
一、异常检测与监督学习的核心区别

一、带标签数据在异常检测中的评估作用
一、密度估计 图中说明了对多维特征向量进行密度估计的设定与公式。 训练集:{x(1),x(2),…,x(m)},每个样本 xi 有 n 个特征。右侧用列向量表示样本 xx由各维特征组成(x
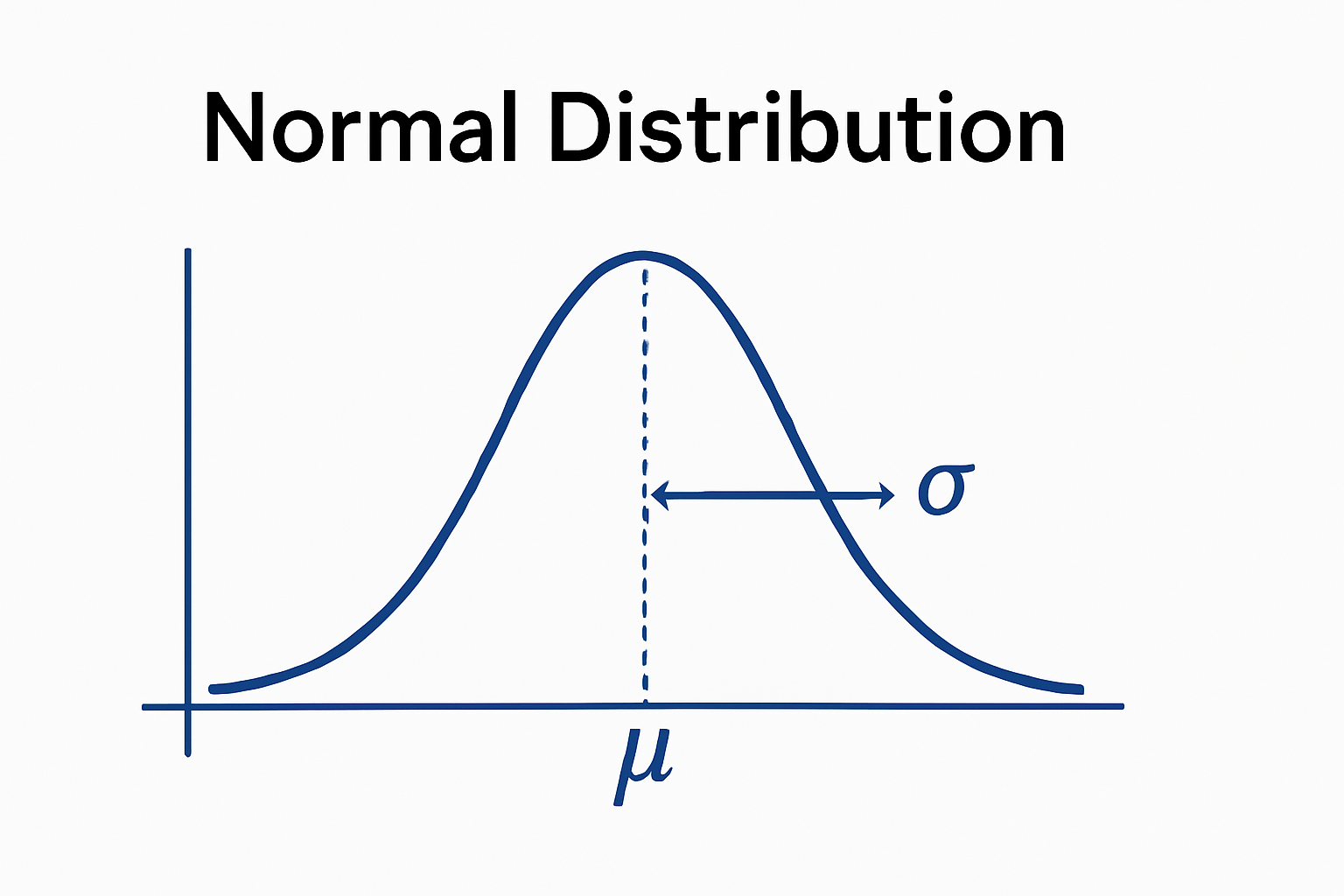
一、正态分布的定义 正态分布(Normal Distribution),又称高斯分布(Gaussian Distribution),是统计学和概率论中最经典、最重要的一种分布形式。它的曲线形状呈对称的钟形,中间高、两边低,且以均值为中心对称展开,数据大多集中在均值附近,越往两端越稀少。正态分布由均值
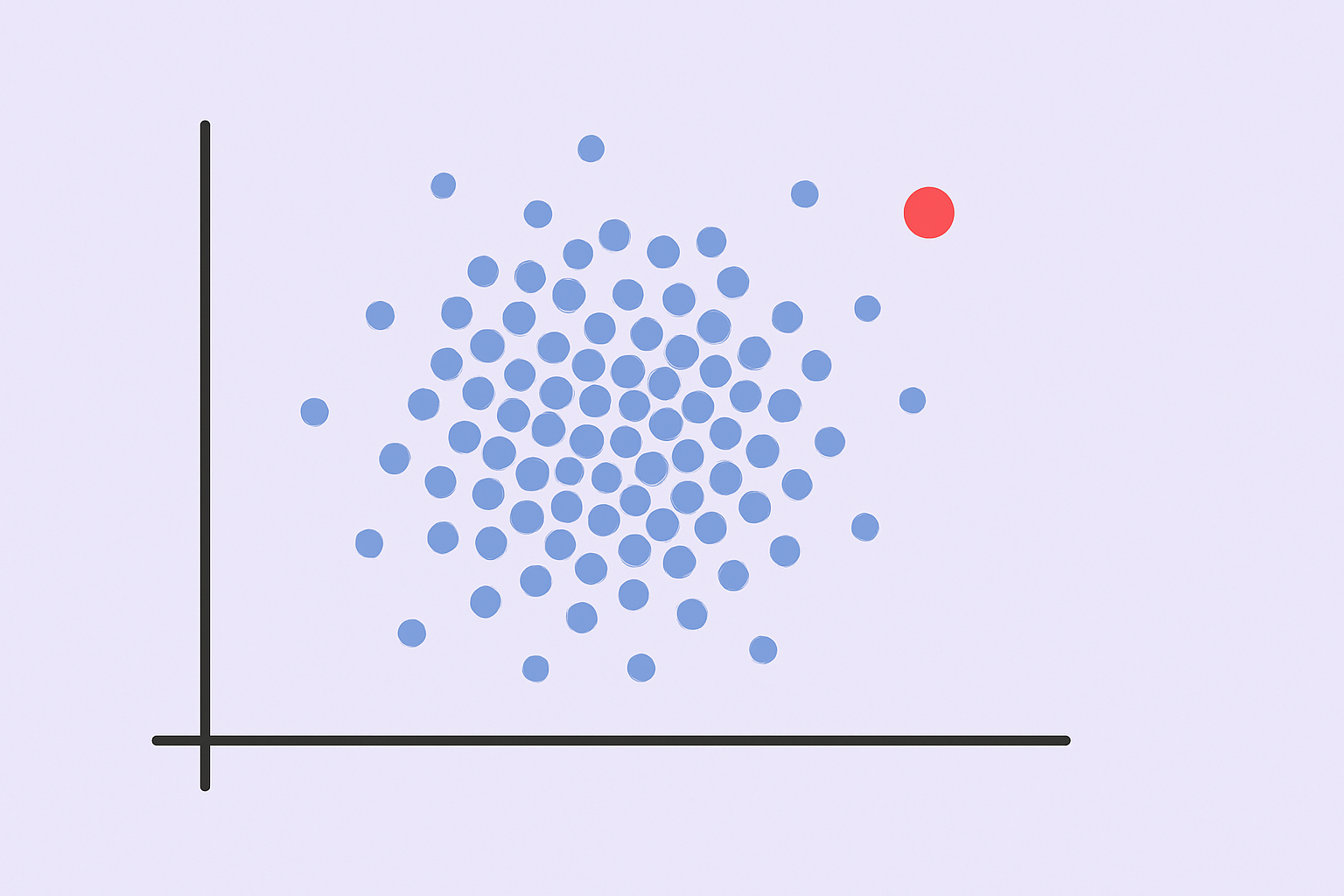
一、异常检测的定义 异常检测(Anomaly Detection)是一种数据分析技术,它通过分析数据集中的模式和行为,识别出那些与正常模式显著不同的观测值或事件。在实际应用中,它就像是一个敏锐的“守门人”,时刻监视着数据流,寻找那些“不按套路出牌”的数据点。 通俗理解:

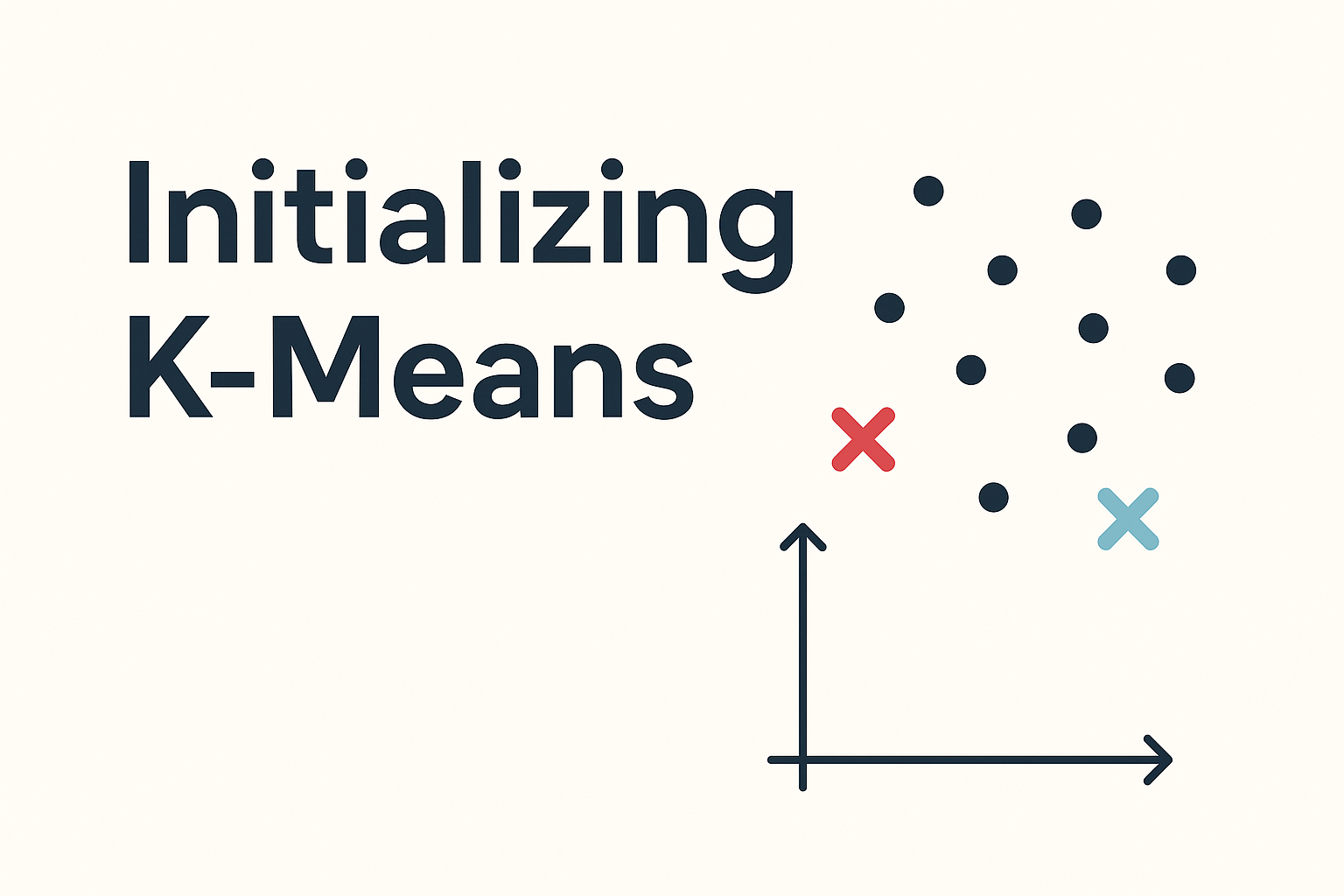
一、K-means 初始化的定义 K-means 的初始化是指在算法开始时,随机选择 KK 个数据点作为初始聚类中心。之后,算法会不断迭代,逐步调整这些中心的位置。

一、K-means 优化目标与代价函数 符号说明(图左) <

一、K-means算法的定义 K-means算法是一种经典的聚类算法,它通过将数据划分为K个簇来实现聚类目标。算法的核心思想是通过迭代优化簇中心的位置,使得簇内的数据点尽可能接近簇中心,而不同簇之间的数据点尽可能远离。 通俗理解: 就好像是在一个操场上把一群乱跑的小孩

一、聚类的定义 聚类是一种常见的数据分析方法,它通过将数据集中的对象分组,使同一组内的对象相似度高,而不同组之间的对象相似度低。 通俗理解: 就像把一堆不同颜色和形状的玩具进行分类,把红色的玩具放一堆,蓝色的玩具放一堆,形状相似的也归到一起,这样就可以更清晰地了解玩具的组成情况。<
