
一、协同过滤算法简介
协同过滤算法是一种常见的推荐系统方法,它的核心思想是“物以类聚,人以群分”。也就是说,如果两个用户在过去对某些物品的兴趣相似,那么他们对其他物品的兴趣也很可能相似。换句话说,用户的行为和偏好可以相互参考。
通俗理解:
就像你会向朋友请教电影推荐:如果你和朋友过去喜欢的电影很接近,那么朋友喜欢的新电影,你也有很大概率会喜欢。协同过滤算法正是利用这种“群体智慧”来预测和推荐。
二、问题动机
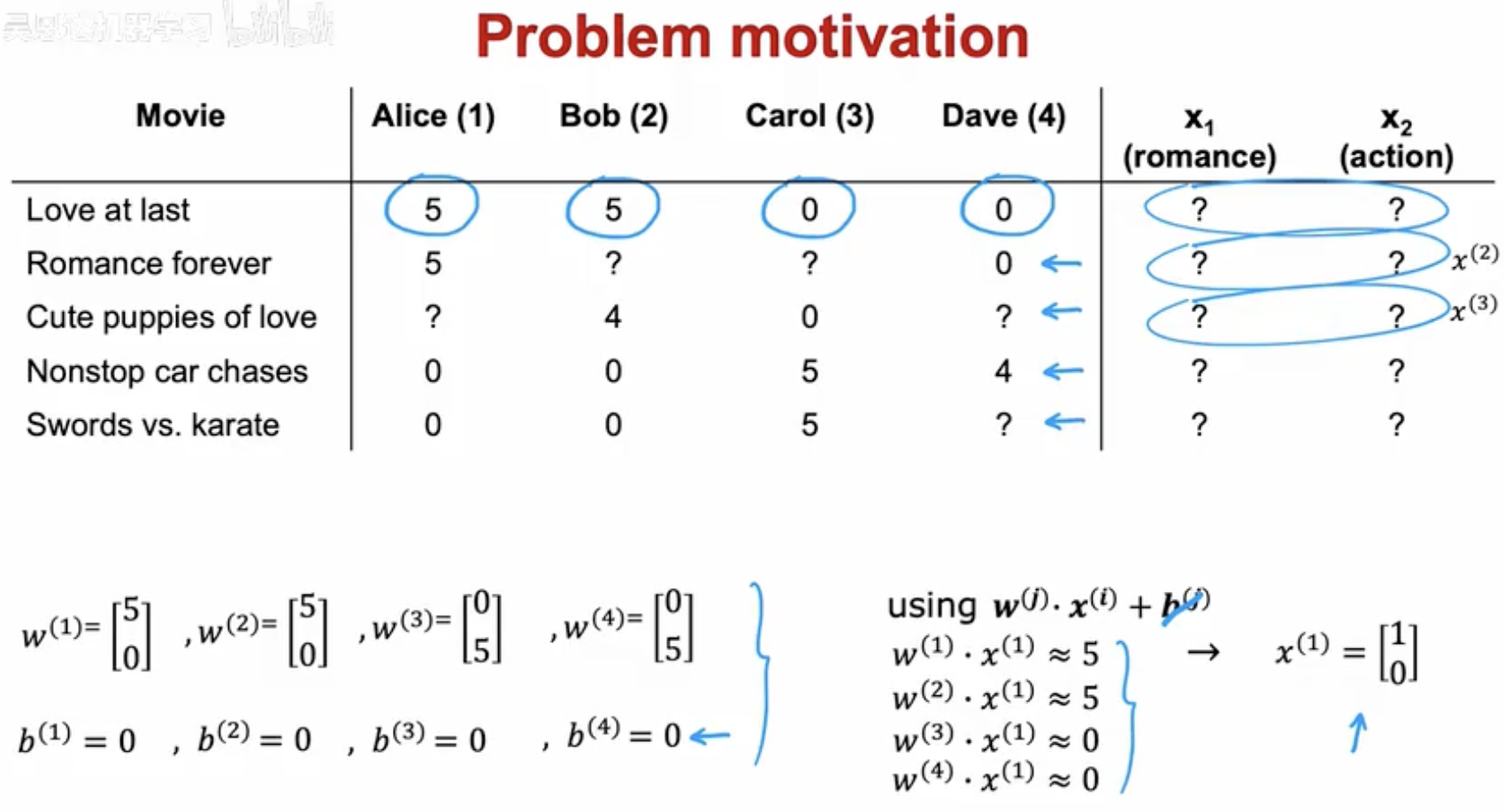
在推荐系统中,常见的挑战是:用户只对一小部分物品打过分,而大部分物品的评分是缺失的。比如图中展示的电影评分表:
Alice 喜欢浪漫题材的电影,对《Love at last》给了 5 分,但对动作片《Swords vs. karate》给了 0 分。
Bob 的偏好与 Alice 类似。
Carol 和 Dave 则更喜欢动作片,对浪漫片打了低分甚至 0 分。
问题是,很多位置都是 问号(未知评分),我们想要预测这些缺失值,从而推荐用户可能喜欢的电影。
为了解决这个问题,算法引入了 向量表示:
每个电影用一个特征向量表示,比如用两个维度:浪漫 (romance) 和动作 (action)。
每个用户用一个权重向量表示,刻画他们对不同特征的偏好。
这样,用户对某部电影的预测评分可以表示为:
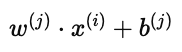
其中 w(j) 是用户向量,x(i) 是电影特征向量,b(j) 是偏置项。
直观理解:如果用户 Alice 的偏好是“浪漫 5 分,动作 0 分”,而电影《Love at last》的特征是“浪漫强,动作弱”,那么两者的点积会得到一个较高的预测评分。
三、代价函数
在协同过滤中,我们的目标是通过学习电影特征向量 x(i) 和用户权重向量 w(j),让预测评分尽量接近用户的真实评分。为了衡量预测值与真实值之间的差距,我们引入了代价函数。
具体来说,如果用户 j 对电影 ii 打过分 y(i,j),则预测值为:

代价函数定义为:

其中:
第一项表示预测评分与真实评分的误差平方和,只对已评分的用户 r(i,j)=1r(i,j)=1 进行计算。
第二项是 正则化项,用来限制参数大小,防止过拟合。
直观理解:
如果预测结果和用户的真实打分差距很大,代价函数就会变大,算法会调整参数来减小误差。
正则化项相当于“惩罚”过于极端的参数,保证模型更稳健。
当我们要同时学习多个电影的特征向量时,代价函数会累加所有电影的误差,目标就是最小化整体的预测误差。
四、协同过滤的完整公式
在前一节里,我们只考虑了如何学习 电影特征向量 x(i)。但在协同过滤中,我们还需要同时学习 用户权重向量 w(j)。
(1)学习用户权重向量
当固定电影特征向量 x(i) 时,用户权重向量的代价函数为:

这部分负责找到每个用户的兴趣偏好向量(比如 Alice 偏好浪漫,Carol 偏好动作)。
(2)学习电影特征向量
当固定用户向量时,代价函数为:

这部分负责刻画每部电影的“特征标签”(比如某电影浪漫强,某电影动作强)。
(3)联合优化
最终,把两部分结合起来,就得到协同过滤的整体优化目标:

这里同时学习用户和电影的向量表示,从而使预测的评分最接近真实评分。
直观理解:
用户向量表示“偏好”,电影向量表示“特征”。
两者点积得到评分预测。
不断调整它们,使得预测尽可能符合历史数据。
五、总结与应用场景
协同过滤算法的核心思想是:通过同时学习 用户的兴趣偏好向量 和 物品的特征向量,来预测用户对未评分物品的兴趣程度。它利用了群体的历史行为数据,不依赖复杂的领域知识,是推荐系统中最经典的方法之一。
在实际应用中,协同过滤被广泛用于:
电影推荐(Netflix、豆瓣电影),根据你和其他用户的相似喜好推荐影片;
音乐推荐(Spotify、网易云音乐),预测你可能喜欢的歌曲;
电商推荐(亚马逊、淘宝),根据相似用户的购买行为推荐商品;
社交平台推荐(YouTube、抖音),推荐视频或内容。
但它也存在一些局限性:
冷启动问题:新用户没有历史评分,新物品没有被打过分,模型难以给出预测;
稀疏性问题:在庞大的评分矩阵中,已知评分往往只占很小一部分,数据不足可能导致推荐不准确。
为了解决这些问题,业界常结合 矩阵分解(Matrix Factorization)、深度学习推荐模型(如神经协同过滤,Neural CF)等方法进行改进。