
一、引言
在强化学习(Reinforcement Learning, RL)中,智能体(Agent)与环境(Environment)不断交互,通过采取动作获得奖励,并逐步学习如何优化自己的策略。然而,单个奖励往往不能全面反映一次决策的好坏,因为它只描述了当前一步的反馈。为了更准确地衡量智能体的长期收益,我们需要一个更全面的度量指标——回报(Return)。
回报可以看作是从某个状态出发,智能体在未来一系列动作中所能累计获得的奖励总和。它不仅仅考虑眼前的收益,还引入了对未来奖励的折扣,从而在“短期回报”和“长期回报”之间建立平衡。这一概念在强化学习中具有核心地位,因为智能体的目标就是学习一个策略,使得其期望回报最大化。
在接下来的章节中,我们将从回报的数学定义出发,逐步探讨折扣因子的作用,并通过实例演示不同折扣系数对回报计算的影响。
二、回报的定义
在强化学习中,回报(Return, G) 通常定义为从某个状态开始,智能体在后续步骤中能够获得的奖励的加权和。具体来说,如果从时间步 tt 开始,奖励序列为 Rt+1,Rt+2,Rt+3,…,那么回报可以写为:
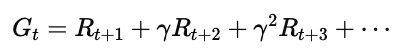
其中,γ 是折扣因子(Discount Factor),取值范围为 0≤γ≤1。它控制着智能体对未来奖励的重视程度:
若 γ 接近 1:智能体更关注长期回报。
若 γ 较小:智能体更关注短期收益。
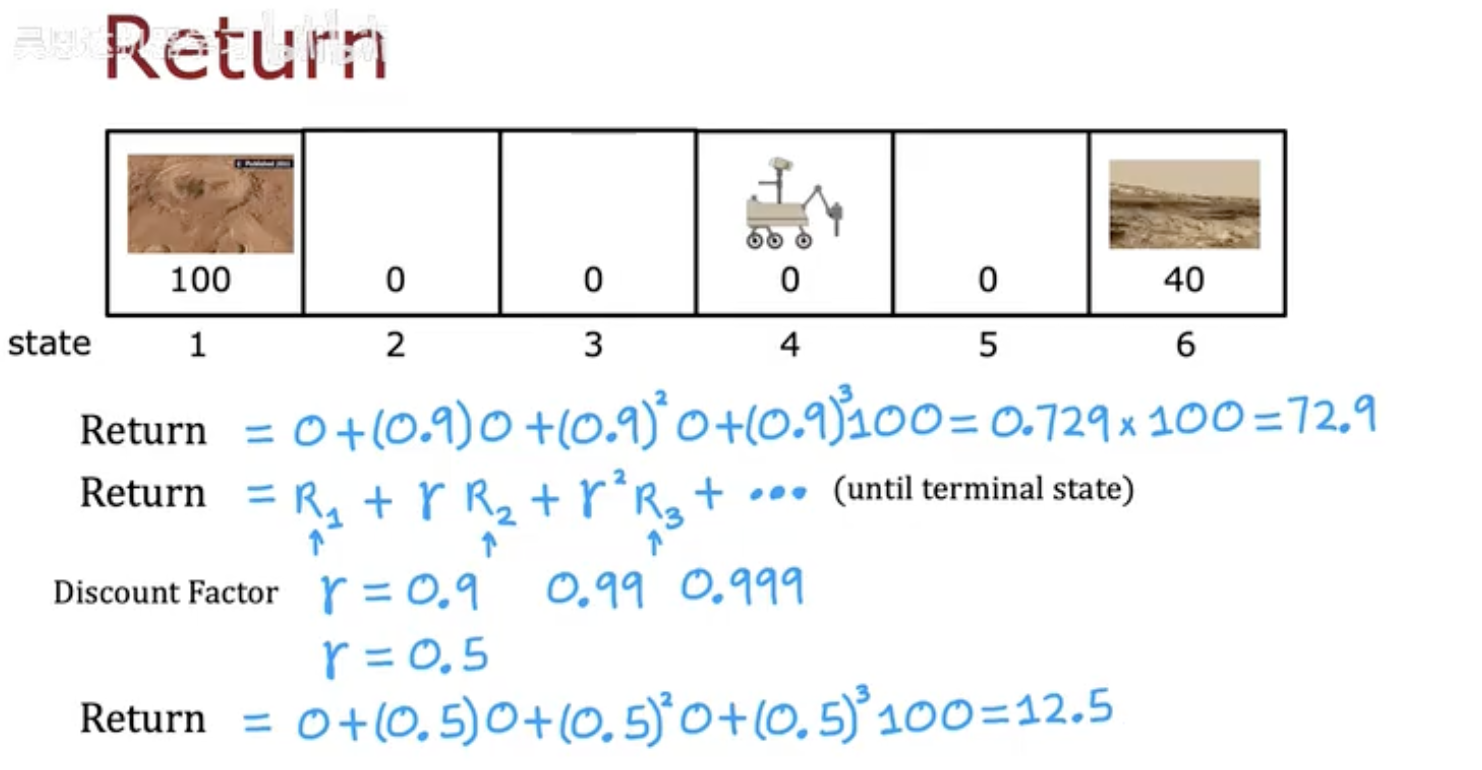
在第这张图中,我们看到一个简化的 Mars Rover 场景:
状态 1 的奖励是 100,状态 6 的奖励是 40,其余状态奖励为 0。
当折扣因子 γ=0.9 时,回报公式为:
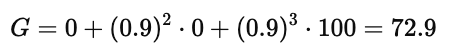
这说明即使最终奖励是 100,由于折扣的存在,智能体感知到的回报会下降为 72.9。
而当折扣因子改为 γ=0.5 时,远期奖励的价值下降更快:
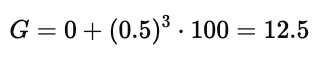
由此可见,折扣因子决定了智能体对未来奖励的“耐心”程度。
三、回报的计算示例

前面我们介绍了回报(Return)的基本公式,现在来看一个更具体的例子。
在图中,智能体仍处于 Mars Rover 场景:
状态 1 的奖励是 100,状态 6 的奖励是 40,其他状态奖励为 0。
折扣因子设为 γ=0.5。
示例一:从状态 4 出发向右移动
如果智能体从状态 4 出发,并选择向右移动,回报的计算如下:
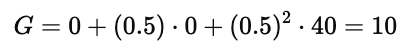
即智能体会获得折扣后的累计回报 10。
示例二:从状态 4 出发向左移动
如果智能体改为向左移动,那么路径上的回报计算为:
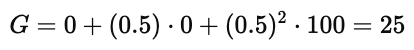
所以最终得到的回报是 25。
示例三:另一种路径(折扣效应更明显)
在图中下方的另一条路径中,智能体仍然能走到奖励为 40 的终点,但计算为:
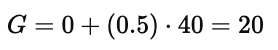
可见,虽然奖励数值相同,但由于所处状态不同、折扣位置不同,回报会发生差异。
四、折扣因子的意义
在回报(Return)的公式中:
折扣因子(Discount Factor, γ) 决定了智能体对未来奖励的重视程度。它的取值范围是 0≤γ≤1。
1. γ 的大小如何影响回报
γ 较大(接近 1)
未来奖励几乎不被削弱。
智能体会关注长期结果,更有“耐心”。
例如在第一张图中,γ=0.9 时,远处奖励 100 的折扣值仍有 72.9。
γ 较小(如 0.5)
未来奖励衰减得很快。
智能体更关注眼前的奖励,容易“短视”。
在第二张图中,γ=0.5,虽然终点奖励仍是 100,但折扣后只有 12.5 或 25,这远低于 γ=0.9 的情况。
2. 为什么要有折扣因子
防止无限回报
在无限步长的环境中,如果没有折扣,回报可能无限大,导致公式不收敛。更贴合现实
在很多实际问题里,未来的奖励总是存在不确定性或延迟价值,因此需要折扣来体现“未来奖励的价值较低”。调整决策风格
γ 大 → 长期规划,偏向积累经验。
γ 小 → 短期最优,更快获得回报。
简而言之,折扣因子就是用来调节“短期 vs 长期”偏好的关键参数,它让强化学习既能兼顾未来,又能避免无限增长的数学问题。
五、总结
在强化学习中,回报(Return) 是智能体决策优化的核心度量。它不仅仅是某一时刻的即时奖励,而是对未来一系列奖励的折扣加权和。通过回报的定义,智能体能够衡量一个策略在长期上能带来的收益,从而不断改进行为。
在这篇文章里,我们从公式出发,结合示例展示了:
回报如何通过未来奖励与折扣因子计算得到;
折扣因子 γ 的不同取值如何影响智能体的决策偏好;
为什么折扣因子在实际问题中不可或缺,它既保证了数学上的收敛,也帮助平衡短期收益和长期规划。
因此,回报不仅是强化学习的基本概念,更是智能体学习和优化策略的目标函数。理解回报的本质,是深入学习价值函数(Value Function)、策略优化(Policy Optimization)等强化学习高级主题的基础。