
第一节:前言
在处理图像识别(CNN)或简单的数值回归(MLP)时,我们的模型通常假设输入数据是相互独立的。然而,人类的语言、动人的旋律、或是波动的股票曲线,都具有一个共同特征:序列性(Sequentiality)。
如果你只看“马”这个字,你无法判断它是主语、宾语还是形容词;但如果你看到“那匹马在跑”,上下文立刻赋予了它生命。
核心挑战:变长与上下文
传统的神经网络在处理序列时面临两个痛点:
长度不一: 句子有的长达百字,有的仅有两个单词,模型需要灵活适配。
长程依赖: 序列中靠后的信息往往依赖于前面的伏笔。
RNN 的破局之道:隐藏状态(Hidden State)
RNN 的伟大之处在于它引入了“记忆”的概念。每当模型处理序列中的一个新元素(如一个单词)时,它不仅会看当前的输入,还会结合上一时刻留下来的“残余信息”——这就是隐藏状态 ht。
我们可以把 ht 想象成一个不断更新的笔记本,每读到一个新词,模型就在上面记两笔,并带着这个笔记本走向下一个词。正是这种递归的结构,让 RNN 能够“读懂”上下文。
第二节:等长序列标注 (Sequence Tagging)
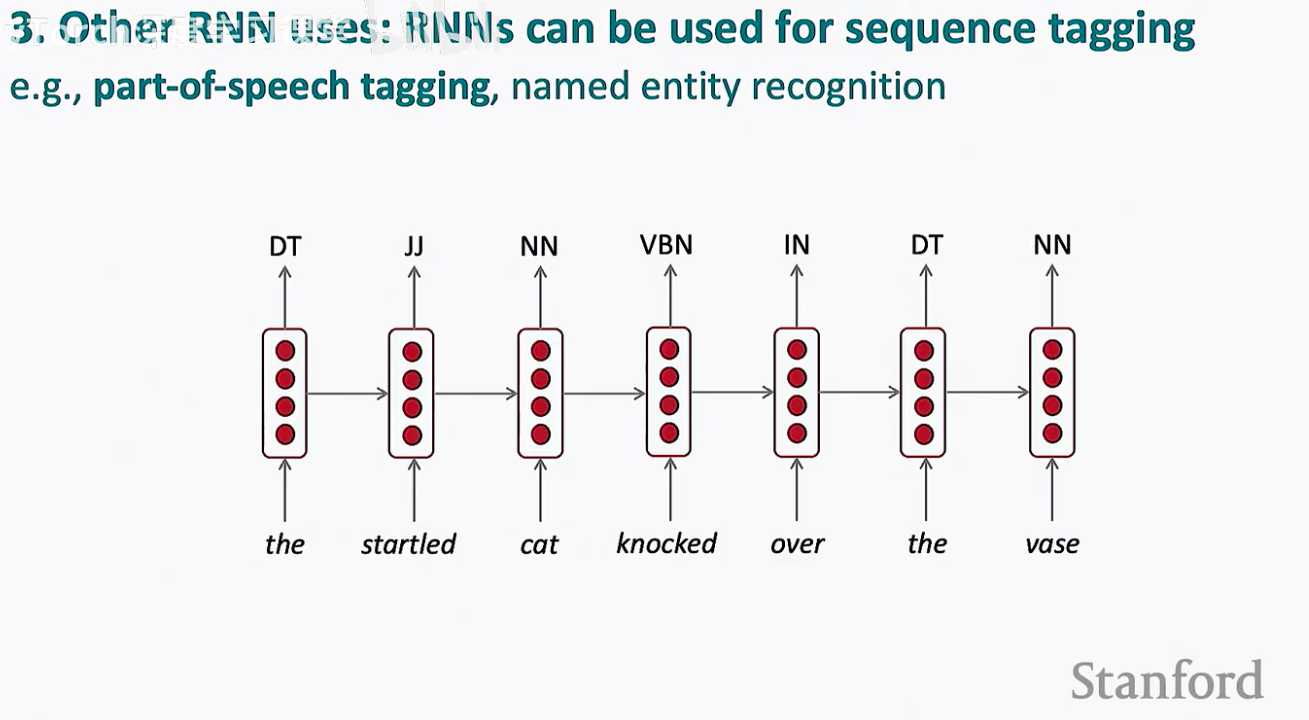
这是 RNN 最直接、最直观的一种应用模式。在这种架构下,每一个时间步的输入 xt 都会立刻对应一个输出 yt。这种“输入一个,输出一个”的 Many-to-Many 模式,非常适合需要对序列中的每个元素进行分类的任务。
核心逻辑
在这种模式下,模型在处理每个单词后,直接通过其当前的隐藏状态去预测该单词的标签。这意味着模型在做出决策时,已经参考了该单词之前的所有历史信息。
典型应用案例
词性标注 (Part-of-Speech Tagging): 识别句子中每个词是动词、名词还是形容词。
命名实体识别 (Named Entity Recognition, NER): 在一串文本中精准定位出人名、地名或组织机构名。
第三节:句子编码器 (Sentence Encoder)
如果说上一节的序列标注是“边走边看”,那么句子编码器(Sentence Encoder)模式则是“看完再说”。在很多任务中,我们并不关心每一个单词的特定标签,而是希望模型能读完整个句子,然后告诉我们:这个句子到底在说什么?
这种架构通常被称为 Many-to-One 模式。
核心逻辑:从序列到向量
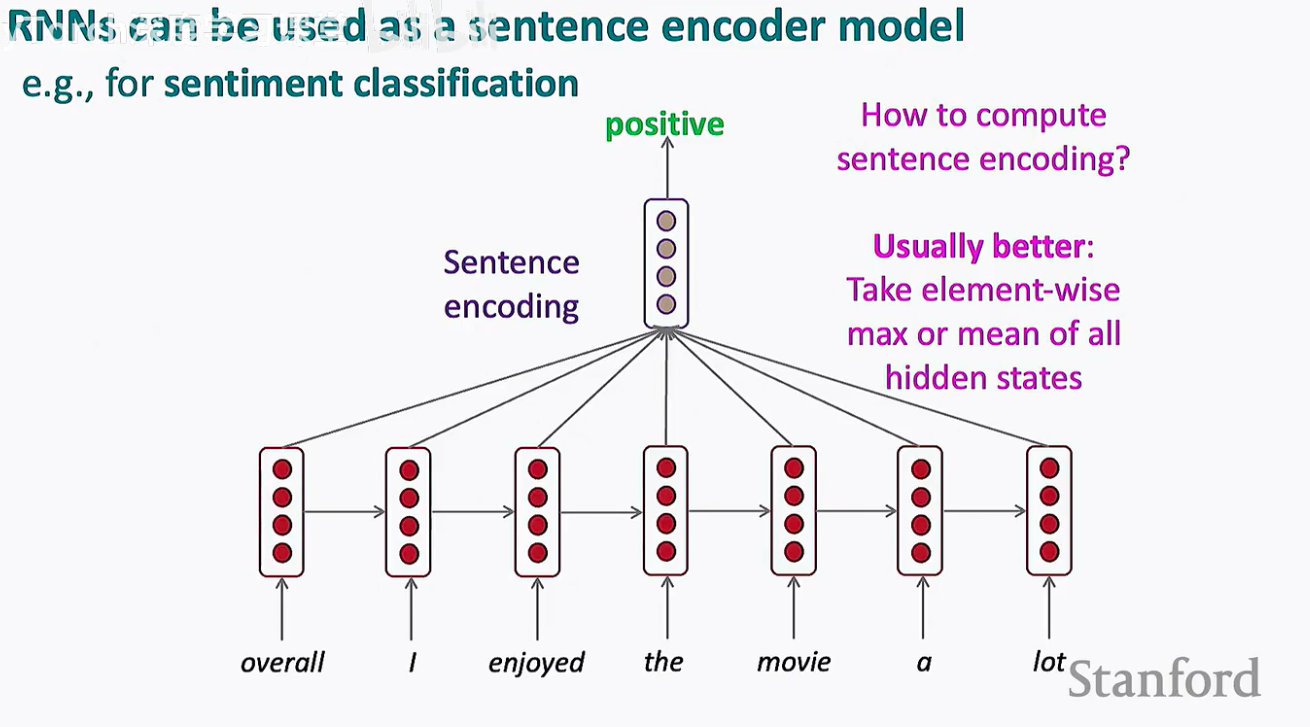
在这种模式下,RNN 逐词读取输入(如“overall I enjoyed the movie a lot”),随着隐藏状态 ht 的不断更新,模型在最后一个时间步所持有的向量,理论上已经“吸收”了全句的信息。
这个最终的向量就像是句子的数字指纹(Encoding),我们可以把它丢进一个分类器,让它判断这句影评是褒还是贬。
如何获得更高质量的“精华”?
虽然理论上最后一个隐藏状态包含了所有信息,但在实践中,随着句子变长,模型可能会产生“遗忘”。为了获得更鲁棒的语义表示,研究者们通常采用以下策略:
元素级最大值 (Element-wise Max): 提取所有时间步中响应最强烈的特征。
平均值 (Mean): 综合考量句中所有词汇的平均贡献。
典型应用案例
情感分析 (Sentiment Classification): 自动识别用户评价是积极还是消极。
文本分类: 将新闻稿自动归类为科技、体育或财经。
第四节:条件语言模型 (Conditional Language Model)
这是 RNN 最令人兴奋的用法之一。之前的模式大多是在“分析”文本,而条件语言模型(Conditional LM)则让模型具备了“创作”的能力。
核心逻辑:引导下的生成
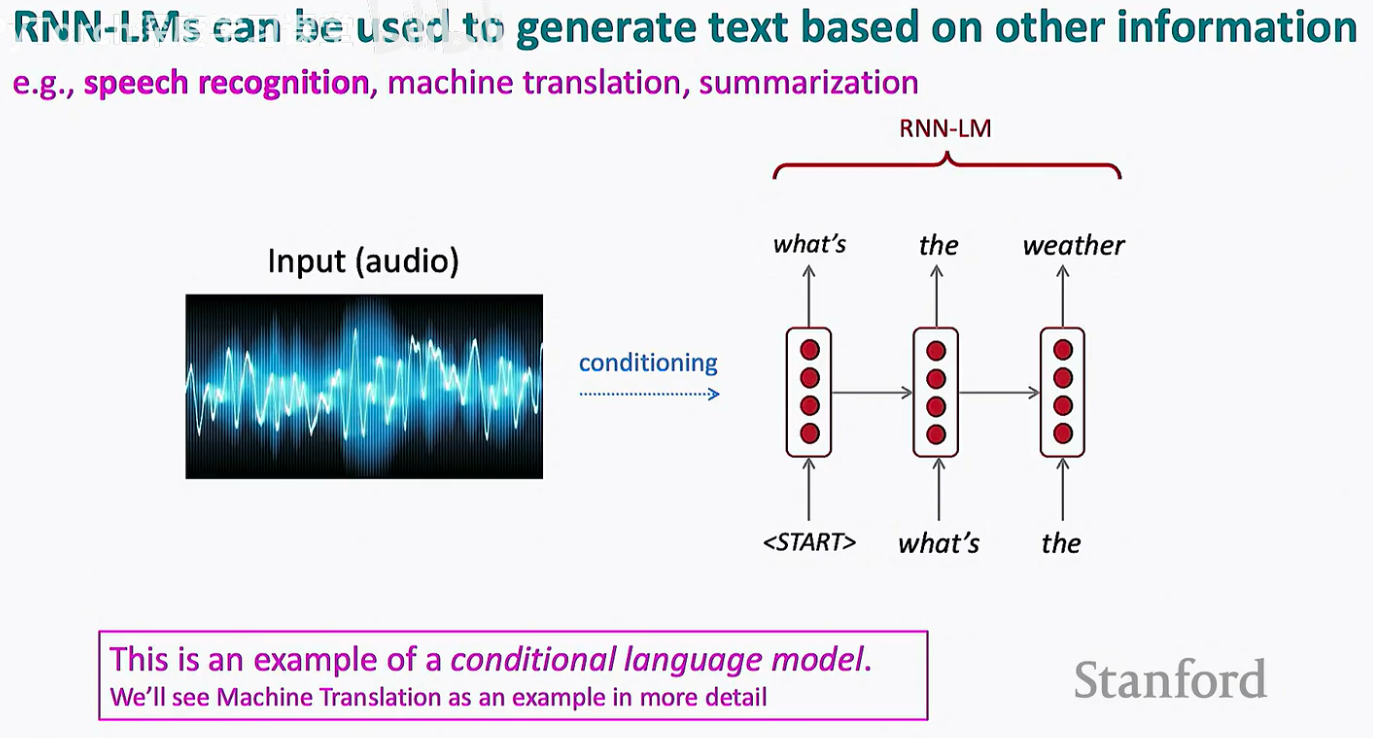
普通的语言模型只是根据前一个词预测下一个词。而“条件”二字意味着我们给模型增加了一个额外的输入(Conditioning),用来引导生成的方向。
这个条件可以是一段音频、一张图片,或者另一种语言的句子。模型会基于这个初始条件,配合已经生成的文本(作为历史信息),像滚雪球一样逐个吐出单词。
典型应用案例
语音识别 (Speech Recognition): 给定一段音频信号,条件化地生成对应的文字转录。
机器翻译 (Machine Translation): 给定源语言句子,生成目标语言的译文。
自动摘要 (Summarization): 给定长篇文章,生成精简的摘要。
第五节:如何根据任务选择合适的 RNN 架构?
通过以上三个模式的拆解,我们可以看到 RNN 的强大之处不仅在于它能“记忆”,更在于其输入与输出映射关系的灵活性。在实际开发中,选择哪种模式完全取决于你的任务目标:
快速决策对照表
结语
虽然现在 Transformer 等注意力机制模型在许多领域占据了主导地位,但理解 RNN 的这些基本模式依然至关重要。它们定义了处理序列数据的底层逻辑:如何对齐、如何压缩、以及如何受控地生成。
当你下次面对一个序列问题时,不妨先问自己:我是需要每个步长的输出,还是需要一个全局的摘要,亦或是需要模型在某种引导下开启“创作”?