
一、引言
数据在现代分析、机器学习以及商业智能中扮演着核心角色。为了从数据中提取价值,我们不仅需要算法和工具,更需要理解数据本身的结构与形式。不同类型的数据集拥有不同的组织方式、特点和适用场景,因此在处理之前明确数据的类别是一项非常重要的前置步骤。
在数据挖掘与数据分析中,学者们通常会将数据集划分为若干基本类型,如记录型数据、图结构数据以及有序数据等。每一种类型都对应特定的应用场景与分析方法,例如记录型数据常出现在电子表格与数据库中,图结构数据支撑了网络分析与结构挖掘,而有序数据则是时间序列、空间数据和基因序列等任务的基础。

这张图展示了三大主要类别的概念结构:
Record(记录型数据),强调表格结构和属性字段;
Graph(图结构数据),用于描述网络关系,如网页链接图与分子结构;
Ordered(有序数据),适用于按空间、时间或序列排列的数据形式。
本章的内容将会作为全篇的开端,为后续的具体展开提供清晰的分类基础。接下来各章节会依次说明每一类数据集的概念、结构特点以及典型实例,并配合你提供的图片进行讲解,让内容更具可视化与可理解性。
二、记录型数据(Record Data)
Record Data(记录型数据)是最常见的数据集类型之一,它由一组记录组成,而每条记录都包含相同属性集合(attributes)的取值。可以把它理解为我们在数据库表格或 Excel 中常见的结构化数据:每一行是一个对象,每一列是一个属性。
2.1 记录型数据的基本结构
Record Data 的核心特点是:
数据以行(记录)和列(属性)的形式存储。
不同记录具有相同的属性集合。
属性可以是数值型、类别型或混合类型。
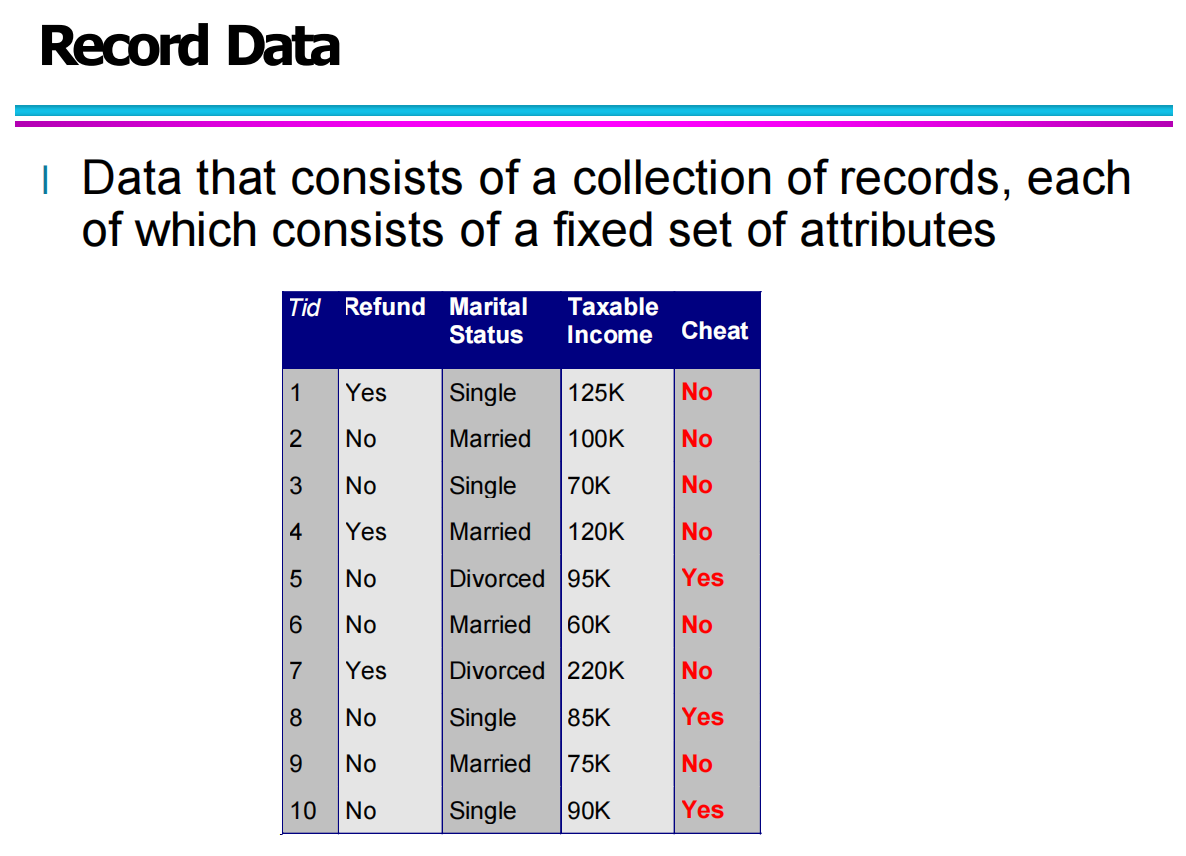
这一表格展示了典型的 Record Data,其中每一个 TID 对应一条记录,而 Refund、Marital Status、Taxable Income 等则是各条记录共享的属性。
2.2 Data Matrix:记录型数据的数值化形式
当所有属性都是数值型时,Record Data 会以“Data Matrix(数据矩阵)”的方式表示。
此时每条记录可以被看成是一个多维向量,而所有记录构成一个 m×n 的矩阵:
m:记录数
n:属性数
这使得数据非常适合进行数学建模,例如统计分析、聚类、回归或各种机器学习算法。

2.3 Record Data 与 Data Matrix 的比较
虽然 Data Matrix 是 Record Data 的一种子集,但两者之间仍有明显差别:
Record Data 允许属性类型混合,例如类别型(Married)、布尔型(Yes/No)与数值型(Taxable Income)共存。
Data Matrix 则要求所有属性都为数值型,因此更适合数学计算与模型训练。

2.4 Document Data:基于文本的记录形式
Document Data(文档数据)是 Record Data 的一种特殊变体,其中每条记录是一个文档(例如一句话、一篇文章)。
文档通常被表示为“词项向量(term vector)”,其元素为某个词在文档中出现的次数:
每个“词项”是一个属性
每个属性的值是词频(Term Frequency)

这种表示方法使得文本能够与传统的结构化数据保持兼容,并方便进行 NLP、信息检索或聚类分析等任务。
2.5 Transaction Data:基于集合的记录形式
Transaction Data(事务型数据)描述的是一组“项目集合”(itemset),常用于购物篮分析(Market Basket Analysis)。
每笔交易是一条记录
每条记录包含一个集合(如购买的商品列表)
属性数量不固定,因为不同交易的商品数量不同
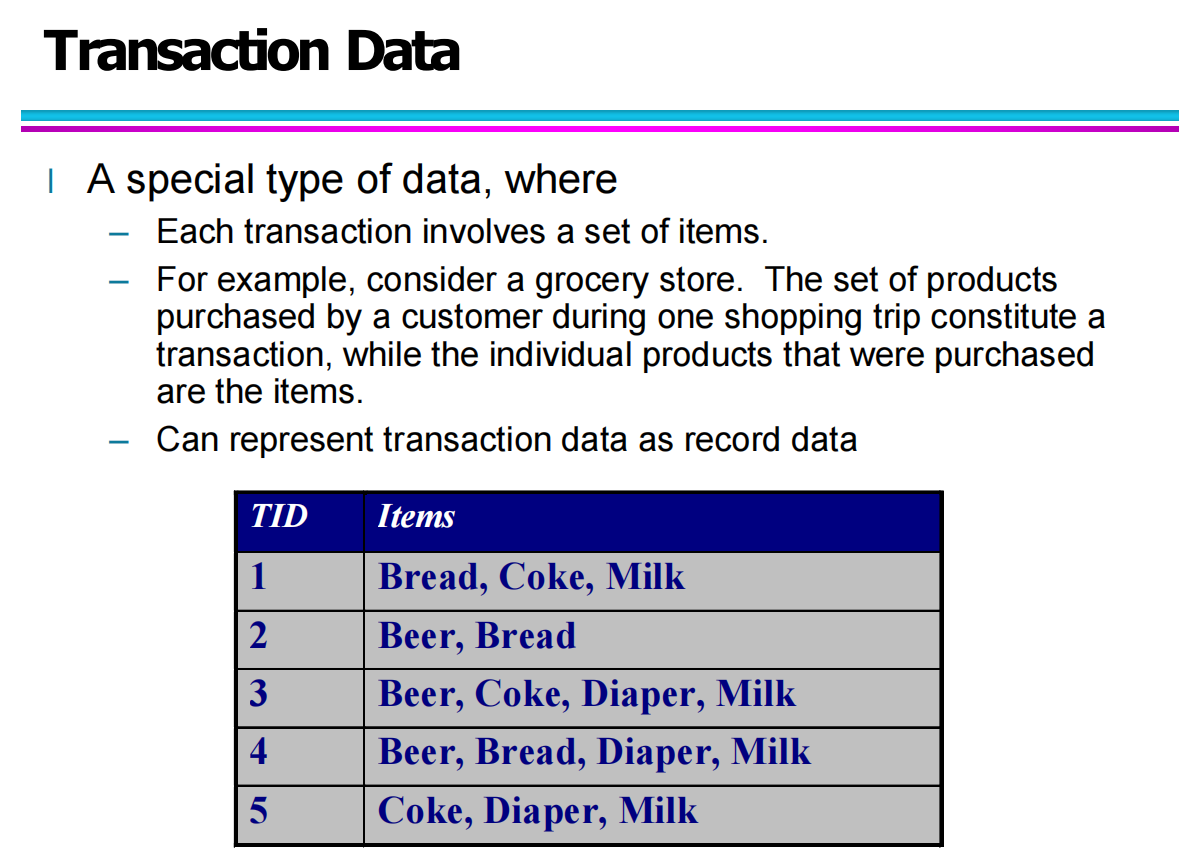
Transaction Data 无法用传统矩阵直接表示,但常用于关联规则挖掘,如 Apriori、FP-Growth 等算法。
2.6 四类 Record Data 的对比总结
Record Data、Data Matrix、Document Data 与 Transaction Data 虽都属于“记录型数据”,但结构形式不同,适用于不同的分析任务:


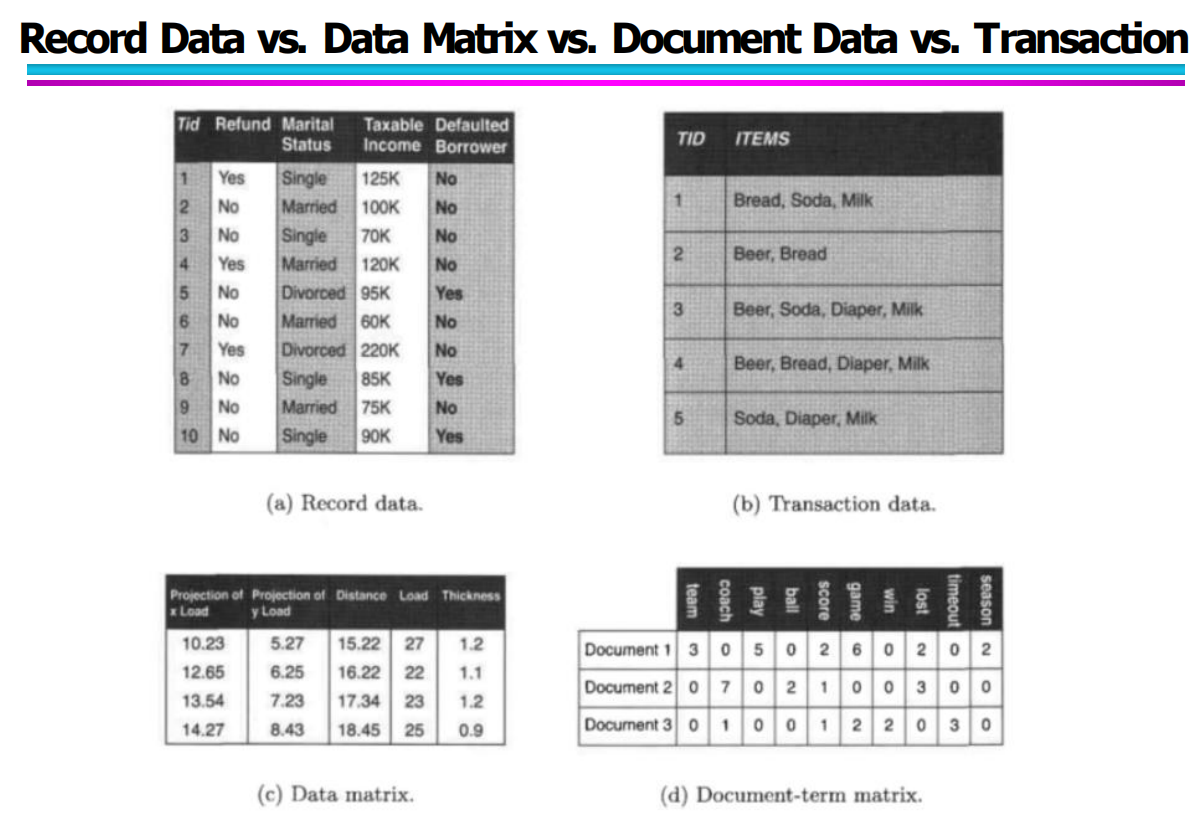
Record Data:属性丰富,可混合类别型与数值型
Data Matrix:全数值,适合统计和机器学习
Document Data:用词频向量表示文本
Transaction Data:用集合表示项目,用于关联规则分析
这些对比帮助我们理解不同数据结构的优势与应用场景。
三、图数据(Graph Data)
图数据描述由节点(Nodes)与边(Edges)组成的结构,用于表示实体及其关系。与表格型的数据不同,图数据能够自然表达连接性、交互性以及复杂结构,因此广泛应用于社交网络、化学分子建模和网络分析等场景。
3.1 Graph Data 的定义
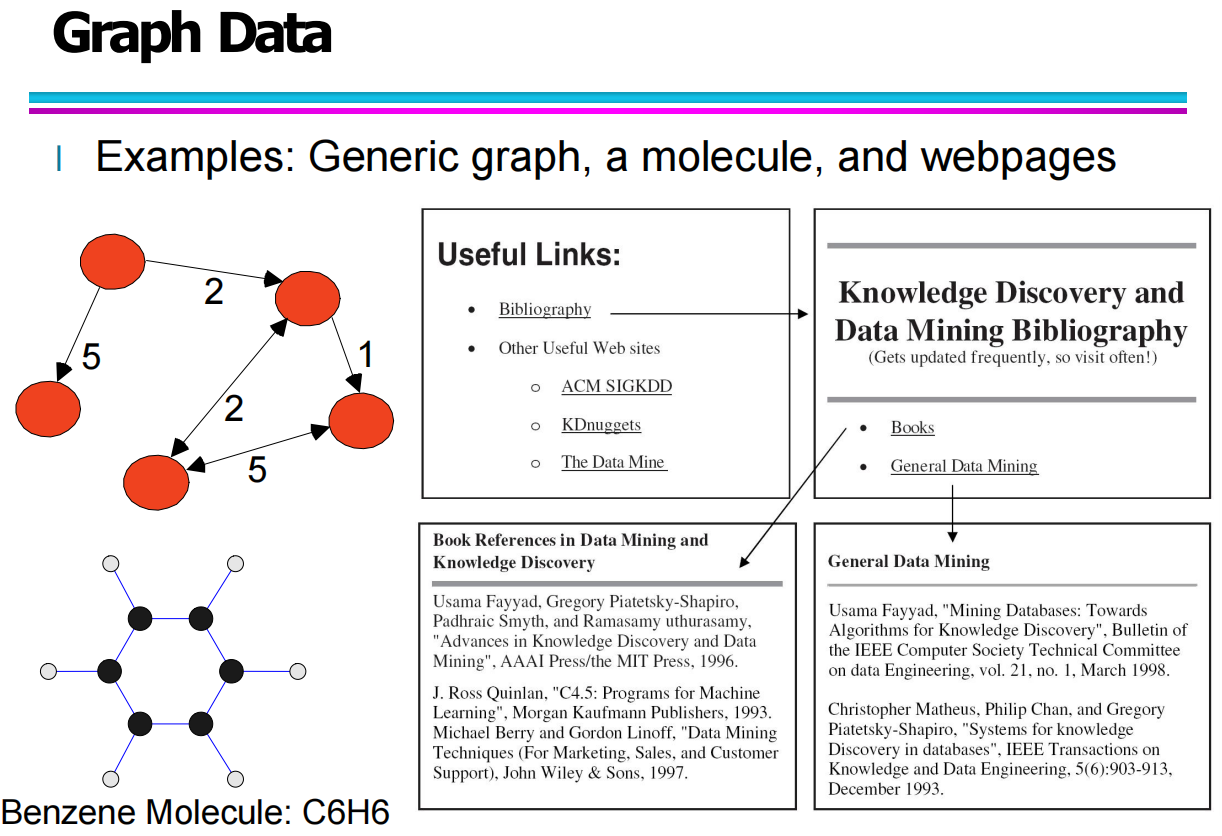
图数据由两部分组成:
节点(Vertices):用于表示实体,例如一个人、一篇网页、一个分子中的原子。
边(Edges):用于表示实体之间的关系,如好友关系、网页超链接或原子之间的化学键。
图数据的核心价值在于:它能自然表达结构化关系,而这些关系往往是模式识别、推荐与分析中的关键部分。

3.2 Graph Data 的特点与示例
图数据适合用于描述以下场景:
社交网络:每个用户是一个节点,好友关系表示为边。
化学结构:原子为节点,化学键为边(如苯环 C6H6)。
网页互联结构:网页为节点,超链接为边,用于表示页面跳转关系。
3.3 Graph Data 的优势
图数据结构具备许多天然优势,使其成为处理复杂关系数据的理想选择:
优秀的关系表达能力:图能够直观地表示实体之间的各种关系。
适用于复杂结构:可表达多对多关系、层级关系、循环结构等传统表格难处理的形式。
动态扩展方便:新增节点或边时,无需重新设计整体架构。
易于可视化:图结构天然适合绘制,可观察社区、团簇或结构模式。

3.4 Graph Data 的挑战
尽管图数据强大,但在实际应用中仍存在挑战:
大规模图难以处理:当节点与边数量巨大(如社交网络)时,计算复杂度很高。
存储占用大:尤其是密集图,大量边会带来巨量存储开销。
动态图处理复杂:节点和边频繁变化,会让计算模式与索引维护更加困难。

3.5 Graph Data 的常见应用领域
图数据被广泛应用于多个行业和研究方向,包括:
社交网络分析(Social Network Analysis):研究用户关系、社区结构、影响力传播等。
化学信息学(Cheminformatics):用于分析分子结构、药物设计或化学属性预测。
网络分析(Web Analytics):理解网页之间的链接结构,用于搜索引擎优化、网页排名算法(例如 PageRank)。

四、有序数据(Ordered Data)
有序数据是一类对顺序敏感的数据类型。在这种数据中,元素出现的先后、时间上的推进或位置上的排列,会直接影响其意义和分析方式。这类数据在现实世界中极其常见,从购物序列到基因序列,再到时空数据,都属于有序数据的范畴。
4.1 有序数据的定义与特点

有序数据是按照特定顺序排列的数据序列,其中每个元素出现的位置都会改变整体的意义。例如,在时间序列中,事件发生的时间顺序至关重要;在路径数据中,地点访问的顺序同样不可忽略。也正因为顺序的重要性,这类数据常被用来分析模式的变化和趋势的演变。

有序数据通常具有以下几个特点:
序列性(Sequential Nature):数据由一系列事件、条目或记录组成,这些内容按照固定顺序排列。
时间维度(Temporal Dimension):许多有序数据包含时间信息,反映事件发生的时间顺序。
动态性(Dynamic Updates):随着时间推进,序列可能不断更新,加入新的事件或记录。
这些特点使得有序数据适用于分析行为模式、趋势预测以及动态环境下的决策问题。
4.2 有序数据的典型示例

一个典型例子是客户购物序列。假设某个顾客的多次购物记录如下:
交易 1:购买了 A 与 B
交易 2:购买了 C
交易 3:购买了 A 与 D
通过分析这些顺序,可以发现顾客的潜在购物习惯,例如:购买 A 的顾客往往可能会继续购买 B 或 D。

另一种形式是更结构化的序列化交易表格。例如,一组包含“时间 - 顾客 - 商品”的记录,可以转化成每个顾客的购买序列。这种结构便于后续进行模式挖掘,如寻找序列模式(Sequential Patterns)或频繁子序列(Frequent Subsequence)。

在生物信息学中,有序数据也十分重要。基因序列(DNA,RNA)本质上就是一段严格按照顺序排列的字符串序列。任何位置上的变化都可能导致基因功能的巨大差异,因此顺序是该数据的核心特征。
4.3 时空有序数据(Spatio-temporal Ordered Data)

除了时间序列外,还有一类包含时间与空间双重属性的有序数据,即时空数据(Spatio-temporal Data)。这种数据不仅记录时间,还记录空间位置,因此格外适用于研究趋势变化与地理分布的结合。
例如地球表面不同位置的降温与升温趋势,就是一个典型的时空数据分析场景。
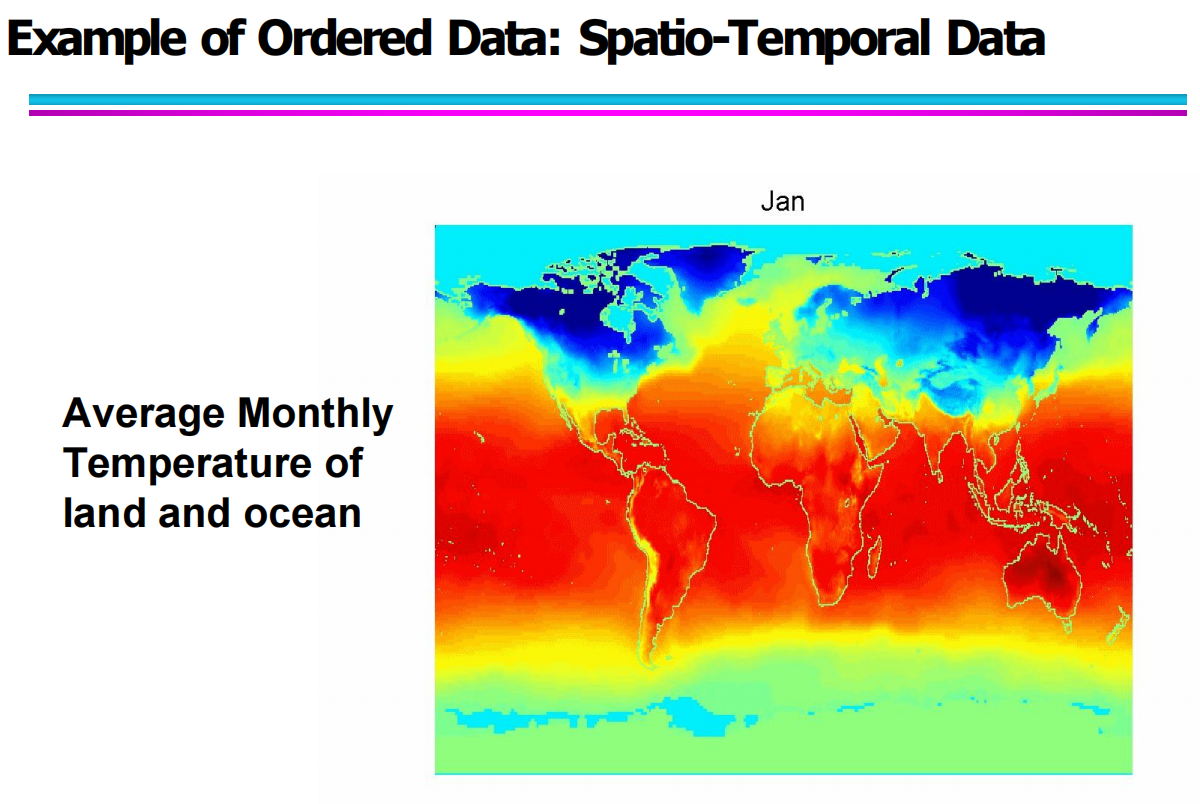
例如「全球陆地与海洋的月平均温度」地图,就是基于时空数据绘制而成。不同颜色代表不同温度范围,通过查看不同月份的变化,可以观察到季节、气候模式等关键趋势。这类数据在环境科学、气候研究与地理信息系统中被广泛使用。
4.4 小结
有序数据的核心价值在于“顺序的意义”。无论是购物行为、基因序列还是动态的气候变化,都依赖事件之间的先后关系进行理解与分析。随着数据规模的不断扩大,针对有序数据的分析方法(如序列模式挖掘、时间序列预测、轨迹分析)也变得越来越重要。