

这篇论文的摘要其实是在讨论一个非常人性化的技术挑战:AI 该如何面对那些“公说公有理,婆说婆有理”的模糊图像。作者指出,在很多现实任务中(尤其是像 CT 影像这样的医疗场景),图像本身是存在歧义的。一张片子放在那里,即便是几位资深的专业医生来划定病灶范围,他们给出的答案往往也不完全一样。如果传统的 AI 模型只学习给出一个唯一的、固定的答案,那它就会漏掉其他同样合理甚至更关键的可能性,这在医疗决策中是非常危险的。
为了解决这个问题,作者提出了一种叫 Probabilistic U-Net(概率U-Net) 的新模型。你可以把它理解为给一个擅长识别结构的 U-Net 装上了一个“生成式的头脑”。它通过结合变分自编码器(CVAE),把图像中各种不确定的可能性编码进一个名为“潜在空间”的维度里。这样一来,同一个输入图像,模型可以像玩抽奖一样,从这个空间里抽取出不同的随机向量,进而生成无数种既合理又各不相同的分割预测。
最后的实验结果非常亮眼,在肺部异常区域和城市街景的分割测试中,这个模型表现得非常“聪明”。它不仅能学会图片里有哪些不同的理解方式,甚至还能模仿出这些不同标注出现的频率。比如,如果十个医生里有八个认为这里是病灶,两个认为不是,模型生成的预测分布也能精准地还原这种“少数服从多数”的比例。相比于之前那些只能给出模糊概率或者生硬预测的方法,这个模型在处理复杂、有争议的图像时显然更胜一筹。
1. 介绍(Introduction)
在很多现实应用中,图像的含义并不是唯一的。尤其是在医疗影像领域,这种“内在歧义性”随处可见。想象一下,当一位放射科医生观察肺部 CT 图像时,由于光影、组织重叠或病灶本身的复杂性,仅凭图像往往无法断定某块阴影的精确边界。引言中强调,在这种情况下,通常的做法是邀请多位专家进行标注,而这些专家给出的结果往往是多样且合理的。这意味着,真值(Ground Truth)不再是一个唯一的点,而是一个分布。如果我们的 AI 模型只能输出一个“平均值”或者单一的预测,那么它就忽略了这种本质上的不确定性,而在医疗诊断中,这种忽略往往意味着巨大的安全风险。
为了更直观地理解这一点,我们可以看文中提供的这张关键对比图(Figure 1)。图中展示了四位不同专家(Grader 1-4)对同一个肺部病灶的标注结果,可以明显看到,虽然大体位置一致,但每个人划定的边缘形状、厚度都有显著差异。最右侧展示了传统模型的处理方式,它往往只能给出一个模糊的概率图,或者一个强行折中的结果。作者在引言中犀利地指出,这种传统方法最大的弊端在于它割裂了像素之间的空间相关性。简单来说,传统模型可能认为某个像素有 50% 的概率是肿瘤,但它无法保证生成的整张分割图在逻辑上是自洽的。它给出的可能是一个“长得像肿瘤但结构破碎”的结果,而不是像人类专家那样,给出一个虽然不同但“看起来很合理”的完整方案。
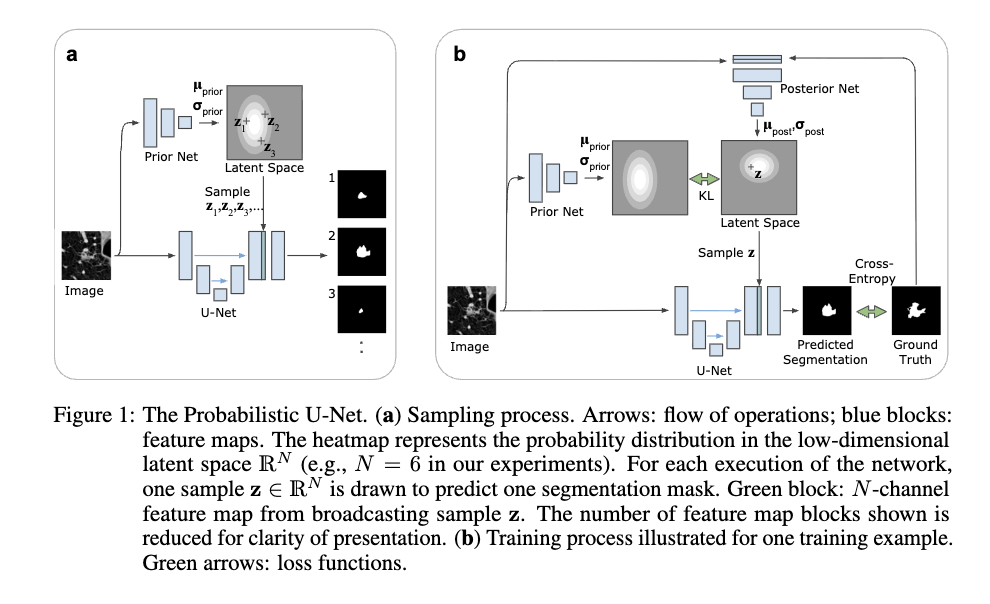
基于这种观察,引言提出了本研究的核心愿景:我们需要一种能够学习“分割结果分布”的模型。这种模型不应该只是预测每个像素属于某种类别的概率,而是应该能够像人类专家一样,针对同一张图像“生成”多个不同的、完整的、结构清晰的分割假设。作者认为,一个优秀的概率分割模型不仅要能覆盖所有合理的可能性,还应该能准确反映这些可能性在现实中出现的频率。比如,如果十位医生里有八位认为某处是病灶,那么模型生成的样本中也应该有约 80% 的比例体现这一点。这种从“寻找唯一答案”到“建模可能性分布”的思维转变,正是 Probabilistic U-Net 诞生的初衷,也为后续结合 U-Net 的结构特征与 CVAE 的生成能力奠定了理论基础。
2. 网络架构与训练流程(Network Architecture and Training Procedure)
理解 Probabilistic U-Net 的关键在于明白它并不是推翻了经典的 U-Net,而是在其基础上嫁接了一个“概率大脑”。整个架构由三个核心部分组成:U-Net 部分、先验网络(Prior Net)和后验网络(Posterior Net)。
1. 基础架构:负责“看”的 U-Net
模型的基础依然是我们熟悉的 U-Net。它像往常一样,通过层层卷积提取图像的特征,捕捉物体的形状和位置。但在概率 U-Net 中,U-Net 的最后一步不再是直接输出分割图,而是等待一个关键的“随机变量”加入,共同决定最终的预测。
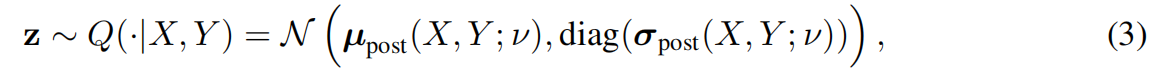
2. 潜在空间:容纳“不确定性”的容器
这是模型最神奇的地方。作者引入了 CVAE(条件变分自编码器) 的思路。模型学习了一个低维的“潜在空间”(通常只有 6 维)。你可以把它想象成一个充满可能性的空间:空间里的每一个点,都代表着一种对图像的特定理解方式。
先验网络(Prior Net):在预测时,模型只看原始图像,通过先验网络预测出这个潜在空间的分布。
后验网络(Posterior Net):(仅在训练时起作用) 它非常特殊,它不仅看原始图像,还要看专家标注的“真值(Ground Truth)”。它的任务是把专家的标注信息编码进潜在空间。
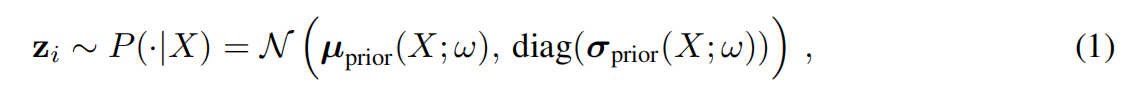
3. 融合与采样:生成无限可能
到了生成阶段,模型会从潜在空间中“采样”一个随机向量 z。这个 z 就像是一把钥匙,它被广播(Broadcast)并拼接到 U-Net 提取的特征图中。
最后,通过一个 1 x 1 的卷积层,模型将 U-Net 的结构信息和随机变量的采样信息融合,输出一张完整的、逻辑自洽的分割图。因为采样是随机的,你每运行一次,模型就可能给你展示一个略有不同的合理假设。
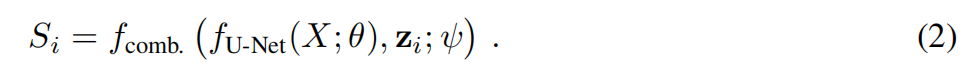
4. 训练秘籍:ELBO 损失函数
如何训练这样一个既要“准”又要“多样化”的模型呢?作者使用了变分推理中经典的 ELBO(Evidence Lower Bound) 损失函数。
重建损失(Reconstruction Loss):确保模型生成的分割图离专家标注越近越好。
KL 散度(KL Divergence):这是一个惩罚项,它约束先验网络预测的分布不要偏离后验网络太远。简单来说,就是训练模型在只看到原始图像时,也能猜到专家可能会怎么画。
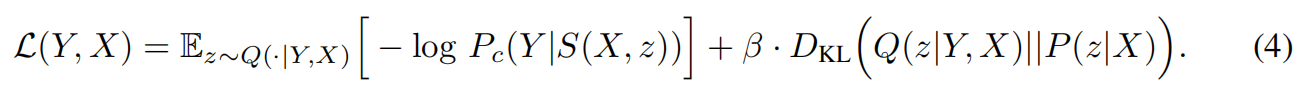
3. 绩效指标与基准方法(Performance Measures and Baseline Methods)
当我们拥有一个能生成无数种可能性的模型时,传统的评分标准(如简单的 IoU 或准确率)就显得捉襟见肘了。因为传统的指标只能对比“一对一”的关系(一个预测 vs. 一个答案),而我们需要对比的是“一组分布”。
1. 如何评价“分歧”的准确性?—— 广义能量距离 (DGED)
为了衡量模型生成的多种假设是否涵盖了所有专家可能给出的答案,作者引入了 DGED。这个指标的精妙之处在于,它不仅要求模型预测得准,还要求预测出来的“多样性”也要和专家的“多样性”保持一致。
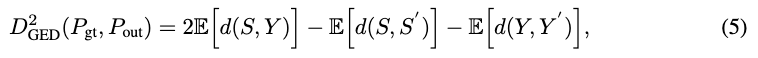
请看上面这张公式图。虽然它看起来由好几项组成,但其核心逻辑可以拆解为两部分:
第一部分(减号左边):衡量的是“模型预测的方案”与“专家给出的真实方案”之间的平均距离。这个数值越小,说明模型的预测越精准。
第二部分(减号右边):衡量的是“模型自己生成的不同方案之间”的距离,以及“不同专家标注之间”的距离。
直观理解:如果模型生成的方案全都一模一样(没有多样性),或者生成的方案虽然多但全都是专家从未想过的“瞎猜”,那么 DGED 就会很大。只有当模型生成的分布,完美重合了专家标注的分布时,DGED 才会达到最小。
2. 基准方法对比:谁才是处理歧义的高手?
为了证明概率 U-Net 的优越性,作者将其与几种主流的基准方法进行了“全方位的 PK”。
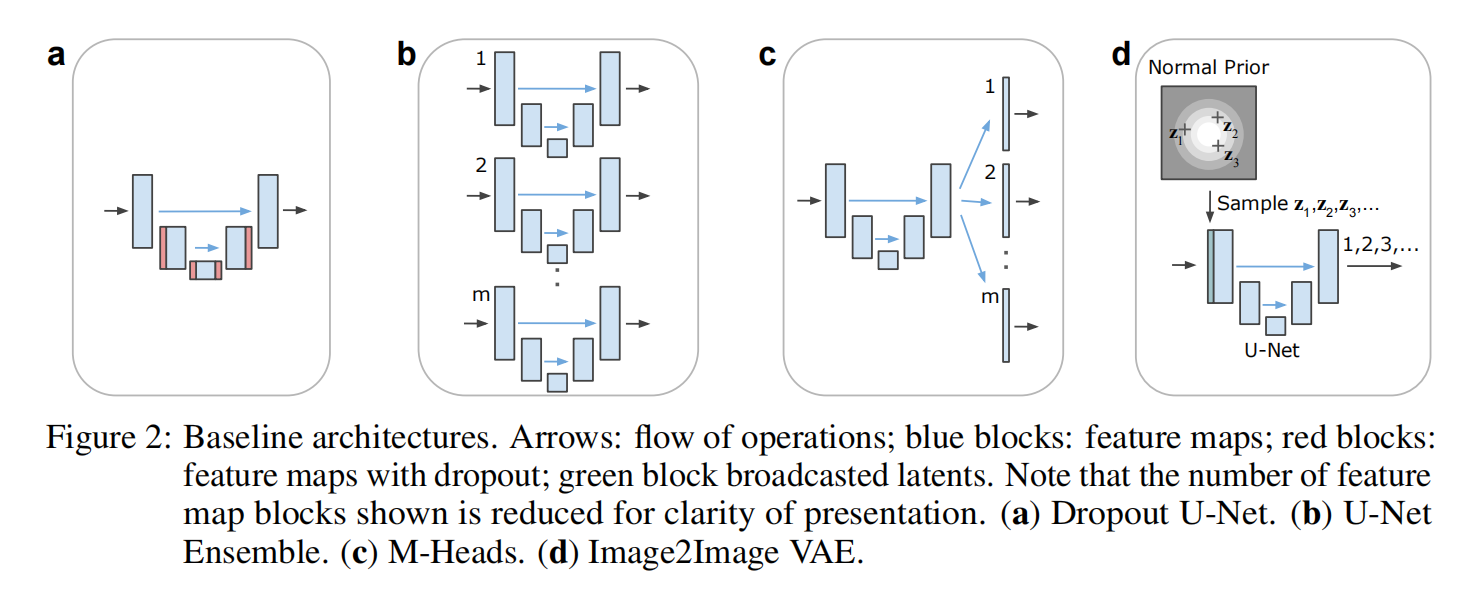
这张对比图表清晰地展示了不同方案的优劣:
Dropout U-Net:通过在预测时随机关闭一些神经元来获得多样性。但你会发现,它的效果并不理想,因为它产生的多样性往往是杂乱的像素噪点,而不是逻辑一致的结构。
M-Heads U-Net:让模型长出好几个“头”,每个头给一个答案。虽然这能产生几个方案,但数量极其有限(比如只能给 3-5 个),无法模拟复杂的连续分布。
Probabilistic U-Net(本文方法):从图表中可以看出,在肺部数据和城市景观数据上,本文方法的 DGED 分数都是最低的(即表现最好)。它生成的分割图不仅形态完整,而且其“纠结”的程度与人类专家的分歧高度吻合。
4. 结果(Result)
通过前几章的分析,我们知道概率 U-Net 在理论上非常出色。那么在实际应用中,它生成的那些“可能性方案”到底质量如何?作者在 LIDC-IDRI 肺部数据集和 Cityscapes 城市街景数据集上进行了深度验证。
1. 视觉对比:概率 U-Net vs. Dropout
首先,我们要观察模型生成的样本在“视觉逻辑”上是否过关。
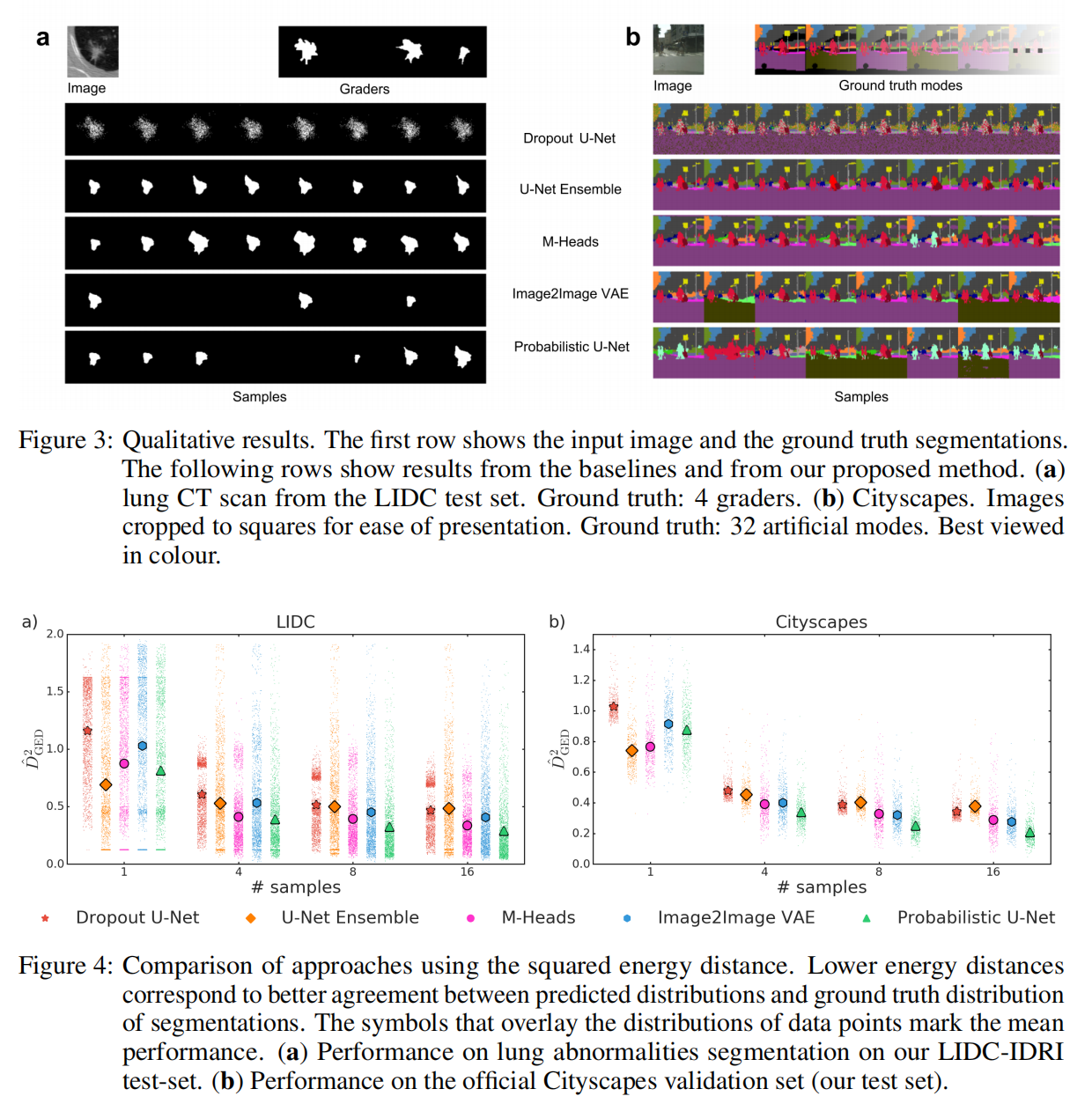
左侧是原始图像和专家标注,中间和右侧分别是 Dropout 模型和概率 U-Net 生成的多个样本。
Dropout 的问题:虽然 Dropout 也能生成不同的结果,但它的变化往往集中在边缘的“像素噪点”上。它的每一张图看起来都差不多,只是边缘有些发虚。
概率 U-Net 的优势:观察本文模型生成的样本,你会发现它捕捉到了全局的变化。有的样本预测范围大,有的样本预测范围小,但每一个样本的边缘都是清晰、连贯且符合解剖学逻辑的。这说明它确实从潜在空间里提取到了不同的“理解角度”,而不是简单的随机干扰。
2. 概率分布的还原
一个顶级的概率分割模型,不仅要能生成多种可能,还要能预测出这些可能出现的“频率”。
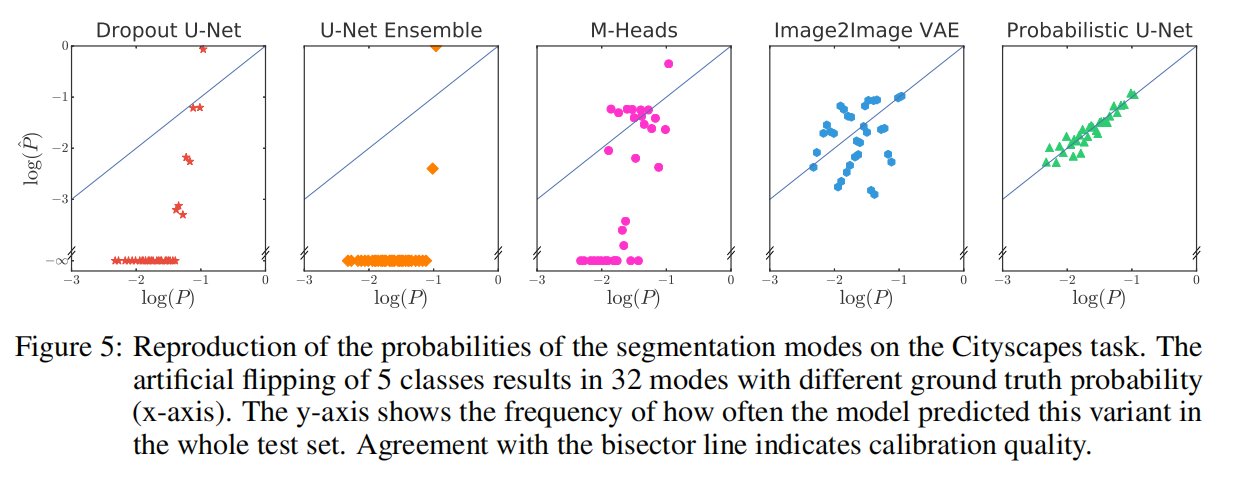
这张图片展示了模型在预测“歧义程度”上的精准性。
横轴与纵轴:通常代表专家标注出现的频率与模型采样生成的频率。
核心发现:在这张图中,概率 U-Net 的数据点非常接近对角线。这意味着,如果某块区域有 30% 的医生认为它是病灶,那么概率 U-Net 在生成 100 张图时,大约也有 30 张会把这里标为病灶。
深度解析:这种对“频率”的还原能力至关重要。在自动驾驶或医疗辅助中,这能告诉决策者:这个判断不仅存在分歧,而且分歧的严重程度是多少。相比之下,传统的基准方法(如 M-Heads)往往会“偏科”,只能捕捉到最明显的几种模式,而忽略了那些低概率但高风险的稀有情况。
5. 讨论与结论(Discussion and conclusions)
作者在讨论中首先强调了 Probabilistic U-Net 的核心价值,即它彻底改变了 AI 在面对“不确定性”时的态度。在过去,分割模型往往被迫在多个专家的意见中选择一个“平均值”作为输出,但这在医疗场景下是极其危险的,因为模糊的平均值往往意味着丢失了潜在的病灶细节。而本研究证明了,通过引入潜在空间(Latent Space)并结合 U-Net 的结构化特征,AI 可以学会如何像一个专家团队一样思考。它不再仅仅给出一个死板的答案,而是能够吐出一系列逻辑自洽、边界清晰的诊断方案。这种能力的提升并非单纯靠增加算力,而是源于模型能够捕捉到图像特征与潜在解释之间的深层概率关联。
接着,结论部分点出了该模型在实际应用中的三大技术跨越。首先是它生成的样本具备极高的“空间相关性”,这意味着生成的每一个切片在解剖学上都是合理的,不会出现像传统 Dropout 方法那样破碎的噪点。其次是其惊人的计算效率,因为 U-Net 的大部分特征提取只需要运行一次,后续生成无数种方案只需要在极低维度的潜在空间里进行采样和简单的卷积融合,这使得实时临床辅助成为可能。最后,也是最令人印象深刻的一点,是模型对“分歧频率”的精准还原。如果 80% 的医生认为某个阴影是肿瘤,模型生成的样本分布也会忠实地反映出这种高概率,从而为医生的最终决策提供量化参考。
总的来说,这篇论文开启了“生成式分割”的新纪元。它提醒我们,一个真正智能的医疗助手不应该代替人类做决定,而应该诚实地展现出所有的可能性和风险。概率 U-Net 的成功证明了,学会“纠结”和承认“不确定性”是 AI 迈向严谨医学应用的关键一步。对于读者而言,这篇文献的意义在于它展示了如何通过精妙的数学架构(如 CVAE 与 U-Net 的缝合)来解决现实世界中最棘手的歧义问题。在未来的医疗影像 AI 发展中,这种能够与人类专家产生“共鸣”的算法,无疑将比那些只会给单一结论的算法更具生命力。