
一、带标签数据在异常检测中的评估作用

这幅图片强调的是在异常检测系统开发与评估中,实数化评估的重要性。在构建学习算法的过程中,比如特征选择或模型设计,如果能够通过量化的方式对算法进行评估,决策会更加明确和高效。
图中假设我们拥有带标签的数据,标签 y=0 代表正常样本,y=1 代表异常样本。在训练阶段,训练集通常只包含正常样本,用来学习“正常”的数据分布,因此这里标注 y=0。接着,在交叉验证集和测试集中,会包含部分异常样本。交叉验证集被写作 (xcv(1),ycv(1)),…,(xcv(mcv),ycv(mcv)),并特别注明要包含一些 y=1 的异常样本;而测试集同样以 (xtest(1),ytest(1)),…,(xtest(mtest),ytest(mtest)) 的形式给出。这样设计的目的,是在保证训练过程聚焦于正常模式的同时,通过验证集和测试集中的少量异常点,对模型的异常检测能力进行量化检验。
例子

这幅图以“Aircraft engines monitoring example(飞机发动机监控示例)”为标题,给出一个极度不均衡的数据设定:共有 10000 台正常(good/normal)发动机,以及 20 台有缺陷(flawed/anomalous,标注 y=1)的发动机。红色批注在“good (normal)”处标出提示,在“flawed engines”处标注 y=1。
上半部分给出一种划分方案。Training set:只使用 6000 台正常发动机(y=0)来训练,旁边红字写着“Train algorithm,y=0”。CV(交叉验证集):包含 2000 台正常发动机(y=0)和 10 台异常发动机(y=1),“10”被红圈强调,并在右侧有红色箭头批注。Test(测试集):同样包含 2000 台正常发动机(y=0)和 10 台异常发动机(y=1)。右侧旁注处出现符号 ε 与 xj 的红色标记,箭头对准验证/测试这一行。
下半部分给出 Alternative(替代方案)。Training set 仍为 6000 台正常发动机;CV 调整为 4000 台正常发动机(y=0)加 20 台异常发动机(y=1);并明确写出 “No test set”(不再单独留出测试集)。整幅图的红色划线、圈注与箭头用于强调各集合的规模与是否包含异常样本。
二、异常检测的阈值判别与评估

这幅图题为“Algorithm evaluation(算法评估)”。首先说明训练步骤:在训练集 x(1),x(2),…,x(m)上拟合模型 p(x)。这里的 p(x) 被红框标注,表示它是后续判别的核心量。
接着给出预测规则:对交叉验证/测试样本 x,按照阈值 ε 决策
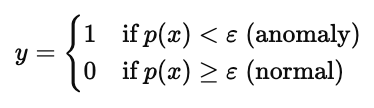
图中对 p(x)与 ε 分别做了红色标注,强调当样本的概率评估值低于阈值时判为异常(y=1),否则判为正常(y=0)。右侧手写的“10”“2000”对应前面示例里验证/测试集中异常与正常样本的数量提示。
随后列出可用的评估指标:混淆矩阵四项(true positive、false positive、false negative、true negative),以及基于它们计算的 Precision/Recall 和 F1-score。最后一行说明可以使用交叉验证集来选择阈值参数 ε。