
一、策略(Policy)的概念
在强化学习中,策略(Policy) 是智能体的核心组成部分。它定义了在给定状态 s 下,智能体应该采取的动作 a。用数学表达式可以写作:

这表示策略 π 就是一个映射函数,它把环境中的状态(state)映射到某个动作(action)。
换句话说,策略回答了这样一个问题:
👉 “在当前的状态下,接下来应该做什么?”
在实际任务中,策略可能有两种形式:
确定性策略(Deterministic Policy):在相同状态下总是采取同一个动作,例如:
如果小车在状态 s 时总是往左走,那么这就是确定性的策略。
随机性策略(Stochastic Policy):在同一状态下可能采取不同动作,只是有一定概率分布,例如:
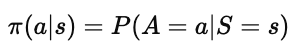
比如在棋局中,有时可能 70% 概率选择走左边,30% 概率选择走右边。
在强化学习中,策略是连接 状态 → 行为 → 奖励 的关键纽带。它决定了智能体与环境交互的方式,从而影响最终能获得多少回报。
二、强化学习的目标与策略优化
在强化学习中,策略 π 的最终目标并不是简单地选择动作,而是要通过动作的连续选择 最大化长期回报(Return)。
1. 强化学习的目标
强化学习的目标可以表述为:

其中:
π∗ 表示最优策略;
Gt 表示从时间步 t 开始的回报(Return);
目标是找到一个策略,使得智能体在任意状态下,都能选择能带来最大期望回报的动作。
简单来说,就是要学到一条规则:在不同状态下如何行动,才能让累计奖励最大化。
2. 策略优化的过程
为了优化策略,智能体需要不断与环境交互:
观察状态 s:比如火星车在某一格子里。
根据策略 π 选择动作 a:比如决定向左走还是向右走。
获得奖励 r 和下一个状态 s’:走对了可能接近奖励,走错了可能掉进“惩罚区”。
调整策略 π:根据反馈,逐渐改进策略。
这种不断改进的过程,就是强化学习中所谓的 trial-and-error(试错学习)。
3. 示例说明

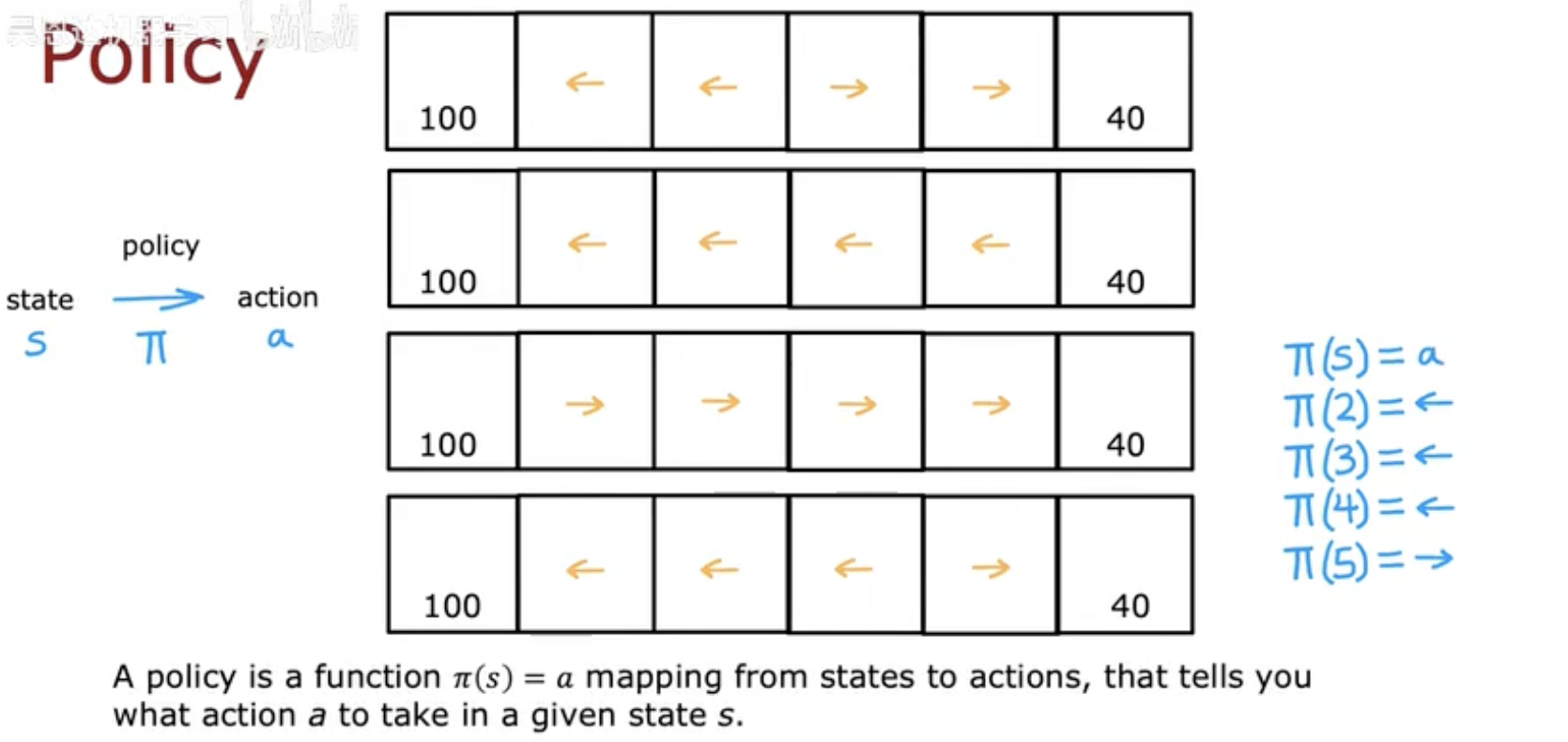
这张图(The goal of reinforcement learning)展示了一个智能体在网格世界中(左边奖励为 100,右边奖励为 40)。
策略 π 的任务就是告诉智能体在每一个格子中应该往哪走;
最终目标是找到一条最优策略,让智能体从任意起点出发,都能走到最高奖励的终点(100)。
因此,策略的价值并不是在某一步做得对,而是能保证在 整个任务过程中获得最大的累计回报。
三、策略在不同任务中的应用案例

策略(Policy)不仅仅是数学公式,它的应用涵盖了许多现实任务。你上传的第三张图展示了三个典型的强化学习场景:
1. 火星车 (Mars Rover)
状态 (states):火星车所在的格子,例如 [1,2,3,4,5,6]。
动作 (actions):火星车能往左走或往右走。
奖励 (rewards):不同格子对应不同奖励,如左边终点 100,右边终点 40,中间为 0。
策略 π:告诉火星车在某个格子中是往左走还是往右走。
目标:找到一条最佳路径,使火星车能够在有限步数内尽可能获得高奖励。
这就是最直观的“走迷宫”例子。
2. 直升机控制 (Helicopter)
状态:直升机在空中的位置、姿态等。
动作:如何移动操纵杆(上下、左右)。
奖励:如果直升机飞行稳定,给予正奖励 +1;如果操作失误导致坠机,给予巨大的负奖励 -1000。
策略 π:就是告诉直升机在当前状态下如何调整旋翼和操纵杆。
目标:让直升机能够自主飞行并保持稳定。
这个案例展示了强化学习在 复杂动态控制系统 中的应用。
3. 国际象棋 (Chess)
状态:棋盘上棋子的分布。
动作:所有可能的合法走法。
奖励:赢棋时 +1,和棋 0,输棋 -1。
折扣因子 (γ):接近 1(如 0.995),因为国际象棋对长远规划要求高。
策略 π:告诉玩家在当前局面下,哪一步走法能带来最大胜率。
目标:在对弈中不断优化走法,最终提高获胜概率。
这是强化学习在 博弈与人工智能对抗 中的典型应用(AlphaZero 就是代表)。
四、马尔可夫决策过程 (MDP) 与策略的关系
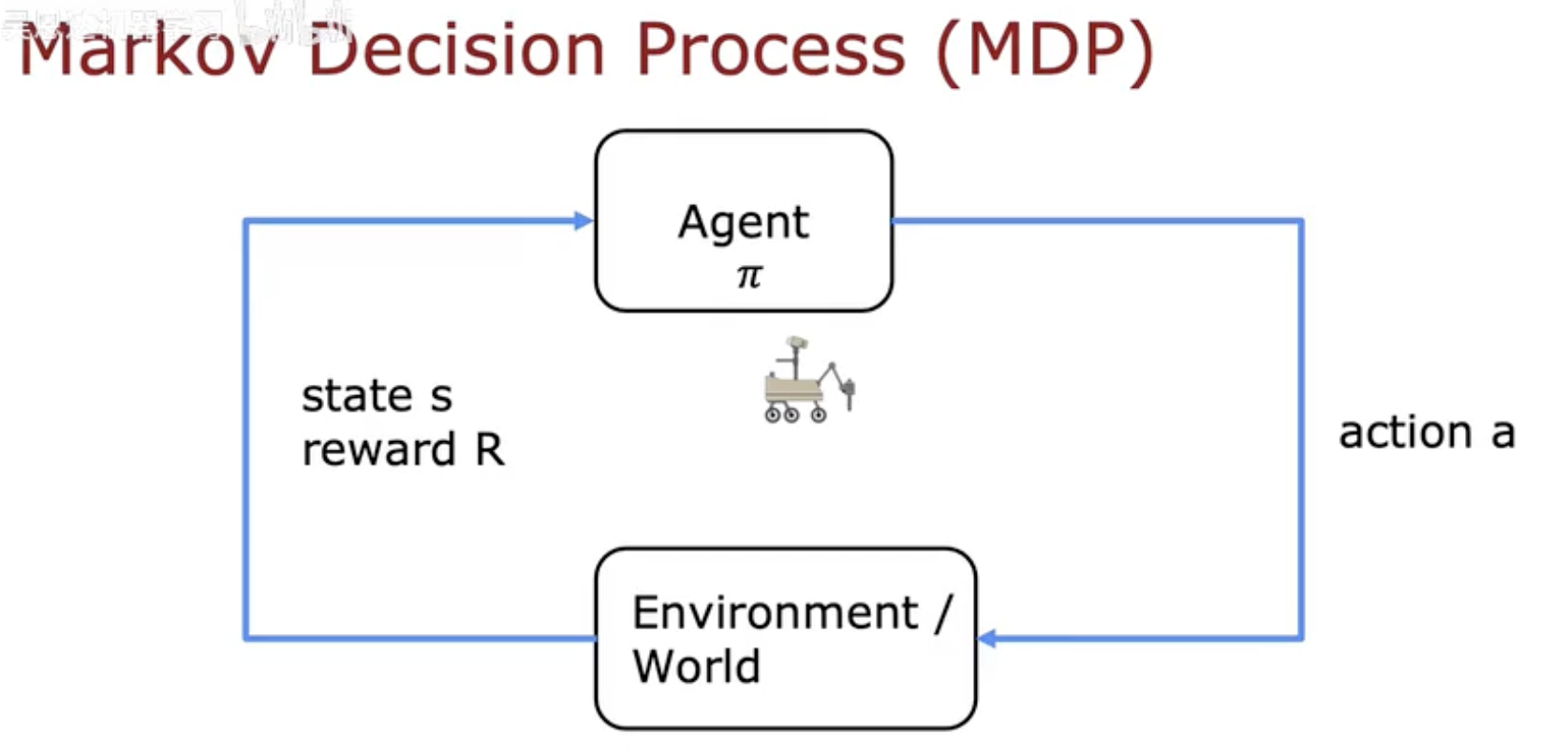
强化学习中的策略不仅是一个“状态到动作”的规则,还与整个 马尔可夫决策过程(Markov Decision Process, MDP) 紧密相关。
1. MDP 的基本组成
一个 MDP 通常由以下几个要素组成:
状态集合 (States, S):环境可能处于的所有状态。
动作集合 (Actions, A):智能体在某一状态下可以采取的所有动作。
状态转移概率 (Transition, P):执行某个动作后,环境转移到下一个状态的概率分布。
奖励函数 (Reward, R):动作带来的即时奖励。
折扣因子 (Discount, γ):衡量未来奖励的重要程度。
2. 策略 π 在 MDP 中的作用
策略 π 充当了智能体与环境之间的桥梁:
Agent 根据状态选择动作:
输入当前状态 s;
策略 π 输出要采取的动作 a。
Environment 接收动作并返回反馈:
给出下一个状态 s′;
给出奖励 r。
Agent 更新策略 π:
基于反馈不断改进未来的动作选择。
这种循环过程,就是强化学习最基本的交互机制。
3. 图示说明
图(Markov Decision Process)清晰地展示了这种循环:
Agent(智能体)使用策略 π 选择动作;
Environment(环境)根据动作反馈新状态和奖励;
这个过程不断重复,直到智能体学到最优策略 π*。
4. 小结
策略 π 在 MDP 中的角色,就像一个“导航器”:
它告诉智能体在不同状态下如何决策;
通过与环境的不断交互和反馈,策略逐渐被优化,趋近于最优策略。
因此,可以说 强化学习的核心目标就是在 MDP 框架下找到最优策略 π*。
五、总结
在强化学习中,策略(Policy) 是智能体决策的核心。它决定了在给定状态下采取哪一个动作,从而影响智能体能获得多少回报。
本文从多个角度阐释了策略的重要性:
策略是状态到动作的映射,可以是确定性的,也可以是概率性的。
强化学习的目标是通过不断试错和优化,找到一个最优策略,使得长期回报最大化。
在不同的任务中,策略的表现形式各不相同:火星车的移动、直升机的操纵、棋局中的走法,都是策略的具体体现。
策略是 MDP 框架的核心纽带,连接了智能体与环境的交互循环。
因此,理解和掌握策略,是学习强化学习的基础。未来更高级的主题(如价值函数、策略梯度、Actor-Critic 方法)都将基于这一核心概念展开。