
一、协同过滤 vs 基于内容的过滤

推荐系统的两大主要方法是 协同过滤(Collaborative Filtering) 和 基于内容的过滤(Content-based Filtering)。这两种方法的核心思想不同,各有优缺点。
1. 协同过滤
协同过滤的思路是:
如果两个用户在过去的评分中表现出相似的偏好,那么他们很可能会喜欢相似的物品。
例如,假设你和另一位用户都喜欢同样的几部电影,而那位用户还喜欢一部你没看过的电影,那么系统就会把这部电影推荐给你。
特点:
依赖用户之间的相似性。
推荐结果不依赖物品本身的特征,而是依赖“群体智慧”。
2. 基于内容的过滤
基于内容的过滤思路是:
推荐系统会分析用户的特征(如年龄、性别、兴趣等)和物品的特征(如类型、年份、风格等),然后通过特征匹配来做推荐。
例如,用户 A 偏好“动作片”,那么系统会找到所有“动作片”类型的电影推荐给他。
特点:
推荐结果依赖特征工程,强调“用户画像”和“物品画像”。
不需要其他用户的评分数据。
对比总结:
协同过滤:基于用户相似度,适合用户数据丰富的场景。
基于内容:基于特征匹配,适合新用户或者用户群体稀疏的情况。
二、用户和物品特征
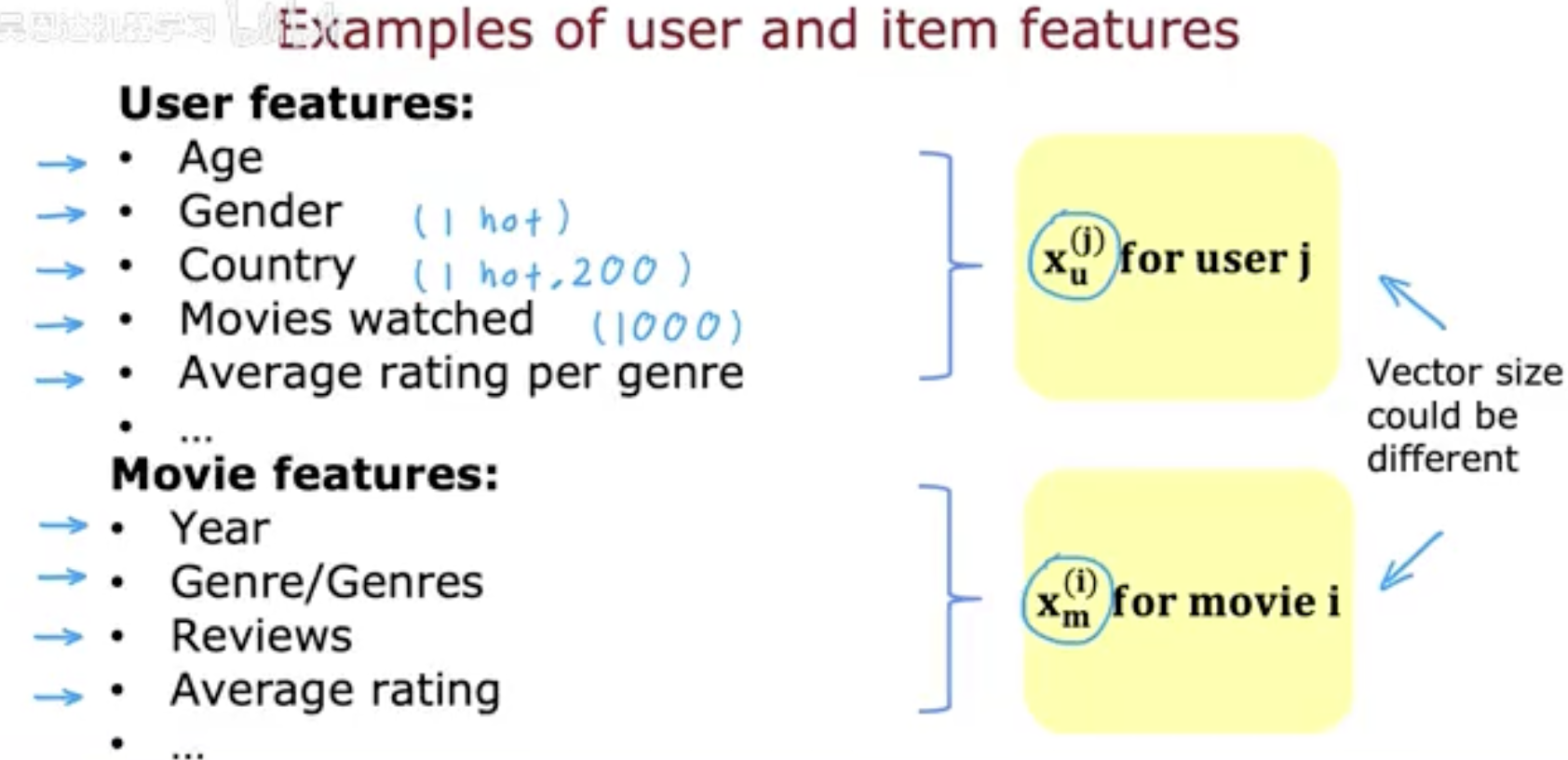
在基于内容的过滤中,推荐效果很大程度上依赖于 如何刻画用户和物品的特征。这一步通常被称为 特征表示(Feature Representation)。
1. 用户特征(User Features)
用户特征可以包含多种信息:
人口统计学信息:年龄、性别、国家/地区等。
行为数据:用户看过的电影、点击过的商品、平均评分偏好。
兴趣偏好:对某些类型内容的偏好强度,例如动作片、浪漫片等。
在实现时,这些特征可以用向量表示。例如,性别可以用 one-hot 编码,国家可以用一个较长的 one-hot 向量表示,观看过的电影数量可以用数值表示。
2. 物品特征(Item Features)
物品特征则反映了物品本身的属性:
基础属性:如电影的年份、导演、演员、评分。
类别标签:如电影的类型(动作、浪漫、喜剧等)。
用户反馈:对该物品的平均评分或评论关键词。
同样,这些信息也会被编码成向量。例如,一部电影可以被表示成一个特征向量,包含其类型标签、上映年份和平均评分等。
3. 用户与物品特征向量的不同
需要注意的是,用户特征向量和物品特征向量的 维度可能不同。因此在后续建模时,通常需要引入映射函数或权重矩阵,把它们映射到一个 统一的潜在空间,以便计算匹配度。
三、基于特征的匹配机制

在获得用户和物品的特征向量之后,基于内容的过滤需要解决的核心问题是:如何利用这些特征来预测用户对某个物品的偏好?
1. 用户特征向量与物品特征向量的映射
用户特征向量 xu(j):描述了用户 j 的属性(如年龄、兴趣)。
物品特征向量 xm(i):描述了物品 i 的属性(如类型、年份)。
通过学习权重矩阵,可以将两者分别映射为潜在表示(latent representation):

其中,vu(j) 表示用户的潜在兴趣,vm(i) 表示物品的潜在特征。
2. 匹配机制
得到潜在表示后,推荐系统通过计算 相似度 或 内积 来衡量用户和物品的匹配程度:
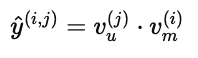
其中,y^(i,j) 表示预测的用户 j 对物品 i 的偏好评分。
3. 示例
如果用户向量 vu(j) 显示该用户更偏好“浪漫”类型,而某部电影的向量 vm(i) 在“浪漫”维度上权重较高,那么两者的内积就会较大,系统会预测用户喜欢这部电影。
反之,如果特征不匹配(例如用户偏好动作片,而电影是浪漫片),预测评分就会较低。
四、实践中的实现与扩展
基于内容的过滤不仅在概念上简单易懂,而且在实践中有明确的数学框架来实现。
1. 训练过程
推荐系统的目标是让预测评分 y^(i,j)y^(i,j) 尽量接近真实评分 y(i,j)y(i,j)。
损失函数常采用均方误差(MSE):
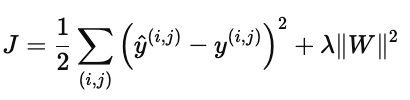
其中 λ∥W∥2 是正则化项,用来防止过拟合。
2. 梯度下降优化
通过反向传播计算梯度,不断更新权重矩阵 Wu,Wm,逐步提升预测的准确度。
这一步和之前讲到的 梯度下降 一脉相承。
3. 扩展与改进
非线性建模:可以在用户特征和物品特征之间引入神经网络,使匹配关系更加复杂和灵活。
多模态信息:不仅限于文本标签,还可以使用图像特征(海报)、音频特征(音乐风格)等来增强推荐。
混合推荐(Hybrid Recommendation):结合协同过滤和基于内容的方法,在冷启动和数据稀疏时尤其有效。
4. 实际意义
这种方法让系统不仅能依赖“别人喜欢什么”,还可以基于用户和物品自身的特征来做推荐。这对 新用户 或 新物品 尤为重要。