第一节:句式结构的两种视野
在自然语言处理中,理解一个句子不仅仅是识别每个词的意思,更重要的是理解这些词是如何组合在一起表达完整语义的。目前主流的句法分析主要有两种视角:成分句法分析和依存句法分析。
1. 成分句法分析 (Constituency Parsing)
成分句法分析又被称为短语结构语法(Phrase Structure Grammar),它深受乔姆斯基(Noam Chomsky)上下文无关语法(CFGs)的影响。其核心思想是将词组织成嵌套的组成部分(Nested Constituents)。
基本单位:从单个词(如 the, cat, door)开始。
组合过程:词与词组合成短语(Phrases),例如 "the cuddly cat" 形成名词短语(NP),"by the door" 形成介词短语(PP)。
层级结构:短语可以进一步组合成更大的短语,直到构成完整的句子。

为了规范这种组合,我们会定义一系列语法规则,例如:
NP -> Det + N(名词短语由限定词和名词组成)
PP -> P + NP(介词短语由介词和名词短语组成)

2. 依存句法分析 (Dependency Structure)
与成分句法关注“如何打包”不同,依存句法直接关注词与词之间的二元关系。它展示了哪些词依赖于(修饰、附属于或作为论元)哪些词。
核心词 (Head):被修饰或被支配的中心词(也叫 Governor, Superior)。
依附词 (Dependent):修饰或补充核心词的词(也叫 Modifier, Subordinate)。
二元不对称关系:这种关系通常用“箭头”表示,从 Head 指向 Dependent。

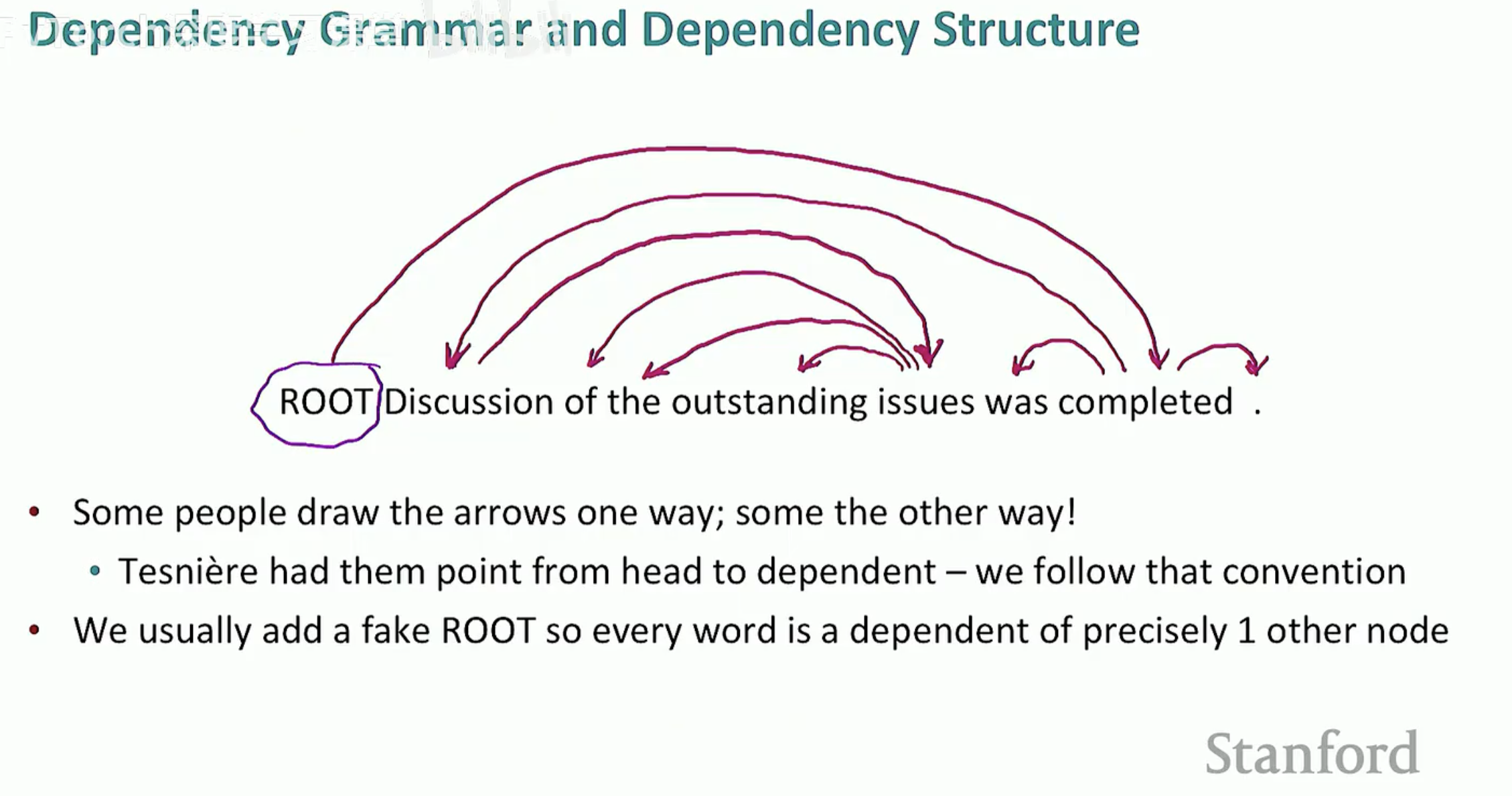
3. 依存句法的形式化定义与约束
在实际算法处理中,依存句法通常被形式化为一个有向图。为了保证句子能被唯一且正确地解析,它通常满足以下三个性质:
连通性 (Connected):所有词都通过某种关系连接在一起。
无环性 (Acyclic):不存在循环依赖关系。
单父节点 (Single-root):除了根节点,每个词都精确地依赖于另一个节点。
为了实现这一点,我们通常会引入一个虚构的 ROOT 节点,让句子的核心动词指向它,从而确保所有词都属于同一棵树。
4. 为什么要标注关系类型?
现代依存分析不仅仅是画箭头,还会给箭头贴上“标签”(Typed Dependencies),用来描述具体的语法关系。例如:
nsubj:名词性主语(nominal subject)。
obj:直接宾语(object)。
nmod:名词修饰语(nominal modifier)。
通过这种方式,我们能一眼看出谁是句子的发起者,谁是动作的承受者。

第二节:句法歧义的化解与语义提取的实战
语言是充满艺术性的,但对于计算机来说,这种艺术性往往意味着“歧义”。依存句法分析的一大功劳,就是通过明确的词汇关联来消除这些歧义。
1. 介词短语附件歧义 (PP Attachment Ambiguity)
这是句法分析中最经典的难题。一个介词短语(PP)到底是在修饰动词,还是在修饰它前面的名词?
示例句子:"Scientists count whales from space."
解析 A:
from space依附于动词count。这意味着科学家们站在外太空进行观测(这是符合逻辑的)。解析 B:
from space依附于名词whales。这意味着这些鲸鱼是来自外太空的(这显然变成了科幻片)。

2. 协调范围歧义 (Coordination Scope Ambiguity)
当句中出现连词(如 and)时,它连接的边界在哪里?这直接影响了我们对身份或实体的理解。
案例分析:"Shuttle veteran and longtime NASA executive Fred Gregory..."
这里
and是连接了“穿梭机老兵”和“NASA高管”这两个身份并指向同一个人(Fred Gregory),还是指两个人?

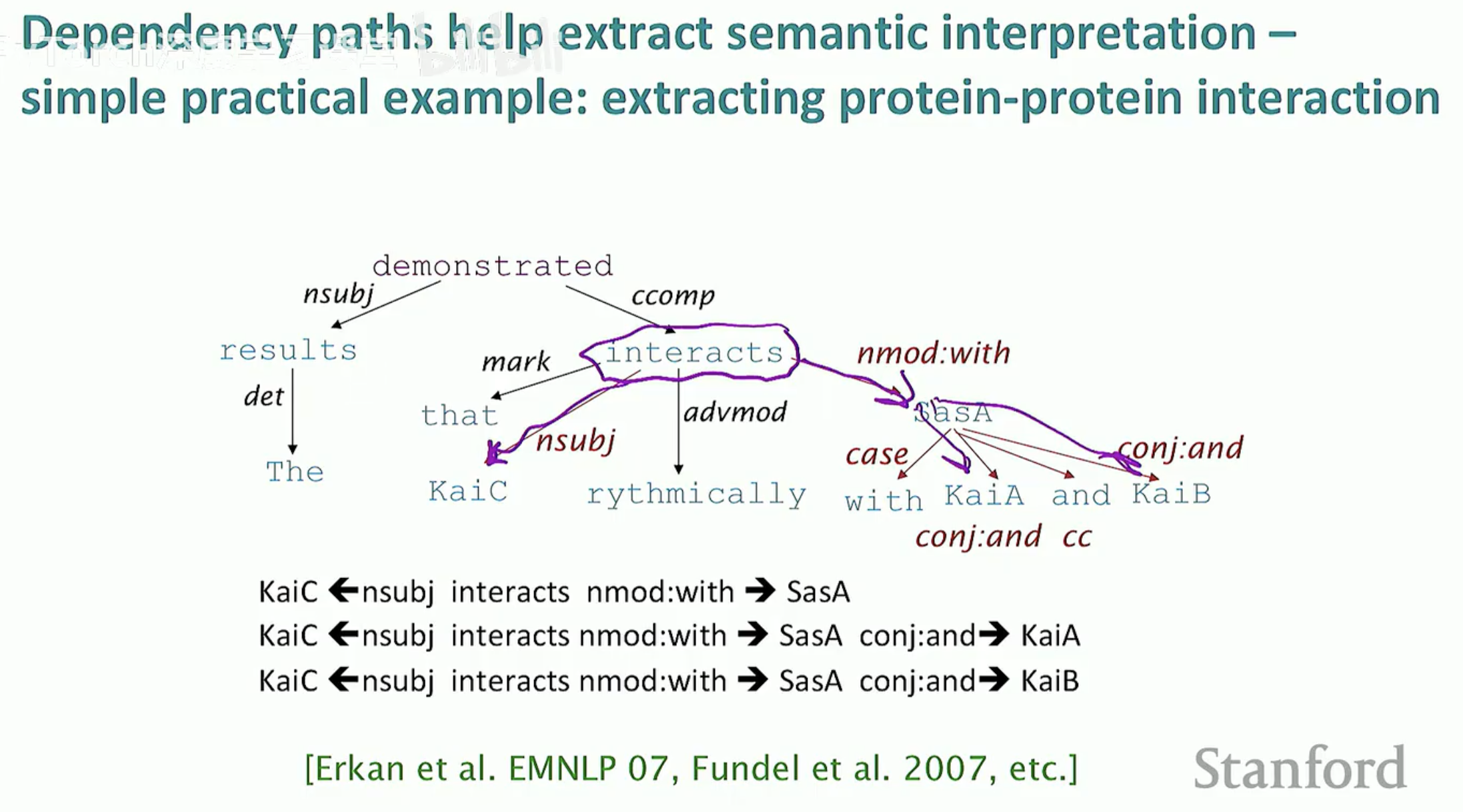
3. 从句法树到语义:依存路径提取
掌握了依存结构后,我们就可以利用依存路径(Dependency Paths)来完成高级任务,比如信息抽取。
在生物信息学或医学文本处理中,我们经常需要提取“谁作用于谁”。
实战案例:提取蛋白质相互作用(Protein-Protein Interaction)。
即使句子非常长且复杂(如:"The results demonstrated that KaiC interacts rythmically with SasA..."),只要我们顺着依存路径寻找:
找到核心动词
interacts。顺着
nsubj(名性主语)找到KaiC。顺着
nmod:with(介词修饰)找到SasA。
这样,无论句子加了多少修饰成分,我们都能精准提取出核心语义关系。
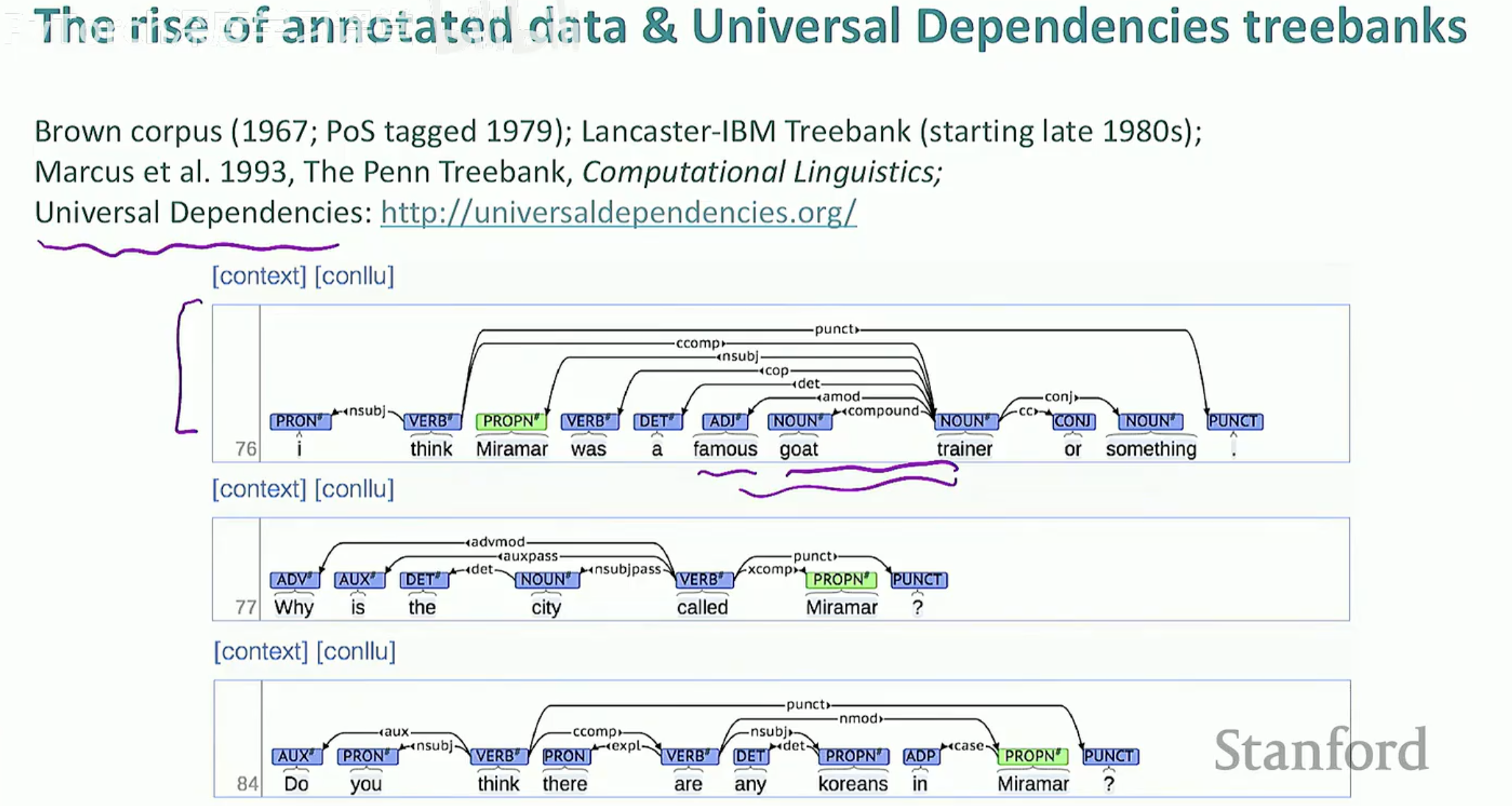
4. 迈向国际化:通用依存(Universal Dependencies)
为了让不同语言的句法分析有统一的标准,学术界推出了 Universal Dependencies (UD) 项目。它定义了一套通用的标注框架,使得我们处理英文、中文甚至稀有语言时,可以使用同一套逻辑。
标注演进:从早期的 Penn Treebank 到如今的 UD 树库。
特点:强调词汇间的依赖,支持跨语言的研究和模型迁移。
第三节:算法实现——从状态转移到神经网络
构建依存树的挑战在于,一个句子可能的组合方式随着字数增加呈指数级增长。基于转移的方法(由 Nivre 在 2003 年提出)通过一种类似“贪心搜索”的策略,将解析过程看作一系列确定性的动作组合。
1. 核心机制:栈与缓存的博弈
基于转移的解析器就像一个精密运行的自动化机器,它维护着三个核心数据结构:
Stack (栈):存储正在处理的词。
Buffer (缓冲区):存储待处理的句子剩余词汇。
Dependency Arcs (关系集):已经确定的依存关系。

2. Arc-Standard 系统的三大动作
解析器通过不断执行以下三个动作,直到缓冲区变空且栈中只剩下 ROOT:
SHIFT (进栈):将 Buffer 的第一个词移入 Stack。
LEFT-ARC (左弧):认定 S1 -> S2(栈顶第二个词依赖于栈顶词),建立关系并从栈中弹出 S2。
RIGHT-ARC (右弧):认定 $S2 -> S1(栈顶词依赖于栈顶第二个词),建立关系并从栈中弹出 S1。
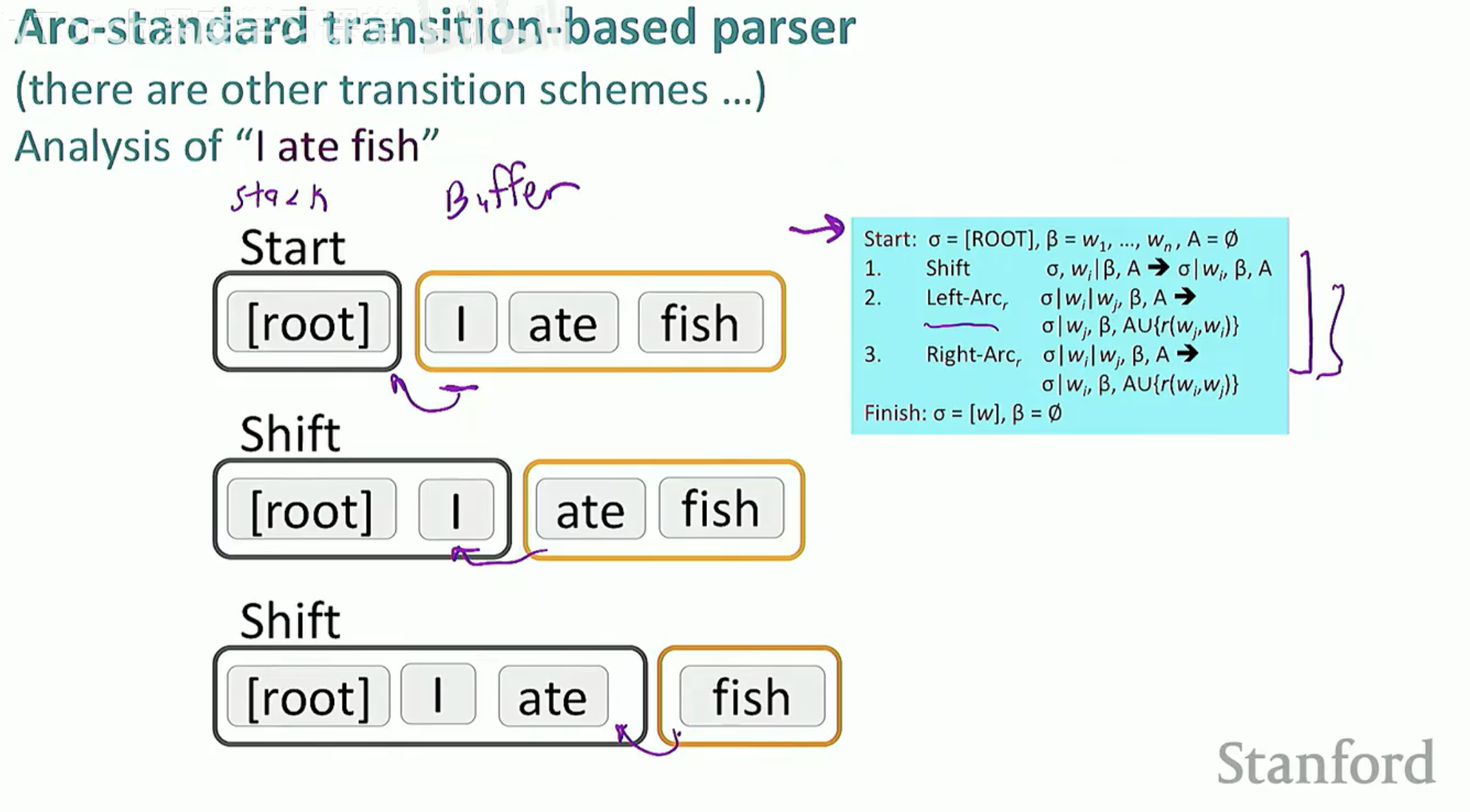
3. 投射性 (Projectivity) 的约束
在算法处理中,有一个重要的概念叫投射性。
投射性解析:意味着所有的依存弧在画出来时都不会发生交叉。
现实挑战:虽然大多数英语句子是投射性的,但在自由语序语言(如德语、荷兰语)或中文的某些倒装结构中,会出现非投射性(Non-projective)现象,这需要更复杂的算法来处理。

4. 进化:从特征工程到深度学习
传统的基于转移的解析器依赖人工设计的特征模板(如:栈顶词的词性 + 缓冲区第一个词的词根)。这种方式面临三个痛点:
稀疏性 (Sparse):特征组合太多,很多组合在训练集里从未出现。
不完整性:人工难以穷举所有有用的特征。
效率瓶颈:特征计算占据了解析时间的 90% 以上。
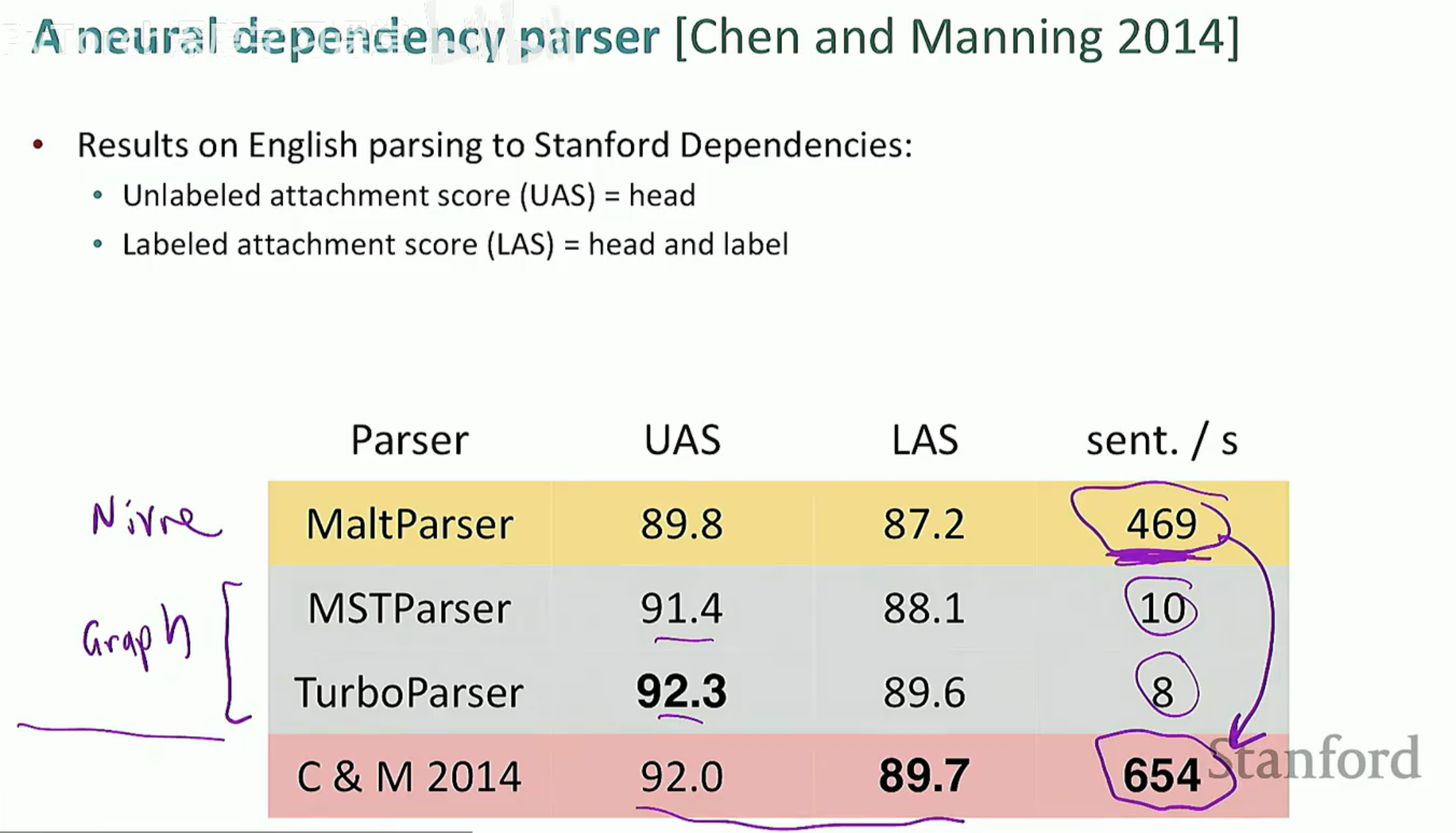
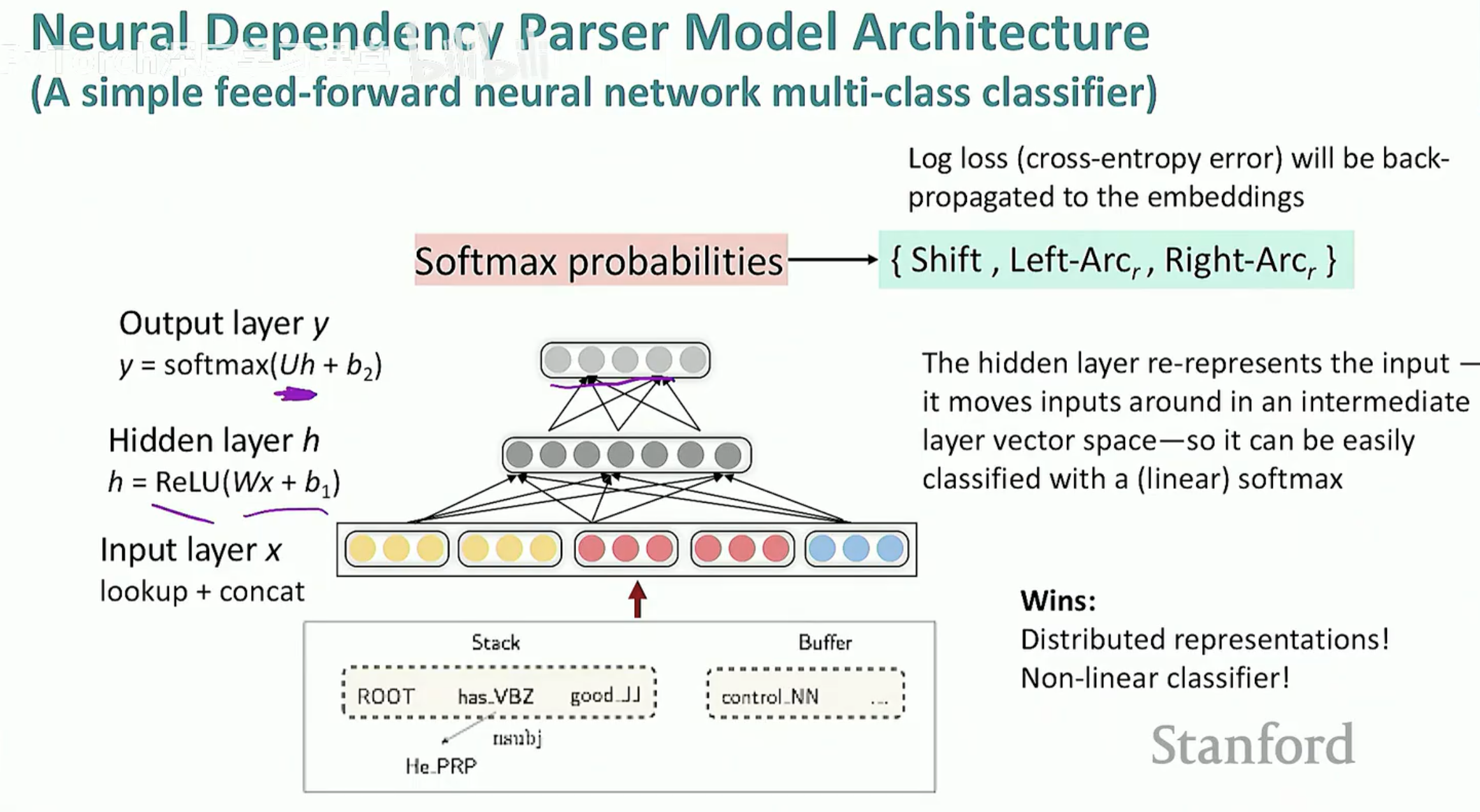
2014 年,Chen & Manning 推出了首个神经网络依存解析器。
它们不再使用 0/1 的特征向量,而是将词、词性、标签转换为低维稠密向量 (Embedding)。
通过一个简单的多层感知机(MLP),解析速度提升了数倍,准确率也大幅飞跃。

5. 评价指标:如何衡量解析器的优劣?
最后,我们用两个核心指标来给解析器打分:
UAS (Unlabeled Attachment Score):不考虑标签,只看词与词之间的箭头指对了吗?
LAS (Labeled Attachment Score):不仅要指对,箭头的标签(如 nsubj)也要完全匹配。