
第一部分:引言
在深度学习的序列建模中,循环神经网络(RNN)曾被寄予厚望。然而,传统的 vanilla RNN 在实际应用中存在一个致命的缺陷:“短时记忆”。由于梯度消失问题,它很难捕捉到序列中跨度较大的长距离依赖关系。
为了打破这一瓶颈,长短期记忆网络(Long Short-Term Memory, LSTM) 应运而生。它不仅是深度学习历史上的一个里程碑,更是如今众多复杂序列模型(如早期的机器翻译、语音识别)的核心基石。
1. LSTM 的起源与演进
LSTM 的发展并非一蹴而就,而是经历了几代研究者的不断改良:
诞生(1997年): 由 Sepp Hochreiter 和 Jürgen Schmidhuber 首次提出。设计初衷非常明确:通过引入特殊的结构来克服 RNN 在反向传播中梯度消失(Vanishing Gradients)的问题。
现代形态的确立(2000年): 虽然 1997 年的论文是奠基石,但我们现在通用的 LSTM 版本中,一个至关重要的组件——遗忘门(Forget Gate),实际上是由 Gers 等人在 2000 年提出的。没有遗忘门,LSTM 很难有效地重置其记忆状态。
走向成熟(2006年): LSTM 开始展现出巨大的潜力,很大程度上归功于 Alex Graves 的工作。他不仅深入研究了 LSTM,还发明了 CTC(联结主义时间分类) 算法,这使得 LSTM 在语音识别领域取得了突破性进展。
工业级爆发(2013年): 随着 Alex Graves 加入 Geoffrey Hinton 在多伦多的团队并随后进入 Google,LSTM 正式被引入 Google 的大规模生产系统。这一举动标志着 LSTM 真正成为了解决大规模工业级序列问题的“标配”。
2. LSTM的特殊性
LSTM 的精妙之处在于它在隐藏状态(Hidden State)的基础上,引入了一个名为“细胞状态”(Cell State)的输送带。通过精心设计的“门控”结构,它可以有选择性地决定哪些信息应该被丢弃,哪些信息应该进入长期的记忆。

第二节:LSTM 的门控机制 (Gating Mechanism)
如果说传统 RNN 是一条只有单一流动渠道的河流,那么 LSTM 就像是在河流上建立了一系列精密的水闸。这些水闸(即“门”)决定了哪些水量(信息)可以流向下游,哪些应该被拦截或排放。
在这一节中,我们将拆解 LSTM 的数学定义。假设我们在时刻 t 有一个输入向量 x(t),LSTM 将计算出一系列中间门控状态,并最终更新细胞状态 (Cell State) c(t) 和隐藏状态 (Hidden State) h(t)。

1. 三大核心门控
所有的门控都使用了 Sigmoid 函数 (σ),这意味着它们的输出值都在 (0, 1) 之间。可以将其理解为“通过率”:0 代表完全关闭,1 代表完全通过。
遗忘门 (Forget Gate) f(t):

它负责观察上一个时刻的隐藏状态 h(t-1) 和当前输入 x(t),决定从上一个细胞状态 c(t-1)中丢弃哪些信息。
输入门 (Input Gate) i(t):

它决定了当前时刻有哪些新信息值得被写入到细胞状态中。
输出门 (Output Gate) o(t):
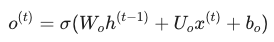
它控制细胞状态的哪些部分将被输出到当前的隐藏状态 h(t) 中。
2. 状态更新过程
除了门控,LSTM 还会计算一个新细胞内容 (-c(t)),它通常使用 tanh 激活函数,代表了当前时刻准备好的候选记忆:

最关键的一步是细胞状态 c(t) 的更新。这里使用了逐元素乘积(Hadamard Product):
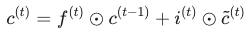
左半部分 :选择性遗忘旧记忆。
右半部分 :选择性添加新记忆。
最后,当前的隐藏状态 h(t) 由更新后的细胞状态经过 tanh 缩放后,再结合输出门得出:
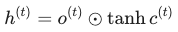
3. 为什么是逐元素乘积?
你会注意到公式中多次出现了 符号。这是因为在处理高维向量时,希望每一个维度都能独立受控。例如,在处理文本时,某个维度可能代表“句子的主语是单数还是复数”,门控机制可以精确地在这一维度上保持长期的记忆,而不干扰其他维度的信息。
第三节:直观理解数据在 LSTM 单元中的流动
公式虽然严谨,但往往略显抽象。为了更好地理解这些“门”是如何协同工作的,我们可以将 LSTM 的计算过程想象成一个精密的信息加工工厂。
在这个工厂里,细胞状态 (ct) 就像是一条贯穿整个生产线的传送带,它在序列的每一个时刻上方方流过,只有少量的分支与其交互。这种设计正是 LSTM 能够保持长期记忆的关键。
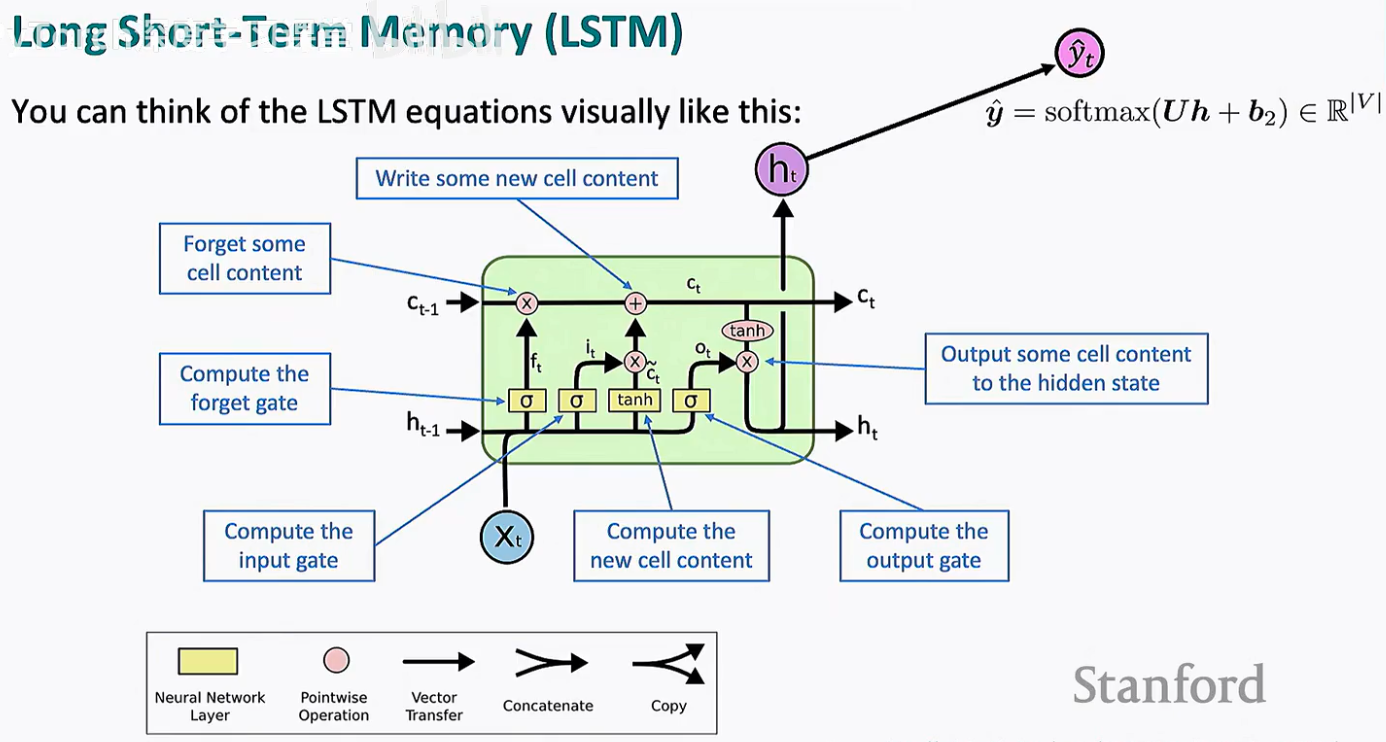
1. 传送带上的“加减法”
观察流程图的最上方,细胞状态 ct-1 到 ct 的变化仅仅经历了两个简单的点对点操作:
乘号 (x):这是遗忘门在起作用。如果遗忘门输出接近 0,传送带上的旧信息就会被抹去。
加号 (+):这是输入门在起作用。新的候选记忆 -ct 经过筛选后,被“焊”接到传送带上。
由于这种加法结构的线性特征,信息可以相对无损地跨越多个时间步传输,而不像 vanilla RNN 那样在每一步都经历剧烈的非线性变换。
2. 隐藏状态的生成
在工厂的下方,隐藏状态 (ht) 是由当前时刻的输入 xt 和上一时刻的隐藏状态 ht-1 共同计算得出的。
它首先参与所有门控(σ 框)的计算。
同时,它也是该时刻模型的对外输出(例如用于预测下一个词)。
最终的 ht 是细胞状态 ct 经过 tanh 激活后,再由输出门筛选出的“当前有用”的部分。
3. 图例说明
为了看懂这张流程图,我们需要注意底部的标识:
黄色方块:代表神经网络层(带有权重矩阵 W 和 U)。
粉色圆圈:代表点对点操作(如逐元素相乘 x 或相加 +)。
合并/分叉箭头:代表向量的拼接(Concatenate)或复制(Copy)。
通过这种可视化视角,我们可以清晰地看到:LSTM 实际上是在维护一个长期的全局记忆 (ct),并根据当前环境的需要,从中提取出短期的局部输出 (ht)。
4. 类比(通俗理解)
如果觉得原理图中的箭头太绕,不妨把整个 LSTM 单元想象成一个拥有魔法的日记本(细胞状态 ct):
日记本的页面(Cell State):这是贯穿你整个人生的长久记忆。它设计得很简洁,信息可以在上面保存很久。
遗忘门(擦除动作):当你翻开旧的一页,遗忘门就像一块橡皮擦。它会根据你今天的现状,决定擦掉日记里那些不再重要的旧信息(比如:你已经学会了某个知识点,就不再需要记住当初错误的解法)。
输入门(记录动作):它就像一支笔。它会筛选出今天发生的有意义的事情,并把它工整地写进日记本的空白处。注意,它只写那些“值得记”的东西。
输出门(提取动作):它就像你的嘴巴。当别人问你问题时,你不会把整本日记背给别人听,而是根据当前的语境,从日记本里提取出最相关的那一部分信息说出来(这就是隐藏状态 $h_t$)。
总结这个流动的过程:
先拿橡皮擦:处理掉没用的旧记忆(遗忘门)。
再动笔写:加入有用的新知识(输入门)。
最后开口说:根据现在的记忆,组织语言向外输出(输出门)。
正是因为这本“日记”是线性流动的,且每一次修改(加法和乘法)都非常克制,所以最初记录的信息才不会像普通 RNN 那样,在反复的“复读”中逐渐模糊变质。
第四节:LSTM 如何破解“梯度消失”
在 vanilla RNN 中,信息在每一个时间步都会被“重写”。如果你试图让它记住 50 个时间步之前的一个单词,那么梯度(误差信号)在反向传播回 50 层神经网络时,会经历连环的矩阵乘法,最终像消失在空气中一样化为零。
LSTM 的出现,将这种“约 7 个时间步”的记忆极限,直接推向了 100 个时间步甚至更高。

1. 信息的“无损通道”
LSTM 解决问题的关键在于其架构让 RNN 更容易保留跨越多个时间步的信息。
我们可以从两个极端情况来理解:
理想的保鲜状态:如果我们将某个维度的遗忘门设为 1(完全保留),同时将输入门设为 0(不引入噪音),那么该维度的信息就会在细胞状态中“无限期地”传递下去,完全不受时间步增加的影响。
对比 vanilla RNN:在普通 RNN 中,模型很难学习到一个能完美保持信息的循环权重矩阵 Wh。每一个步长都在进行非线性变换,梯度在连乘中极易崩溃。
2. 从乘法到加法的进化
梯度消失的根源在于链式法则中的连乘效应。
在普通 RNN 中,反向传播的梯度流是:

如果 Wh 的特征值小于 1,梯度就会迅速消失。
而在 LSTM 中,细胞状态 ct 的更新公式是:
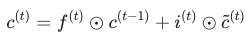
在计算梯度时,误差信号可以沿着 c(t) 到 c(t-1) 的路径,通过求和的形式回传。这种类似于“高速公路”的线性路径,允许梯度更加直接地流向遥远的过去。
3. 实际表现的跨越
Vanilla RNN:通常只能处理约 7 个左右的时间步,再长就会丢失逻辑。
LSTM:在实践中可以轻松处理约 100 个时间步。
虽然这看起来已经很强大了,但 LSTM 并不是万能的。当序列长度达到上千甚至上万(如长篇小说)时,即便是有门控机制的 LSTM 也会感到吃力。
第五节:梯度消失只是 RNN 的挑战吗?
通过前几节的分析,我们看到 LSTM 通过“门控”和“加法路径”巧妙地延长了记忆。但一个更深刻的问题随之浮现:梯度消失/爆炸现象,是否仅限于循环神经网络(RNN)?
答案是否定的。事实上,这是所有深度神经架构共同面临的顽疾,包括全连接网络(Feed-forward)和卷积神经网络(CNN)。
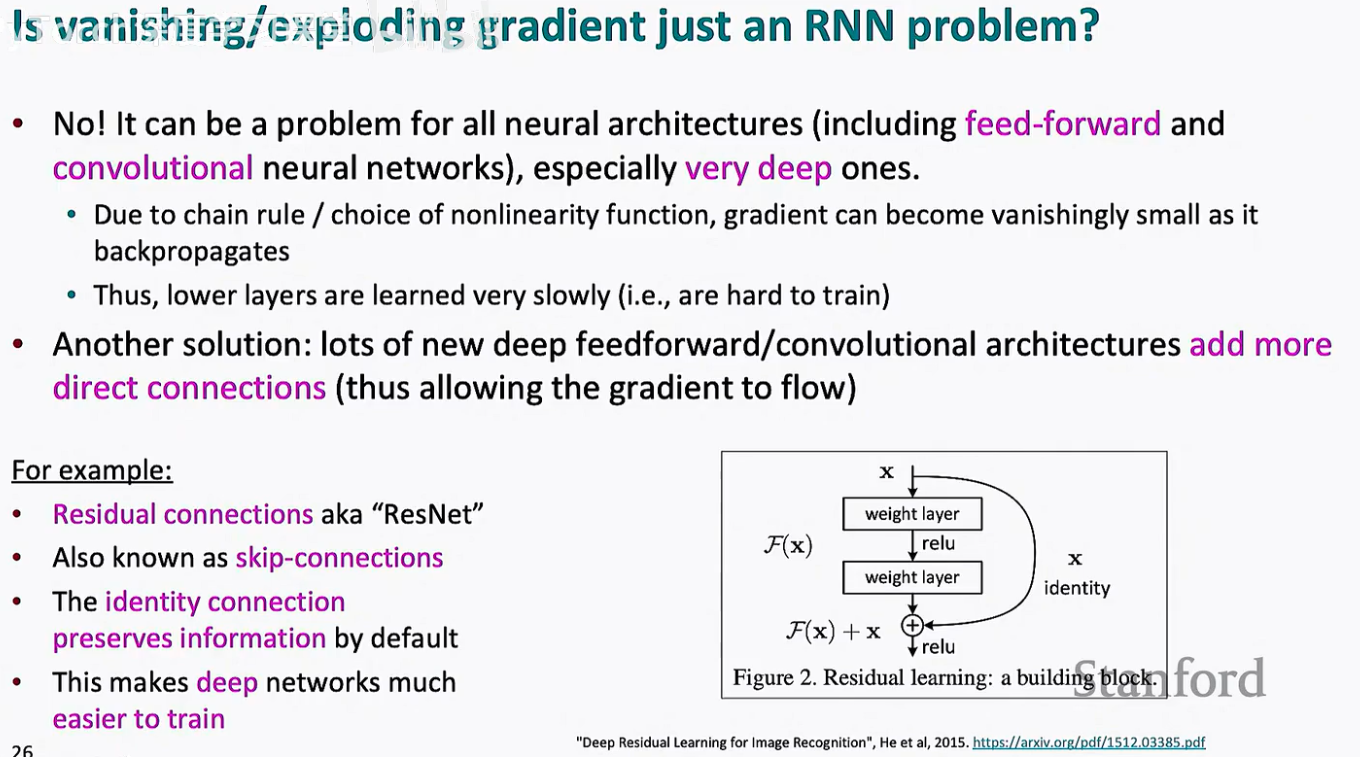
1. 深度网络中的共同挑战
随着网络层数的增加(比如达到 50 层甚至 100 层),根据微积分的链式法则,梯度在反向传播过程中需要穿过漫长的非线性激活函数层。
如果激活函数的导数小于 1(如 Sigmoid),梯度会呈指数级缩小。
结果就是:靠近输入端的底层(Lower layers)学习速度极慢,导致深层网络极难训练。
2. 现代架构的“进化论”:增加直接连接
为了让梯度能够顺利“流”向底层,现代深度学习架构借鉴了类似 LSTM 的思想——制造更直接、更线性的路径。
残差网络 (ResNet / Skip-connections):
这是深度学习史上最重要的突破之一。它不再强迫每一层都学习全新的特征,而是学习“残差” F(x)。
公式表达为:Output = F(x) + x。
这里的 x 就是一条恒等连接(Identity connection)。它让梯度在回传时拥有一条“无损快车道”,使得训练上千层的网络成为可能。
稠密连接 (DenseNet):
比 ResNet 更激进,它将每一层都与之后的所有层直接相连。这种极高的特征重用率,进一步缓解了梯度消失,并减少了参数量。
高速公路网络 (HighwayNet):
这是最直接受到 LSTM 启发的架构。它在全连接网络中引入了动态门控。
它通过一个变换门(Transform Gate)和一个携带门(Carry Gate)来决定多少信息经过非线性变换,多少信息直接原样通过。这简直就是把 LSTM 的逻辑搬到了非序列网络中。

结语:RNN 的不稳定与深度学习的未来
虽然梯度消失是一个通用问题,但 RNN 格外不稳定。正如 Bengio 等人在 1994 年指出的,RNN 必须在每个时间步重复乘以同一个权重矩阵。这种“连乘效应”让它比一般的深层网络更容易陷入数值崩溃。
从 LSTM 到 ResNet,再到如今统治 NLP 领域的 Transformer(其内部也大量使用了残差连接),深度学习进化的核心逻辑始终如一:建立更短、更直接的信息通道,让知识(和梯度)能够跨越时空的阻隔。