
第一节:NLP 分类任务的本质挑战
在自然语言处理(NLP)的演进过程中,我们始终在解决一个核心矛盾:语言的离散符号本性与语义的连续复杂性之间的冲突。
从离散符号到分布式表示
早期的 NLP 依赖于独热编码(One-hot encoding),这种方式将单词视为孤立的符号,无法捕捉词与词之间的相似性。随着深度学习的兴起,分布式表示(Distributed Representations) 彻底改变了游戏规则。通过将单词映射到低维连续向量空间,我们赋予了计算机捕捉潜在语义的能力。
语义的“多面性”:词义消歧的难题
然而,向量化并不能一劳永逸地解决所有问题。语言中普遍存在的**多义性(Polysemy)**是分类任务的一大障碍。

以单词 "pike" 为例,它在不同语境下可以指一种武器、一种鱼、一条铁路线,甚至是跳水中的一种姿势。对于专业人士来说,这里存在一个本质疑问:一个固定的静态词向量,究竟是捕捉到了这些含义的某种“叠加态”,还是仅仅制造了一团语义混沌(a mess)?
线性分类器的天花板
在传统的统计学习中,我们通常使用线性 Softmax 分类器来处理这些词向量特征。其数学表达为:
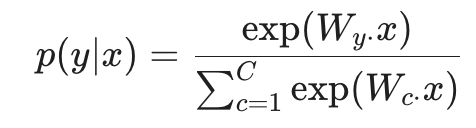

这种分类器的局限性在于它只能在向量空间中提供线性决策边界(Linear Decision Boundary)。如上图所示,当数据分布呈现复杂的非线性结构时,简单的线性划分(图中上方的红绿分割)会造成大量的分类错误。
迈向神经化分类
为了突破这一瓶颈,我们需要转向神经网络。与传统分类器不同,神经网络不仅学习分类权重 W,更在训练过程中不断优化单词的表示(Representations)。
通过引入非线性激活函数和多层架构,我们能够将原始向量投影到更高阶的特征空间,使原本线性不可分的数据在新的空间中变得清晰可分。本系列文章将带你深入探索这一演进过程:从理解词向量内部的线性叠加结构,到构建能处理复杂上下文的非线性神经分类器。
第二节:语义的“叠加”与“解构”
在上一节中,我们提出了一个挑战:一个静态的词向量如何承载多个截然不同的词义?对于专业人士来说,这不仅是一个直觉问题,更是一个数学结构问题。
词义的线性叠加假说
早期的观点认为多义词会导致向量空间的“混乱”,但近年来的研究(如 Arora 等人, 2018)提出了一个优雅的解释:线性叠加(Linear Superposition)。

根据这一理论,一个多义词的全局词向量(如 Vpike)实际上是其所有不同词义向量的加权平均值:
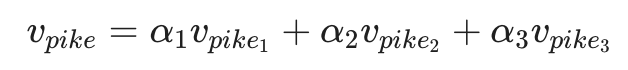
其中权重 alphai 由该词义在语料库中的频率 fi 决定。令人惊讶的结果是,由于高维向量空间中的稀疏编码(Sparse Coding)特性,只要这些词义相对常见,我们实际上可以将这些重叠的语义重新分离出来。
全局上下文与多原型改进
尽管线性叠加解释了静态向量的内在结构,但在实际训练中,为了获得更纯净的语义表示,研究者们尝试了更直接的方法。

Huang 等人(2012)提出了一种多原型(Multiple Word Prototypes)模型。其核心思路是:
窗口聚类: 首先收集单词出现的上下文窗口。
重新标注: 对这些窗口进行聚类,并将每个单词根据其所属簇分配不同的原型标签(如 bank1, bank2)。
二次训练: 使用这些带有词义区分的标签重新训练模型。
这种方法在视觉化(如上图所示)中表现优异,它能清晰地将同一个物理符号(如 "jaguar")在向量空间中划分到“汽车”、“动物”或“软件”等不同的语义簇中。
这种“解构”对分类任务的意义
理解词义的线性叠加与聚类本质,对于后续的深度学习分类至关重要。如果我们知道输入向量 $x$ 本身就是一个包含多种潜在语义的“混合体”,那么我们就需要更强大的非线性分类器(如神经网络)来根据上下文环境,从这种叠加态中提取出当前任务最相关的特征。
第三节:从逻辑回归到深层感知器:分类器的神经化演进
在理解了词向量捕捉语义的数学基础后,我们需要探讨如何利用这些表示进行下游决策。在专业 NLP 任务中,分类器不再仅仅是最后一层的 Softmax,而是一个深度的、非线性的特征提取过程。
1. 神经单元:逻辑回归的生物学类比
对于专业开发者而言,理解神经网络的第一步是将逻辑回归(Logistic Regression)视为一个单一的神经元计算单元。

在这里:
输入 x:代表了单词或上下文的分布式表示。
非线性激活函数 f:如 Sigmoid 或 ReLU。它的作用至关重要——如果没有非线性层,无论网络堆叠多少层,最终都只能表达线性变换,无法处理复杂的决策面。
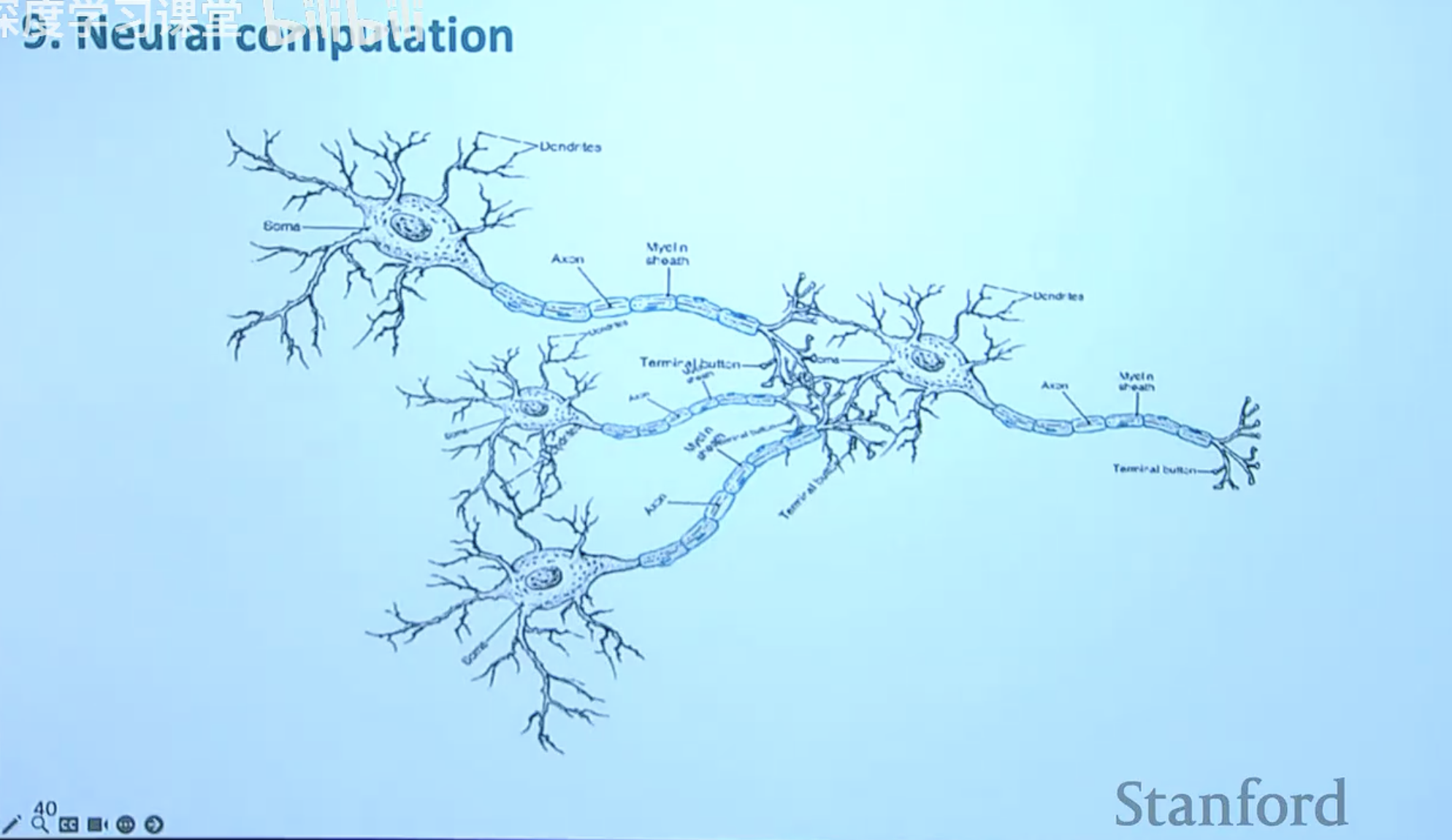
这种计算模型在生物学上可以找到对应:输入信号通过树突(Dendrites)进入,在细胞体(Soma)进行累加,最后通过轴突(Axon)传递。
2. 多层架构与“重表示”
单一神经元的能力有限,但当我们将多个逻辑回归单元并联并串联时,就构成了多层神经网络(Multilayer Neural Network)。
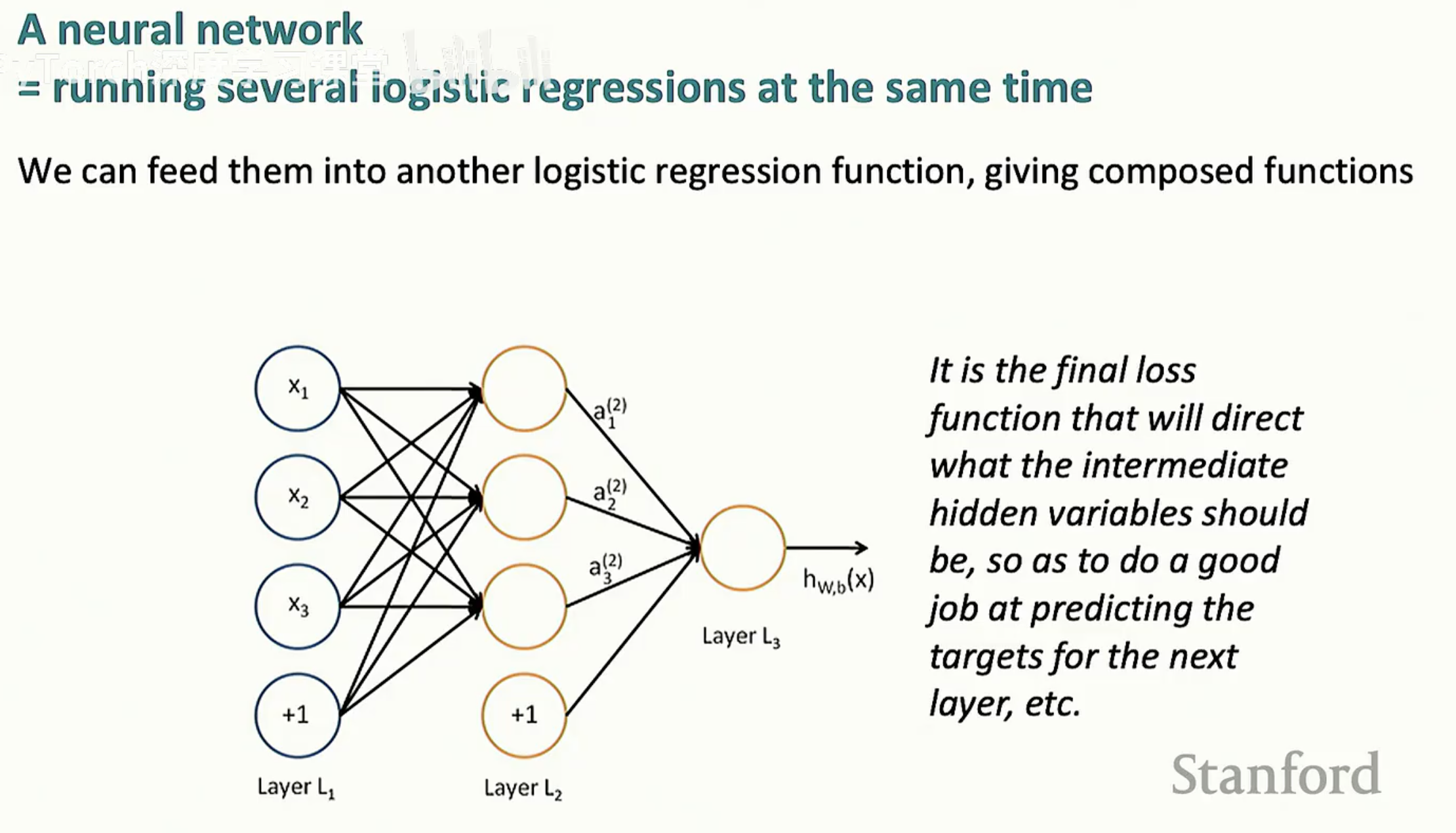
在深层模型中,每一层都在对数据进行重表示(Re-representation)。原始输入 x 通过隐藏层 L2, L3 的逐层转换,将复杂的语义特征进行组合。正如图片说明所指出的:虽然模型在原始输入空间是非线性的,但在倒数第二层(Pre-final layer)的表示空间中,类别往往已经变得线性可分。
3. 目标函数:信息论视角下的优化
为了训练这个复杂的非线性系统,我们需要一个能够量化“预测与真实之间差距”的指标。在多分类任务中,标准选择是交叉熵损失(Cross Entropy Loss)。

从数学上讲,我们的目标是最小化模型分布 q 与真实分布 p 之间的差异。由于真实标签通常是 One-hot 编码,损失函数简化为:
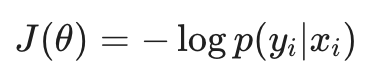
这个损失值产生的梯度将通过反向传播算法,指导中间隐藏层学习到最有利于分类的特征表示。这种“端到端”的优化正是深度学习优于传统特征工程的核心所在。
第四节:实战案例分析——命名实体识别 (NER)
在掌握了深度神经分类器的理论框架后,我们将其应用于 NLP 领域最基础也最核心的任务之一:命名实体识别 (Named Entity Recognition, NER)。这一任务不仅是信息抽取的基石,也是检验模型处理上下文歧义能力的试金石。
1. 任务定义与应用价值
NER 的核心目标是从非结构化文本中识别并分类出具有特定意义的实体。

分类体系:常见的标签包括人名(PER)、地点(LOC)、组织机构(ORG)和时间(DATE)等。
应用场景:NER 是构建知识图谱(Knowledge Base)的关键步骤,同时在问答系统(Answers are usually named entities)和情感分析中起到锚定主体的作用。
2. 窗口分类法 (Window Classification)
在处理 NER 时,一个孤立的词向量往往不足以判断其标签(例如 "Paris" 既可以是地点,也可以是人名的一位)。我们需要利用上下文窗口。

特征拼接:对于中心词 "Paris",我们取其左右邻近词(如各取 2 个),将它们的词向量拼接成一个高维向量 xwindow。
滑动窗口:模型在整个句子上运行分类器,为每一个单词及其窗口向量预测一个类别。
3. 构建二分类神经分类器
为了更精准地识别特定实体(如地点),我们可以构建一个专门的二分类神经网络。

该架构的数学流程如下:
输入层:拼接后的窗口向量 x。
隐藏层:通过线性变换和非线性激活函数得到隐藏表示 h = f(Wx + b),这里的 f 通常是 ReLU 或 Tanh。
输出层:计算得分 s = uT h,并经过 Sigmoid 函数 sigma(s) 得到概率。
4. 深度学习 vs. 传统方法的优势
传统的线性分类器在处理 "Paris" 这种多义项时,由于其决策边界是线性的,容易受到词向量本身“语义叠加”的干扰。而深度神经网络通过多层重表示,能够学习到:“如果左右邻居包含 'museums' 或 'in',则中心词更有可能是 LOC” 这种高阶非线性逻辑。
这种通过神经网络自动提取上下文特征的能力,使得 NER 系统的性能在深度学习时代得到了质的飞跃。
第五节:总结——通往深度语义理解之路
通过对词向量深层结构与神经网络分类机制的探讨,我们可以清晰地看到 NLP 技术演进的逻辑闭环:从静态的语义表示到动态的神经决策。
1. 核心逻辑回顾
本系列文章揭示了深度学习处理语言的三个关键层级:
语义的线性叠加:我们发现单向量并非杂乱无章,而是通过线性代数结构精妙地存储了多义词的不同维度。这种“叠加态”为模型提供了丰富的原始素材。
特征的神经重表示:通过多层神经网络,模型不再受限于原始输入的线性边界。每一层非线性变换都在对语义进行“提纯”与“解构”,使得复杂的逻辑在深层空间中变得清晰。
任务驱动的端到端优化:无论是 NER 还是其他分类任务,交叉熵损失函数都充当了“指南针”的角色。它引导模型在处理类似 "Paris" 这种多义项时,学会利用上下文窗口进行精准的非线性决策。
2. 深度学习的本质优势
对于专业人士而言,深度学习在分类任务上的统治地位并非偶然。

如上图所示,监督学习的本质是寻找从输入 $x$ 到标签 $y$ 的最优映射。传统方法往往在 $x$ 的构建(特征工程)上耗费巨大精力,而深度学习则实现了 “表示学习 (Representation Learning)” 与 “分类学习 (Classification Learning)” 的同步。这种端到端的模式,让模型能够自发地学习到如何“看懂”上下文。
3. 未来展望
从窗口分类器到如今的大规模语言模型(LLMs),虽然模型规模呈指数级增长,但其底层逻辑依然根植于此:捕捉分布式表示中的深层语义,并通过多层非线性变换实现对人类语言的理解。
理解了命名实体识别(NER)中的窗口分类原理,你就理解了 Transformer 架构中注意力机制(Attention)试图解决的核心痛点——如何更高效地聚合上下文信息以消除歧义。