
第一节:计算机如何理解“意义”? (How do we represent meaning?)
在深入研究复杂的算法之前,我们需要先思考一个哲学问题:什么是“意义”(Meaning)?
1. 语言学中的“意义”
根据《韦伯斯特词典》的定义,意义通常指一个词、短语所代表的“思想”(Idea)。在传统的语言学思维中,我们通过**符号(Signifier)与被指代物(Signified)**之间的映射来理解世界。
例如,当我们看到单词 “tree” 时,计算机看到的只是一个字符串,但人类大脑会自动将其关联到现实世界中那些长着树叶、树干的实体植物。这种将符号映射到概念的方式被称为指称语义(Denotational semantics)。

2. 早期 NLP 的解决方案:WordNet
既然“意义”在于关联,那么最直观的想法就是给计算机一本“说明书”,告诉它哪些词是相关的。
在深度学习流行之前,最常用的解决方案是使用 WordNet —— 这是一个包含同义词集(Synonym sets)和上位词(Hypernyms,即“is a”关系)的结构化词典。
同义词查询:例如,WordNet 会告诉计算机 "good" 的同义词包括 "goodness"、"commodity"、"beneficial" 等。
层次结构查询:例如,查询 "panda"(熊猫)时,WordNet 会展示其上位词路径:熊猫 -> 食肉动物 -> 哺乳动物 -> 脊椎动物 -> 动物 -> 生物。

通过这种方式,计算机似乎“理解”了词与词之间的联系。然而,正如我们将在下一节看到的,这种依赖人工维护的“意义表示”存在着致命的缺陷。
第二节:离散表示的困境 —— 为什么 WordNet 不够好?
虽然 WordNet 这种人工构建的词库在早期 NLP 中起到了重要作用,但随着互联网数据的爆炸式增长,它的弊端逐渐显现。
1. WordNet 的四大缺陷
依赖人工专家维护的词典在面对真实语言环境时非常脆弱:
缺乏细微差别(Missing nuance):例如 "proficient" 被列为 "good" 的同义词,但这仅在某些语境下成立。
无法跟上新词(Missing new meanings):语言是进化的,WordNet 很难实时收录像 "wicked"、"badass"、"ninja" 这种在现代语境下产生新含义的词汇。
主观性(Subjective):词与词的关系取决于编撰者的理解。
维护成本极高:需要大量人力进行持续的更新和适配。

2. 独热编码 (One-hot Encoding) 与正交困境
在计算机内部,单词最简单的数字化方式是 One-hot 编码:给每个单词一个唯一的索引,并用一个长向量表示,该索引位置为 1,其余全为 0。
然而,这种表示方法在搜索和理解中会遭遇巨大的挑战。
案例分析:如果用户搜索 "Seattle motel",我们希望系统能匹配到包含 "Seattle hotel" 的文档。
正交性问题:在 One-hot 表示中,motel 和 hotel 是两个完全不同的向量:
motel = [0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0]
hotel = [0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0]
无法计算相似度:这两个向量是正交(Orthogonal)的。从数学上讲,它们的点积(Dot Product)为 0,这意味着在计算机看来,"motel" 和 "hotel" 之间没有任何相关性。

3. 小结:我们需要一种更好的方案
由于 WordNet 无法涵盖所有关联,且 One-hot 无法计算相似度,NLP 领域迫切需要一种能将相似度信息直接编码进向量本身的新方法。
第三节:分布式语义 (Distributional Semantics)
既然靠人工编撰词典(WordNet)和简单的数字编码(One-hot)都无法让计算机真正理解词义,科学家们开始转向语言学中的一个经典思想——分布式语义。
1. 核心思想:靠“朋友”识人
分布式语义的核心可以总结为一句话:一个词的含义是由它周围经常出现的词决定的。
正如语言学家 J. R. Firth 在 1957 年提出的名言:
"You shall know a word by the company it keeps."
(观察一个词的伴随词,就能知道它的意义。)
这是现代统计 NLP 中最成功的理念之一。
2. 上下文 (Context) 与窗口 (Window)
当我们说一个词 w 出现在一段文本中时,它的上下文(Context)是指出现在它附近(在一个固定大小的窗口内)的一组词。
我们可以通过观察一个词在大量文本中出现的成千上万个上下文,来构建出这个词的表示。
例子:观察 "banking" 这个词。
"...government debt problems turning into banking crises as happened in 2009..."1
"...saying that Europe needs unified banking regulation to replace the hodgepodge..."2
"...India has just given its banking system a shot in the 3arm..."
通过这些上下文词(如 crises, regulation, system),计算机就能逐渐拼凑出 "banking" 的语义画像。
 编辑
编辑
3. 从离散到稠密:词向量 (Word Vectors)
基于分布式语义,我们不再使用带有大量 0 的稀疏 One-hot 向量,而是为每个单词构建一个稠密向量(Dense Vector)。
词向量的特点:
它是高维的(通常是 50 到 300 维)。
它是连续的(每一维都是实数,而不是 0 或 1)。
相似度计算:我们可以通过计算两个向量的点积(Dot Product)或余弦相似度,来衡量它们的语义相关性。例如,"banking" 和 "monetary" 的向量在空间中会非常接近。

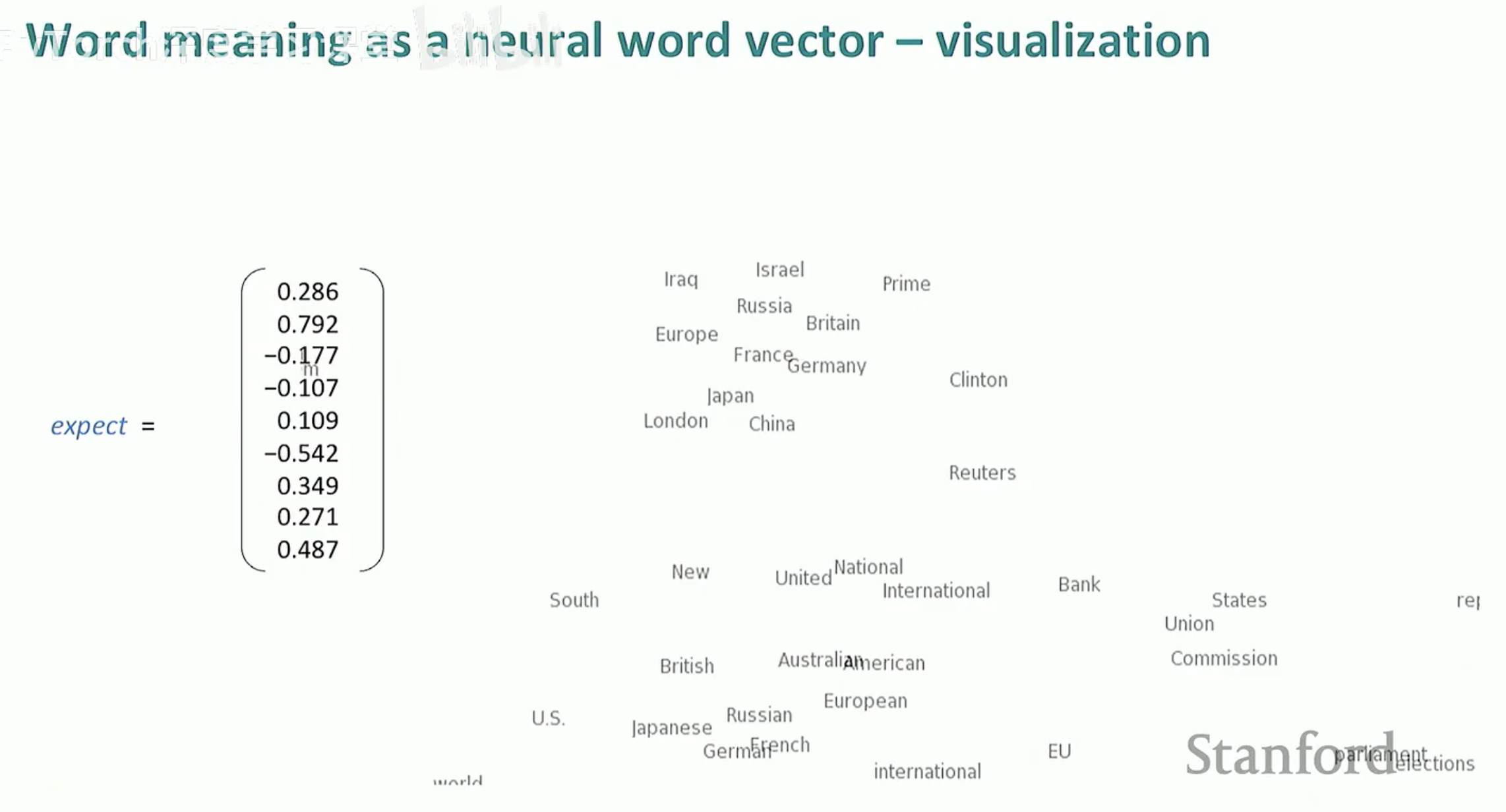
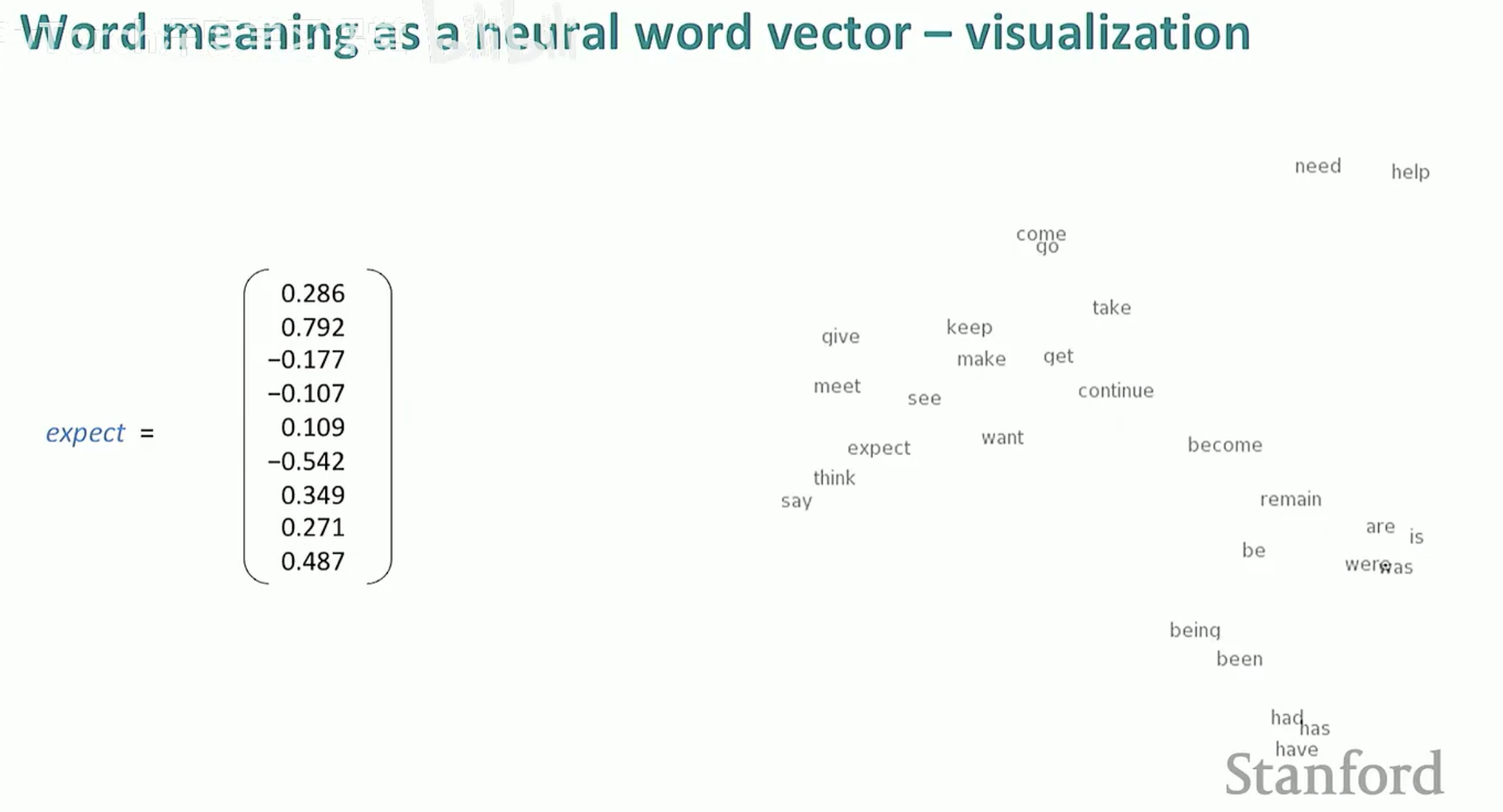
4. 词向量的可视化
当我们把这些高维向量投影到二维空间时,你会发现奇妙的现象:意思相近的词会自动聚集在一起。例如,所有的动词(say, think, expect)会形成一个簇,而所有的国家名或数字会形成另一个簇。
第四节:Word2Vec 架构解析
Word2Vec (Mikolov et al. 2013) 并不是一个单一的模型,而是一个用于学习词向量的框架。它的核心思想非常纯粹:既然“语义”由“上下文”定义,那我们就训练一个模型,让它专门去做“预测”这件事。
1. Word2Vec 的基本思路
模型在大规模语料库(Body of text)上运行,词汇表中的每个单词最初都分配一个随机的向量。
中心词与上下文:我们在文本的每一个位置 t 进行滑动。在该位置,有一个中心词 (Center word c) 和它周围的上下文词 (Outside words o)。
相似度即概率:我们利用 c 和 o 的词向量相似度来计算在给定中心词的情况下,预测出这些上下文词的概率。
不断优化:通过不断调整词向量,使得这个预测概率最大化。

2. Skip-gram 模型详解
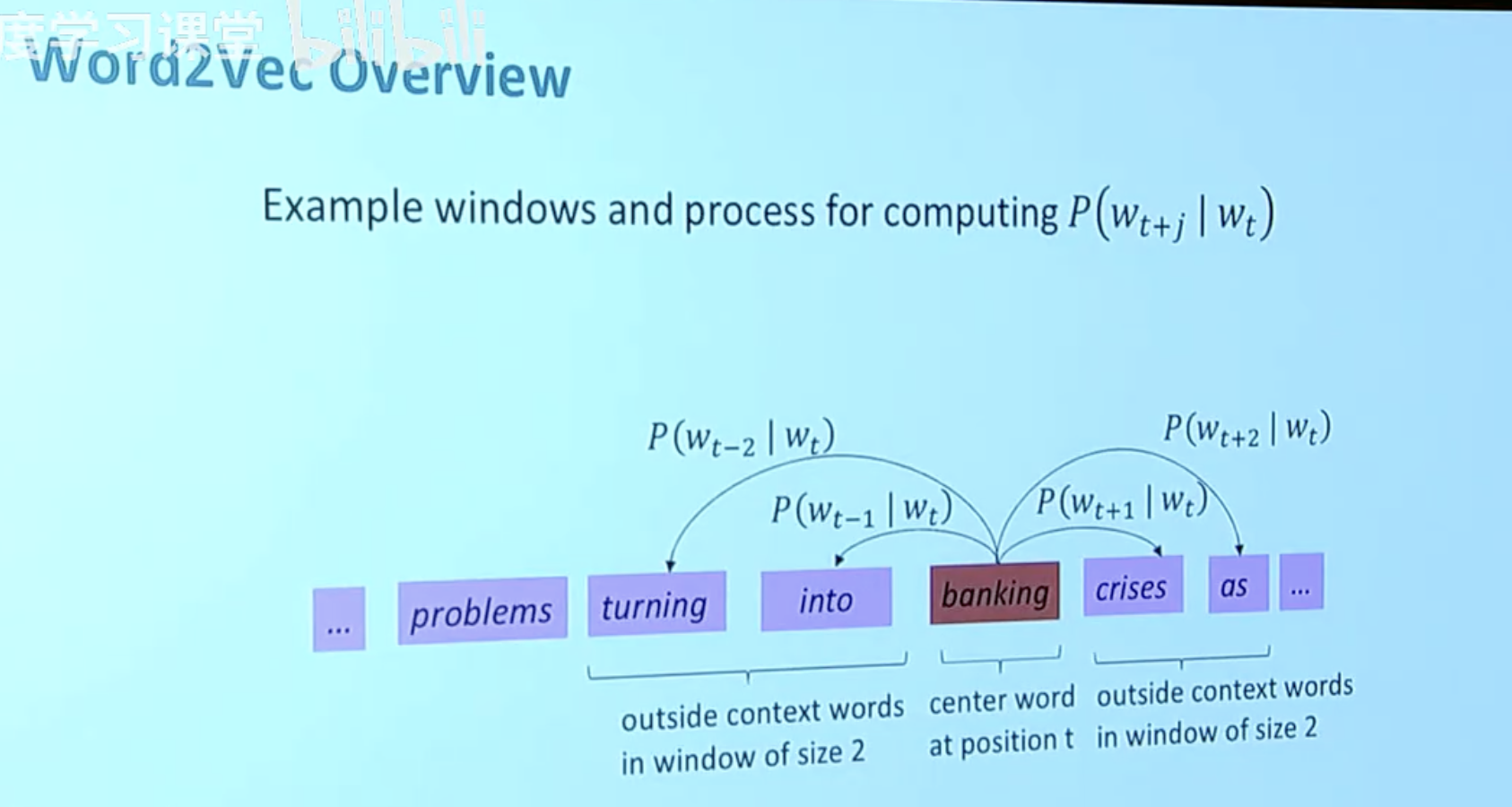
Word2Vec 包含两种主要架构,而你图片中重点展示的是最经典的 Skip-gram 模型。
在 Skip-gram 模型中,我们的目标是:给定中心词,预测窗口内的上下文词。
窗口大小 (Window size):如图所示,当窗口大小 m=2 时,意味着对于中心词 w_t,我们需要预测它左边两个词 (w_{t-2}, w_{t-1}) 和右边两个词 (w_{t+1}, w_{t+2})。
预测过程:模型会计算条件概率 P(w_{t+j} | w_t)。例如,当中心词是 "into" 时,模型要去预测周围出现 "banking" 或 "turning" 的概率。

3. “双向量”设计
为了简化数学计算,Word2Vec 为每个单词 w 准备了两个向量:
v_w:当单词 w 作为中心词时的向量。
u_w:当单词 w 作为上下文词时的向量。
这两个向量共同存储在一个巨大的参数矩阵 theta 中。在训练结束后,我们通常会将这两个向量相加或取平均,或者直接使用中心词向量作为该词的最终表示。
第五节:目标函数与优化
Word2Vec 的神奇之处在于它能将复杂的语言直觉转化为严谨的数学优化问题。我们要做的就是通过调整向量参数,让模型在看到中心词时,给实际出现的上下文词分配最高的概率。
1. 似然函数 (Likelihood)
对于语料库中的每一个位置 t = 1, ... , T,在给定固定窗口大小 m 的条件下,我们希望最大化所有预测正确的概率。其似然函数表示为:
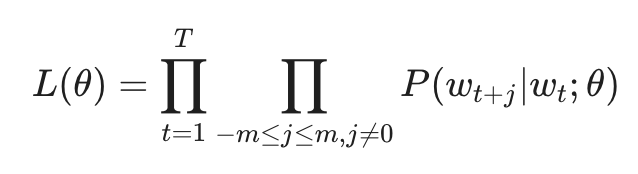
其中 theta 代表我们需要优化的所有词向量参数。
2. 目标函数 (Objective Function)
在深度学习中,我们通常习惯于“最小化”一个损失函数。因此,我们对似然函数取负对数(Negative Log Likelihood),得到目标函数 J(theta):
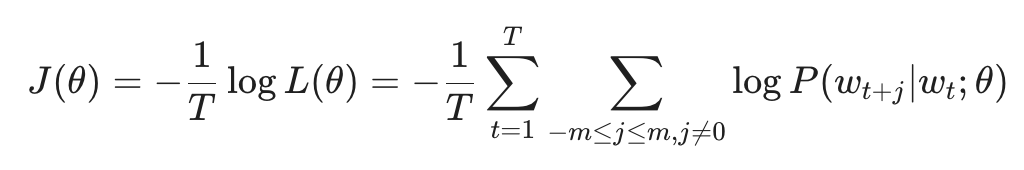
最小化这个函数,等同于最大化预测的准确性。

3. 如何计算概率?
如何衡量 P(o|c)(给定中心词 c 预测上下文词 o 的概率)?我们使用 Softmax 函数:
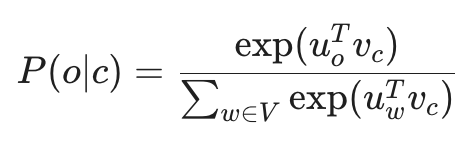
分子:u_o^T v_c 是中心词向量 v 和上下文词向量 u 的点积。点积越大,代表两个词越相似,概率也就越大。
分母:对整个词汇表 V 进行指数求和,起到归一化的作用,确保所有可能的上下文词概率之和为 1。

4. 训练模型:梯度下降 (Gradient Descent)
有了目标函数 J(theta) 后,剩下的就是工程问题了。模型会计算 J(theta) 对每一个词向量维度的梯度(Gradient),然后沿着梯度的反方向不断更新 theta,直到找到能让预测误差最小的那组向量值。
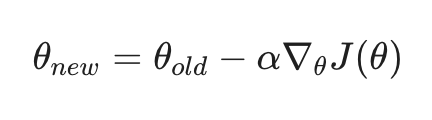

第六节:词向量的可视化与未来
当 Word2Vec 模型在数以亿计的语料上完成训练后,每一个单词都不再是孤立的符号,而是变成了高维空间中的一个坐标点。
1. 语义空间的“美感”:可视化
虽然词向量通常有几百个维度,人类无法直接感知,但通过 t-SNE 或 PCA 等降维技术,我们可以将其投影到二维平面上。
你会惊奇地发现,计算机在没有任何人工干预的情况下,仅仅通过“预测上下文”就学会了人类语言的逻辑:
近义词聚类:意思相近的词(如 think, expect, say)会聚在一起。
逻辑关系平移:著名的 King - Man + Woman 大约为 Queen 现象,展示了向量空间具备线性的语义结构。
2. 词向量的局限性
尽管 Word2Vec 开启了 NLP 的新纪元,但它有一个致命的弱点:它是静态的(Static)。
一词多义问题:在 Word2Vec 中,单词 "bank" 只有一个向量。无论它是指“银行”还是“河岸”,其向量表示都是完全一样的。
缺乏语境敏感性:模型无法根据当前句子的特定语境实时调整词义。
3. 迈向大模型时代
为了解决静态词向量的问题,NLP 领域后来发展出了以 BERT、GPT 为代表的动态词向量技术(Contextualized Word Embeddings)。
它们不再给每个词一个固定的向量,而是根据上下文动态计算。
这种思想直接孕育了今天我们所熟知的各类大语言模型(LLM)。