

1. 介绍(Introduction)
在医疗科技飞速发展的今天,数字病理学正迎来它的“高光时刻”。通过深度学习模型(Deep Learning),计算机能够以惊人的速度在成千上万张病理切片中捕捉到前列腺癌等疾病的蛛丝马迹。在理想的实验室环境下,这些算法的准确率往往能超过 98%,表现得像一位经验老道的专家。
然而,实验室里的“理想状态”与繁忙医院里的“真实世界”之间,隔着一道名为 伪影(Artifacts)的鸿沟。
完美的算法,不完美的切片
在现实的临床流程中,一张切片从手术台到数字化扫描仪,要经历组织固定、切片、脱蜡、染色、封片等多个环节。任何一个环节的小疏忽,都可能留下痕迹:
可能是载玻片上的一枚指纹;
可能是由于对焦不准导致的轻微模糊;
也可能是由于染色试剂批次不同带来的色调差异。
人类病理学家可以轻松“滤掉”这些噪声,但对于依赖像素特征的 AI 模型来说,这些微小的干扰是否会演变成严重的误诊?
压力测试:给 AI 的“极限运动”
为了探究这一问题,Schömig-Markiefka 等研究人员进行了一项极具启发性的研究。他们不仅使用了来自 4 个不同机构、由不同扫描仪生成的 6 个数据集,还通过数字模拟技术,对一个高性能的前列腺癌检测模型进行了“质量控制压力测试”。
他们并没有让 AI 处理完美的图像,而是故意在图像中加入了 12 种常见的伪影。
通过这种模拟,研究人员试图回答一个关键问题:当这些看似不起眼的伪影出现时,AI 的准确率会如何跌落?是依然稳如泰山,还是会溃不成军?
接下来的研究结果,可能会让每一个对 AI 充满乐观的人重新思考:我们离真正“临床可靠”的 AI 诊断,究竟还有多远?
2. 材料与方法(Materials And Methods)
2.1. 深度学习模型架构
研究选用的 AI 模型是基于 InceptionResNetV2 卷积神经网络架构 。该模型此前已在来自癌症基因组图谱 (TCGA) 的约 150 万个图像块(patches)上进行了深度训练 。
· 分类任务:模型被训练用于识别三类目标:前列腺腺体组织、非腺体组织和肿瘤组织 。
· 输入规格:图像块大小为 300 x 300 像素,在 20 倍物镜下约对应 150 x 150 um 的实际区域 。
· 性能基准:在理想(无伪影)条件下,该模型对前列腺癌检测的准确率超过 98%,F1 分数接近 1.0 。
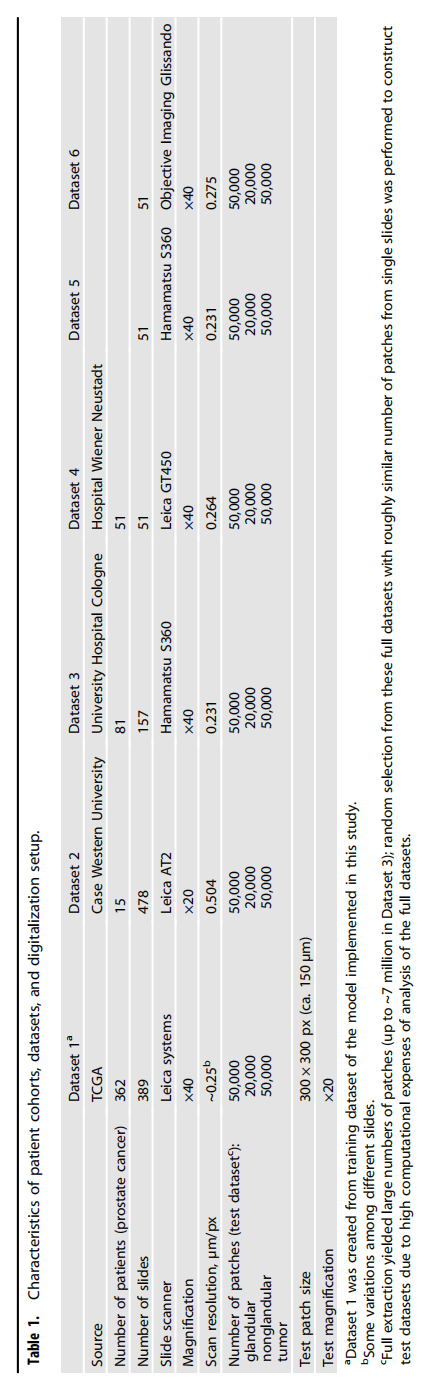
2.2. 6 大独立数据集
为了验证模型的通用性,研究者使用了来自 4 个不同机构 的 6 个独立数据集 (DS1-6) 。
· 设备多样性:这些数据集分别由 Leica、Hamamatsu、Philips 等 5 种不同品牌 的扫描仪生成 。
· 样本构成:每个测试集随机抽取了 120,000 个图像块,包括 50,000 个肿瘤块、50,000 个良性腺体块和 20,000 个非腺体组织块 。
· 入选标准:所有用于测试的图像块在“原始状态”下都必须能被模型 100% 正确分类,以便后续精准测量伪影带来的性能跌幅 。
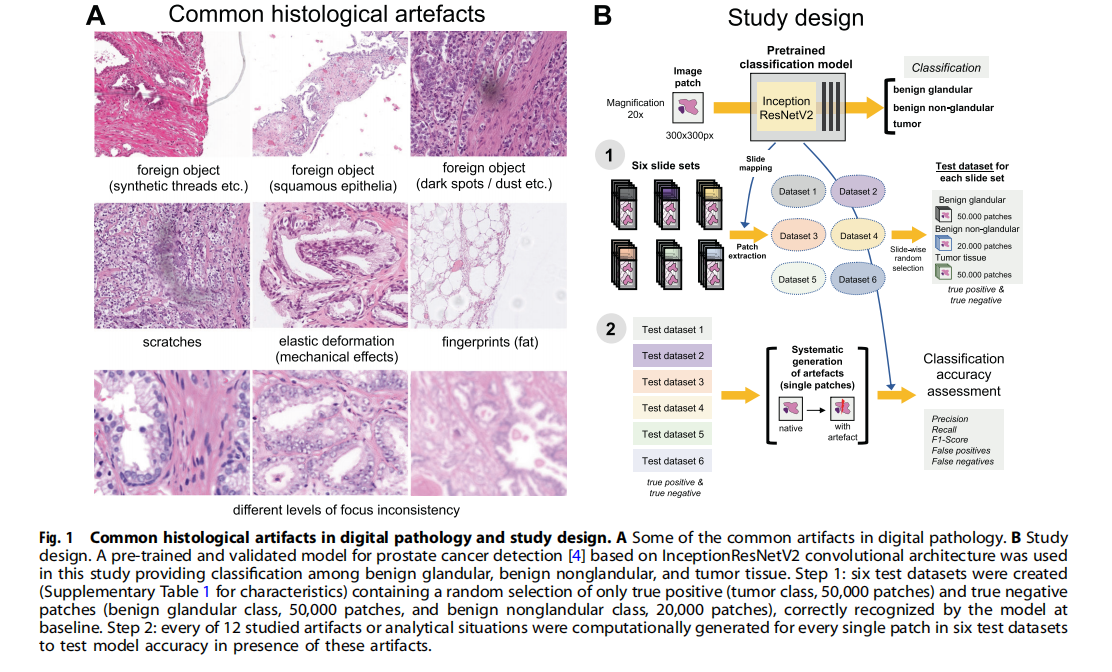
2.3. 12 种伪影的精准“投放”
这是本研究的核心:研究者通过算法在“完美图像”上精准模拟了 12 种干扰因素 。这些干扰可分为两大生成模式:
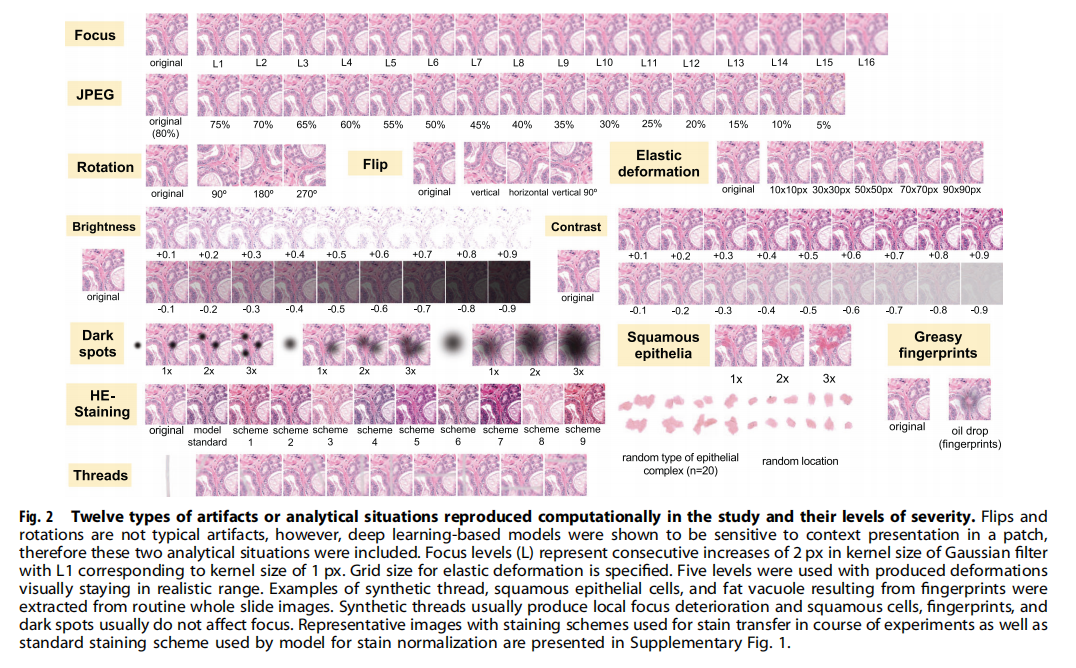
A. 像素级变换模拟 (Pixel-level change)
· 对焦模糊 (Focus):使用高斯模糊(Gaussian blur)模拟,共设 16 个严重等级,每级增加 2 像素的核大小 。
· JPEG 压缩:模拟存储过程中的损耗,测试范围从标准的 80% 一直压缩到极端的 5% 。
· 弹性变形 (Elastic deformation):模拟组织切片时物理挤压,使用五种不同网格大小(10px 到 90px)进行形变 。
B. 物理覆盖模拟 (Overlaying)
研究者从真实的病理切片中提取了这些异物的“素材”,然后将其叠加在干净的图像块上 :
· 黑点/灰尘 (Dark spots):提取了 3 种类型的杂质 。
· 合成纤维 (Threads):提取了 10 种不同位置和形状的线头 。
· 指纹油渍 (Fingerprints):模拟覆盖在组织表面的半透明脂肪滴 。
· 鳞状上皮污染 (Squamous epithelia):提取了 20 种可能来自实验员皮肤的细胞簇 。
2.4. 评估指标
研究者使用 F1-Score 作为核心评价指标 。由于初始 F1 分数被设定为 1.0,因此性能曲线的每一次下滑都真实反映了该伪影对 AI 诊断能力的破坏程度 。
此外,研究还通过 GradCAM(梯度加权类激活映射)技术来观察 AI 的“注意力” 。当伪影出现时,我们可以直观地看到 AI 的焦点是停留在了组织上,还是被杂质吸引走了 。
3. 结果(Results)
3.1 伪影对模型准确性的系统性影响

研究利用六个测试数据集(Dataset 1-6)对前列腺癌(PCA)检测模型进行了压力测试。所有受试伪影均导致了不同程度的模型准确率(F1-score)下降 。
· 聚焦与压缩 (Focus & JPEG): 聚焦失效(Focus)是影响最显著的因素之一。即使是病理学家认为可接受的轻微模糊(Level 1-2),也会导致假阴性率显著上升 。相比之下,模型对 JPEG 压缩表现出较强的鲁棒性,在压缩率高于 15% 时仍能保持 F1 > 0.95 。
· 物理干扰 (Physical Artifacts): * 合成纤维 (Threads): 在组织上覆盖合成纤维会导致 F1 分数从 1.0 骤降至 0.92 。
· 弹性形变 (Elastic Deformation): 模拟组织切片过程中的机械拉伸发现,形变程度(网格大小)与准确率损失成正比 。
· 污染因素: 覆盖鳞状上皮细胞(Squamous epithelia)和指纹油滴(Fingerprints)均会造成不可忽视的性能衰减,且损失程度随污染数量的增加而加剧 。
· 遮挡物 (Dark spots): 较大且透明度低的深色斑点(如 Type 3)对模型干扰最大 。
3.2 图像参数与染色异质性的挑战
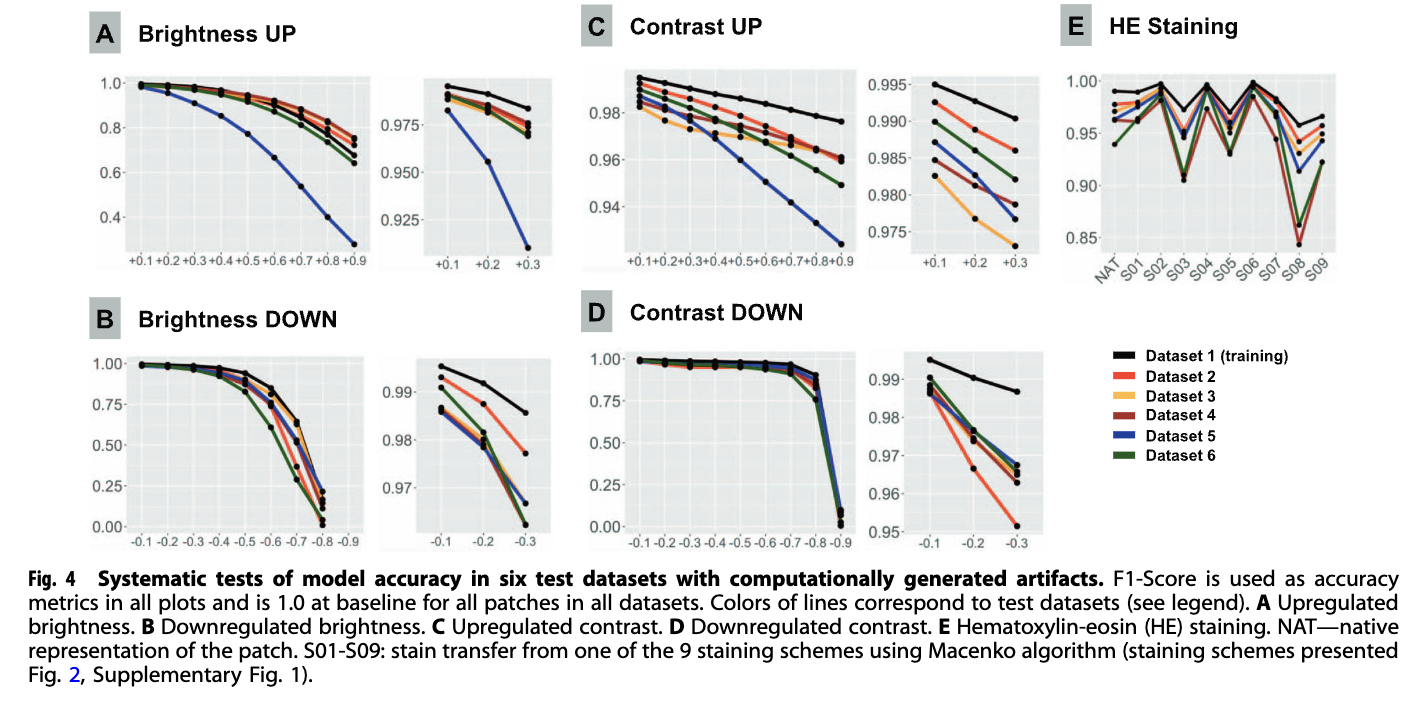
· 亮度与对比度 (Brightness & Contrast): 即使是 10% 的微小调节也会导致准确率下降 。研究特别发现,Dataset 5 在亮度上调时表现出异常剧烈的性能下滑,这归因于该数据集在扫描时已由操作员进行了人工视觉优化,而非标准出厂校准 。
· HE 染色异质性 (Staining): 使用 Macenko 算法进行染色归一化是保持性能的关键 。当直接测试未经处理的“原生”染色(Native)或被视觉判定为“差”的染色方案(如 S08)时,模型准确率会出现大幅度滑坡 。
3.3 误诊模式与空间分布分析
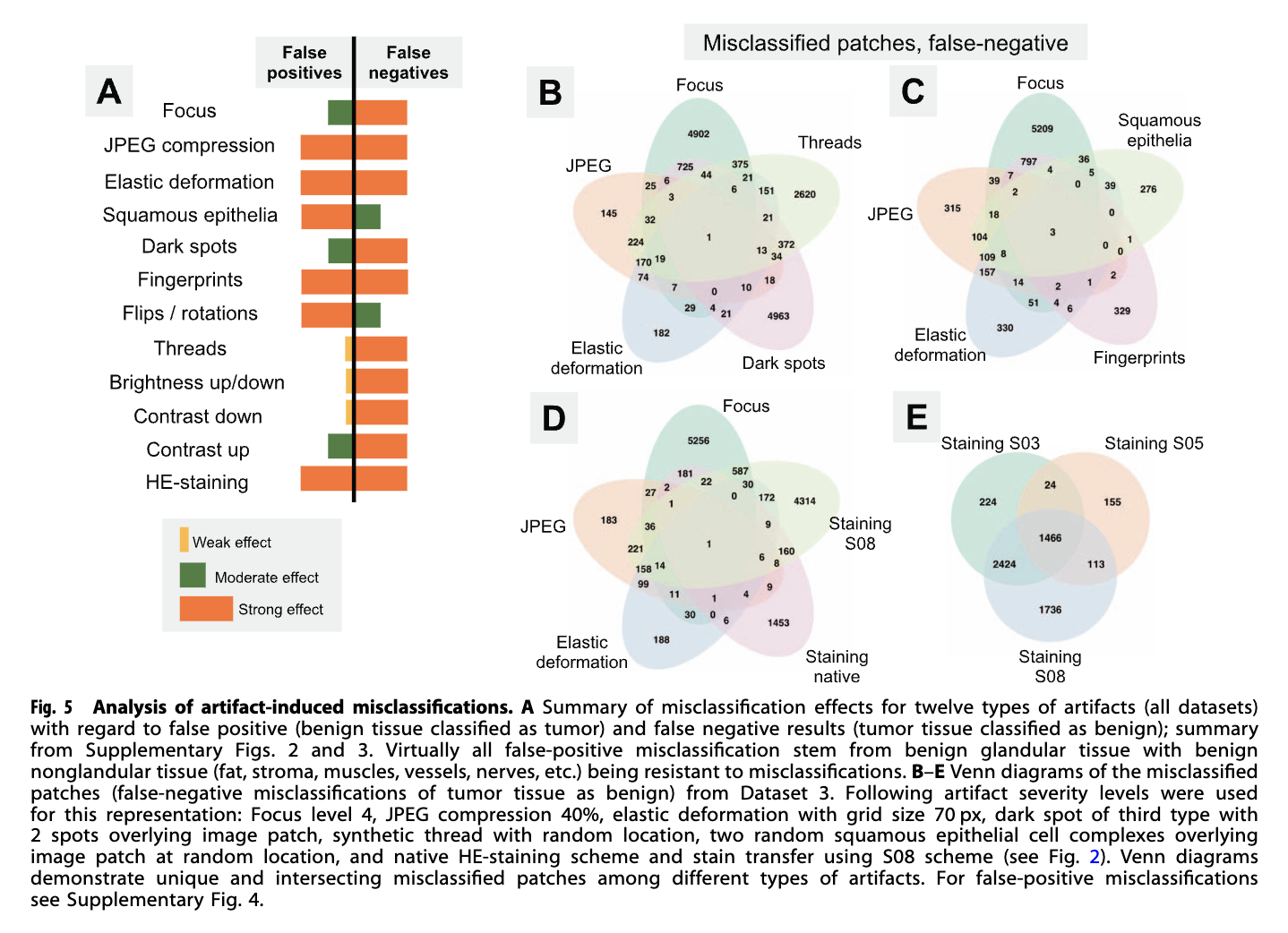
通过对误分类图块(Patches)的深入分析,揭示了模型失效的具体机制:
· 误差来源分布: 绝大多数假阳性(FP)误诊发生在“良性腺体组织”中,而“非腺体基质组织”(如脂肪、肌肉、神经)对伪影表现出极强的抵抗力,几乎不产生 FP 。
· 误诊重叠分析 (Venn Diagrams): Figure 5B-E 展示了不同伪影导致的误诊区域具有重叠性。产生全新内容(如纤维、上皮细胞)或大幅删除现有信息的伪影(如失焦)往往会产生更多独特的(Unique)误诊病例 。
· 数据相关性: 研究观察到,在弹性形变、对比度上调等场景下,来自同一中心但不同扫描仪的 Dataset 3-5 表现出比 Dataset 2 和 6 更高的误诊率 。形态学分析显示,这是因为 Dataset 3-5 的良性样本多取自肿瘤邻近区域,含有更多前列腺内上皮瘤(HGPIN)等具有类似肿瘤特征的病变,从而降低了误诊阈值 。
3.4 错误分类的补丁
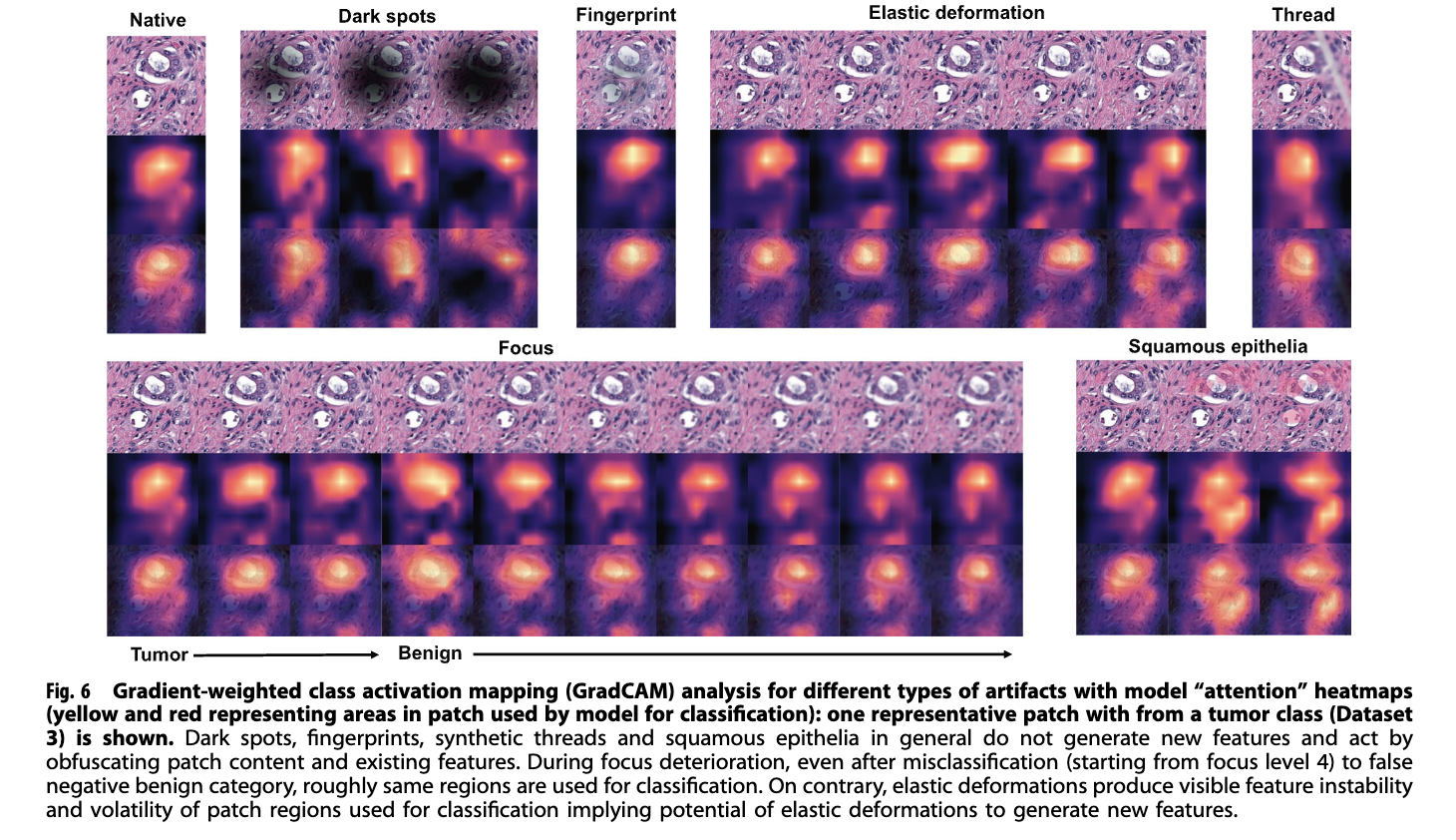
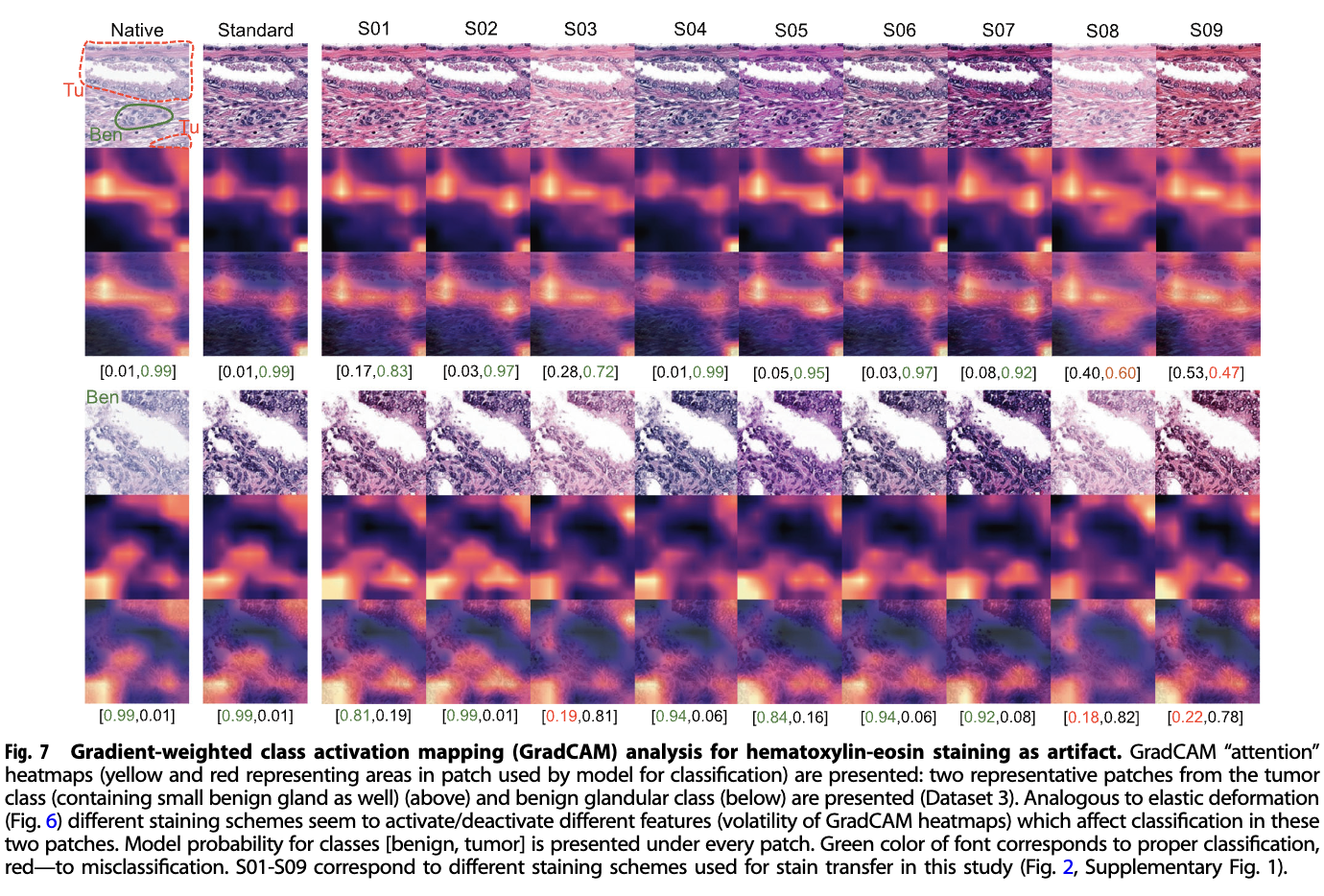

由于所有研究数据集在存在伪影时显示出相同的模型准确性行为模式,我们选择了一个具有代表性的数据集(数据集 3)进行错误分类补丁的详细调查。在该数据集中,不同伪影的错误分类补丁之间存在交集(图 5B–E)。那些随机作用并主要产生新内容的伪影(鳞状上皮细胞、线状、暗斑)或显著减少现有信息量(焦点、线状、暗斑)通常显示出更多独特的错误分类补丁(图 5B–E)。然而,基于 GradCAM 的类激活图分析显示,这些新内容并未用于分类(新特征),而是混淆了现有特征(见图 6)。然而,有些伪影似乎确实会改变斑块中的特征星座或特征突出度(弹性变形、高效染色;见图 6 和 7)。这一点得到了弹性变形产生最多假阳性结果的支持(补充图 4)。
焦点伪影可能是数字病理学中最重要的伪影。我们使用模型作为编码器(见方法)对焦点质量相关误分类斑块进行了相似性分析。后者采用 t-SNE 原则进行聚类,并由专家泌尿生殖病理学家(YT)分析以识别形态描述特征。假阴性肿瘤斑块形成的可识别簇(图 8A):(1)斑块肿瘤含量极低(单腺体或更少),(2)分化良好且具伪多增性特征的肿瘤或癌症。在伪阳性良性斑块中,出现多个簇(见图 8B):(1)炎症,(2)腺体腔含量,(3)肿瘤前期变化(HGPIN),以及(4)牵缩伪影(常见于肿瘤组织)。
4. 讨论(Discussion)
4.1 核心发现:伪影对准确性的普遍影响
· 性能下降:研究证实,所有测试的12种常见组织学伪影(如对焦模糊、亮度/对比度变化、染色差异、异物覆盖等)都会导致预训练的深度学习模型准确率下降 。
· 严重程度相关性:模型性能的损失与伪影的严重程度直接相关。即使是病理学家肉眼认为“可容忍”的微小变化(如轻微的焦距模糊或亮度偏差),也可能导致模型出现明显的误诊 。
4.2 误诊机制分析
通过GradCAM(梯度加权类激活映射)和t-SNE等技术,研究揭示了不同伪影导致模型失灵的两种主要机制:
· 特征掩盖(Obfuscation):像暗点、指纹和合成线头等伪影,本身并不产生新特征,而是通过遮盖图像中的关键形态学特征来干扰分类 。
· 特征改变(Feature Change):弹性形变和染色差异则会从本质上改变细胞和组织的形态表现,导致模型识别出的特征星座(Feature Constellation)发生偏移,从而产生更高的误报率(FP) 。
4.3 常见的敏感因素
· 对焦问题:被认为是数字病理中最关键的伪影。即使是轻微的失焦,也会使含有少量肿瘤或分化良好的癌组织被误判为良性 。
· 扫描仪差异:研究发现不同扫描仪自带的颜色和光影处理(即使经过标准化)仍会形成特定“集群”,影响模型的通用性 。
· 组织背景:位于肿瘤附近的良性区域(如含有HGPIN病变的区域)比完全正常的良性组织更容易受到伪影干扰而产生误报 。
4.4 应对策略与临床建议
讨论部分提出了防止模型在真实临床环境中失效的几项策略:
· 引入压力测试:在算法的临床验证阶段,应使用合成生成的伪影进行“压力测试”,以评估模型的边界条件 。
· 质量控制(QC)模型:开发专门用于识别和过滤低质量图像区域(如失焦或有严重伪影的切片)的辅助算法,在AI诊断前先行拦截 。
· 增强模型鲁棒性:在训练阶段通过“数据增强”(Data Augmentation)加入各种模拟伪影,使模型在学习阶段就学会忽略这些干扰因素 。
· 高级标准化技术:例如利用生成对抗网络(GAN)进行染色转移,相比传统的Macenko方法,GAN能更好地消除扫描仪特有的特征干扰 。
4.5 局限性与展望
研究者指出,虽然本研究通过数字化手段精确模拟了多种伪影,但真实世界中的伪影可能更加复杂且往往是多种类型叠加出现的。未来需要更多针对多重伪影叠加效应的研究,以进一步提升病理AI的临床可靠性。