
第一节:引言
在深度学习的序列建模中,循环神经网络(RNN)曾被寄予厚望。由于其循环连接的结构,理论上 RNN 能够保留无限长的历史信息。然而在实际训练中,你会发现它表现得非常“短视”——它能轻易记住上一个单词,却总是忘记上一个段落。
这种局限性的核心原因,在于反向传播(Backpropagation Through Time, BPTT)过程中发生的梯度消失(Vanishing Gradient)。
1. 梯度的“接力棒”效应
要理解梯度消失,我们需要观察 RNN 是如何计算误差并更新权重的。假设我们有一个 4 个时间步的简单序列,损失函数 J(4) 在最后一个时间步产生。为了更新第一步的参数,梯度必须从 h(4) 一路向后传递到 h(1)。
根据链式法则,我们计算目标函数对第一层隐藏状态的导数:
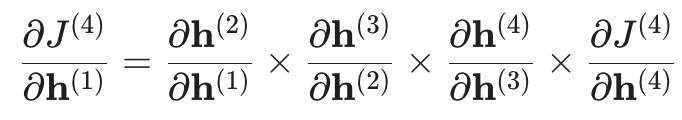

2. 当“接力”信号变弱时
正如上图所示,如果这些中间导数(步长间的交互)的值很小:
信号衰减: 随着反向传播的距离越来越远,梯度信号会呈指数级减小。
学习停滞: 到了序列的开头部分,梯度已经小到几乎可以忽略不计。
后果: 模型的权重更新将完全由“近期的”误差主导。这意味着模型无法学习到输入序列中远距离特征之间的逻辑关系。
简单来说,梯度消失让 RNN 变成了一个“金鱼脑”,它只记得刚发生的事情,而丢失了遥远的背景信息。
第二节:消失的本质(线性案例分析)
为了弄清楚梯度为何会消失,我们需要跳出直观印象,深入到数学推导中。虽然深度学习通常涉及复杂的非线性激活函数,但通过一个简化后的线性案例,我们可以清晰地看到问题的根源。
1. 模型简化与链式法则
假设我们的循环神经网络处于一个理想状态:激活函数 σ 是恒等函数(Identity Function),即 σ(x) = x。
此时,隐藏状态的计算公式简化为:
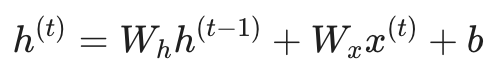
根据链式法则,相邻两个时间步隐藏状态的导数为:
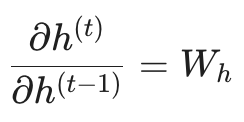
这就意味着,每回溯一个时间步,梯度就会被乘上一个权重矩阵 Wh。

2. 跨越 ℓ 个时间步后的恐怖效应
如果我们要计算第 i 步的损失对第 j 步隐藏状态的梯度(令跨度 ℓ = i - j),公式会变成:
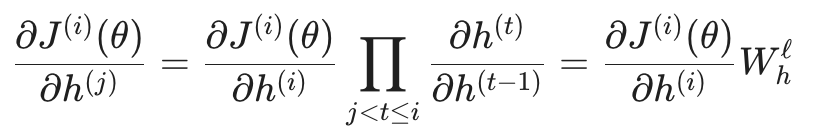
这里的关键点在于 Whℓ。当时间步跨度 ℓ 很大时,梯度的大小几乎完全取决于 Wh。
3. 特征值分析:跌入零的深渊
如果我们利用 Wh 的特征向量作为基底来展开这个公式,梯度的演变可以表示为特征值 λi 的 ℓ 次幂:
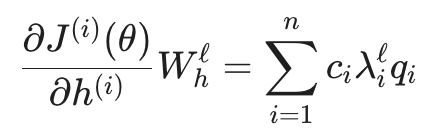
如果特征值 λi < 1: 随着跨度 ℓ 的增加,λiℓ 会以指数级速度趋近于 0。
这导致梯度信号在传递几十步后就彻底消失(≈ 0),模型无法感知到远处的任何反馈。

4. 非线性情况下的变体
现实中我们使用 tanh 或 sigmoid 等激活函数,情况依然类似。证明过程虽然更复杂(需要考虑激活函数的导数 σ'),但结论是一致的:只要权重矩阵和激活函数导数的乘积项较小,梯度依然会不可避免地消失。
第三节:梯度消失的实际影响
通过前两节的直观理解与数学推导,我们已经知道梯度在反向传播中会迅速衰减。但这种数学上的“趋近于 0”,在实际的深度学习任务(如自然语言处理)中究竟意味着什么?
1. 梯度的“竞争”:近距离 vs 远距离
在训练 RNN 时,模型参数的更新取决于所有时间步传回的梯度总和。
近距离梯度(Close-by): 路径短,信号强。
远距离梯度(Far away): 路径长,信号微弱。
当总梯度被近距离的信号主导时,模型会变得非常“功利”。它发现只需根据最近的几个单词就能大幅降低误差,于是它放弃了去学习那些复杂的、长距离的逻辑关系。
2. 经典案例:语言模型中的长期依赖失效
让我们来看一个具体的语言模型(LM)任务。请看下面这段话:
“当她试着去打印她的机票(tickets)时,她发现打印机没墨了。她去文具店买了一些墨盒。墨盒非常贵。在把墨盒装进打印机后,她终于打印了她的 ______。”
在这个填空任务中,为了预测出最后的词是 “机票(tickets)”,模型必须建立起第 7 个时间步(第一次提到机票)与结尾目标词之间的依赖关系。
RNN 的困境: 这个时间跨度可能超过了 20 或 30 个词。
消失的联系: 由于梯度消失,结尾处的误差信号无法有效地传递回第 7 步。对于模型参数而言,远处的“机票”二字仿佛根本不存在。
短视的预测: 经验表明,普通 RNN 的有效记忆长度通常只有 7 个 token 左右。它可能能预测出后面要接一个“名词”,但无法锁定是哪一个。

3. 结论:无法捕捉的语义逻辑
梯度消失不仅仅是一个数值稳定性问题,它直接限制了模型的认知能力。它让 RNN 只能学会简单的局部语法(如:冠词后接名词),而无法理解跨越段落的深层语义逻辑。
第四节:梯度爆炸
如果说梯度消失是让信号在深渊中渐渐微弱,那么它的极端反面——梯度爆炸(Exploding Gradient),则像是一场突如其来的地震,足以瞬间摧毁辛苦训练数小时的模型。
1. 什么是梯度爆炸?
回顾我们在第二节提到的数学推导:梯度的演变涉及 Whℓ。
当特征值 λi < 1 时,梯度消失。
反之,如果特征值 λi > 1,随着跨度 ℓ 的增大,梯度会以指数级速度膨胀。
2. 后果
在随机梯度下降(SGD)中,权重的更新公式为:

当梯度变得巨大时,更新步长也会随之失控。
错误的更新: 就像你本来只想在山坡上向下走一小步,结果因为步子太大,直接飞跃了山谷,掉到了遥远的“爱荷华州”。你不仅错过了最优解,还可能落入一个参数配置极差、损失函数极高的区域。
计算崩溃: 在最极端的情况下,由于数值超出了浮点数的表示范围,权重会直接变成 Inf(无穷大)或 NaN(非数值)。此时,除了从上一个检查点重启训练外,别无他法。

第五节:梯度裁剪(Gradient Clipping)
相比于隐晦的梯度消失,梯度爆炸是一个相对“暴力”且容易解决的问题。目前工业界最常用的手段是梯度裁剪(Gradient Clipping)。
1. 核心思想
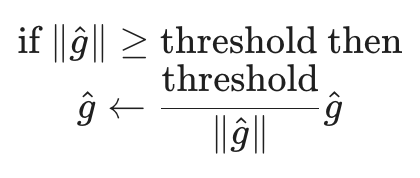
梯度裁剪的逻辑非常直观:如果梯度的范数(Norm)超过了一个预设的阈值(threshold),我们就强行把它按比例缩小。
其算法伪代码如下:
2. 它的直观意义
梯度裁剪并不会改变梯度的方向,它只是限制了更新的步长。
直观理解: 当模型想要“暴冲”时,我们把它拽住,让它依然朝着正确的方向走,但只允许走一小步。
实践建议: 在训练 RNN 或 Transformers 时,记得设置梯度裁剪几乎是标配操作。虽然它不能从根本上解决梯度消失问题,但它能极大地提高训练的稳定性。
