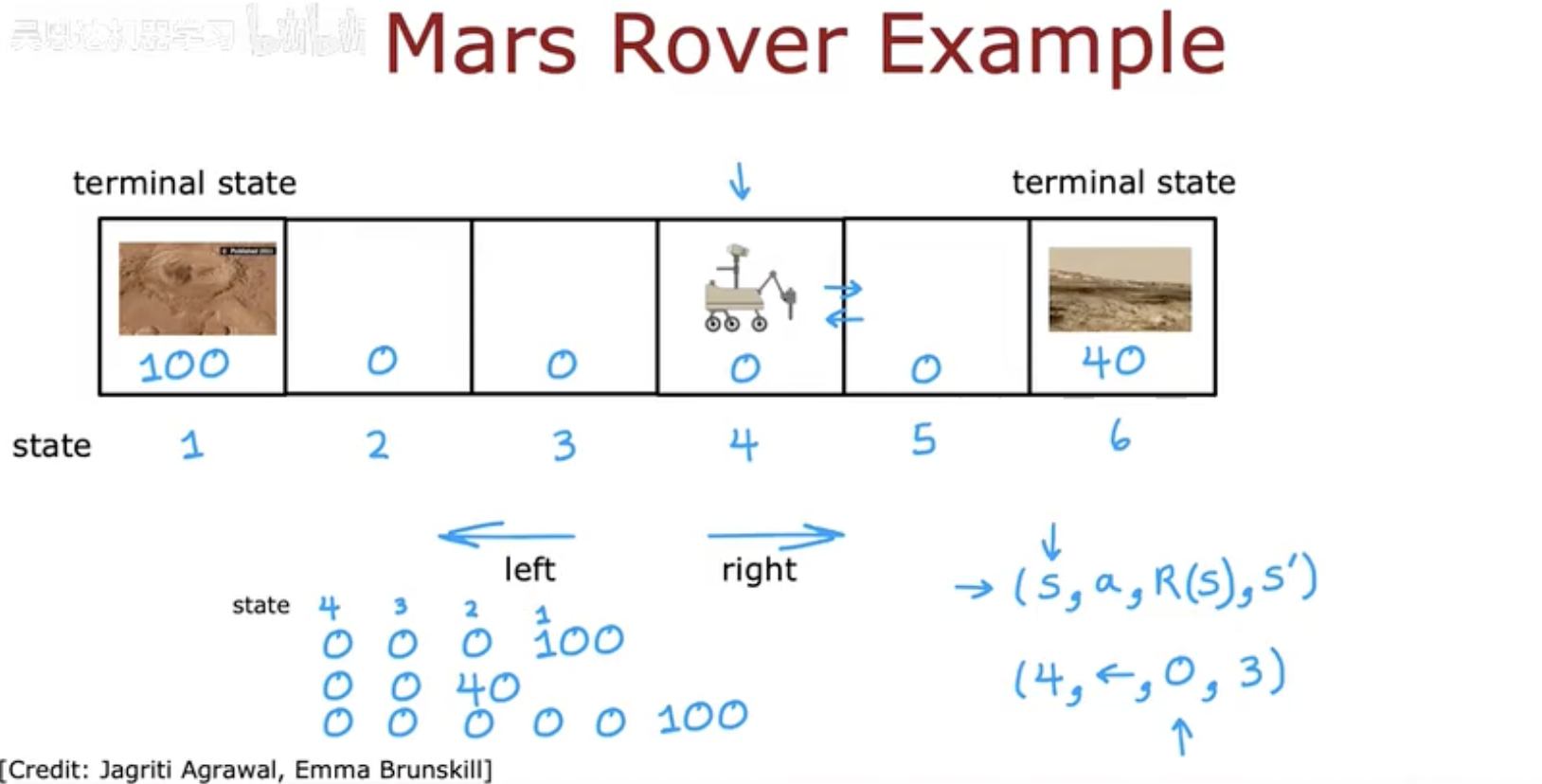
为了更直观地理解强化学习的运行机制,可以用一个简化版的火星探测车(Mars Rover)探索任务来说明。
4.1 环境设置
想象一个格子世界,每个格子代表 Rover(探测车)可能处于的状态:
有些格子是普通的安全区域;
有些格子是危险区域(如悬崖边),一旦进入就会得到负奖励;
有些格子是目标点(如科研价值高的地点),进入后会得到正奖励。
4.2 强化学习循环
在这个环境中,Rover 的交互循环可以总结为:
状态 (State, s): Rover 当前所在的格子位置。
动作 (Action, a): Rover 可以选择上下左右移动。
奖励 (Reward, r): 移动到普通区域奖励为 0,到危险区为 -10,到目标点为 +100。
新状态 (Next State, s′): Rover 执行动作后到达的新格子。
4.3 策略的改进
初期 Rover 会随机探索,经常进入危险区域而受到惩罚。
随着经验的积累,它会更新“价值函数”(Value Function),逐渐学会避免危险并朝目标点移动。
最终形成的策略会让 Rover 最大化长期奖励,而不是只考虑眼前的即时收益。
这一过程清晰地展示了强化学习的精髓:通过不断试错,逐渐从混乱探索走向高效决策。
五、挑战与展望
尽管强化学习在理论和应用上都取得了巨大的进展,但要在更多实际场景中普及,它仍然面临不少挑战:
5.1 主要挑战
训练过程不稳定
强化学习往往需要在高维、复杂的环境中探索。即便是相同的环境和参数,训练的结果也可能存在较大差异。计算成本高
大多数强化学习算法需要大量的交互数据和计算资源。例如 AlphaGo 的成功依赖于海量自我对弈数据和强大的算力支持。奖励稀疏问题
在很多任务中,正向奖励很少出现(例如游戏只在通关时奖励一次),这会导致智能体在训练初期难以学到有效策略。探索与利用的平衡
智能体需要在“尝试新策略”(探索)与“利用已知策略获得奖励”(利用)之间找到合适的平衡,这是强化学习中的经典难题。
5.2 未来展望
深度强化学习(Deep Reinforcement Learning, DRL)
结合深度神经网络与强化学习,提升对高维感知信息(如图像、视频)的处理能力,已在 Atari 游戏和机器人任务中大放异彩。多智能体强化学习(Multi-Agent RL, MARL)
在交通调度、博弈系统、协作机器人等领域,多智能体之间的竞争与合作问题将是重要的发展方向。与现实世界的结合
强化学习正逐步应用于自动驾驶、智能制造、个性化推荐和医疗诊断。未来,如何让强化学习模型在真实环境中安全、可靠地运行,将是一个重要课题。更高效的算法与样本利用
如何减少训练对海量数据和计算资源的依赖,是推动强化学习落地的关键。
总的来说,强化学习是人工智能领域最具潜力的分支之一。它为智能体提供了一种全新的学习范式:通过与环境的持续交互,不断试错,最终找到最优的决策方式。随着深度学习、计算资源和算法理论的不断发展,强化学习将在更多现实场景中发挥重要作用。