
一、引言 在数据挖掘与机器学习中,“属性(Attribute)”是描述数据对象的最小信息单元。无论是构建模型、分析数据分布,还是进行特征工程,所有步骤都离不开对属性类型的理解。一个模型是否能够正确地处理某些特征,很大程度上取决于我们是否正确识别了属性的类型。 在实际的数据集中,属性并不是单一形式出现

一、引言 在机器学习的广阔体系中,分类(Classification)与聚类(Clustering)是两种看似相似但本质不同的任务。二者都涉及对数据进行分组或划分,但在学习方式、目标与所需信息上存在根本差异。 分类是一种有监督学习(Supervised Learning)

一、引言 在数据挖掘与机器学习领域中,预测建模(Predictive Modeling) 是最核心的任务之一。它的目标是利用历史数据,建立数学模型,对未知或未来的结果进行预测。而在预测建模的范畴下,最常见的两类问题便是——回归(Regression)与分类(Classification)。

一、引言 数据挖掘(Data Mining)是现代数据分析的重要组成部分,它的核心目标是从大量数据中提取潜在的、有用的知识与规律。随着大数据与人工智能的发展,数据挖掘已成为企业决策、科学研究与社会治理的重要支撑技术。 从广义上看,数据挖掘是一种将数据转化为信息、再将信息转化为知识的过程。它不仅关注结

一、引言 在数据挖掘和机器学习中,衡量两个数据对象之间的“相似”或“不同”是非常重要的一步。无论是进行聚类分析、分类预测,还是构建推荐系统,我们都需要一种方法来量化数据之间的关系,也就是判断它们到底有多像或者多不像。这种量化方式,便是通过“相似性(Similarity)”和“不相似性(Dissimi
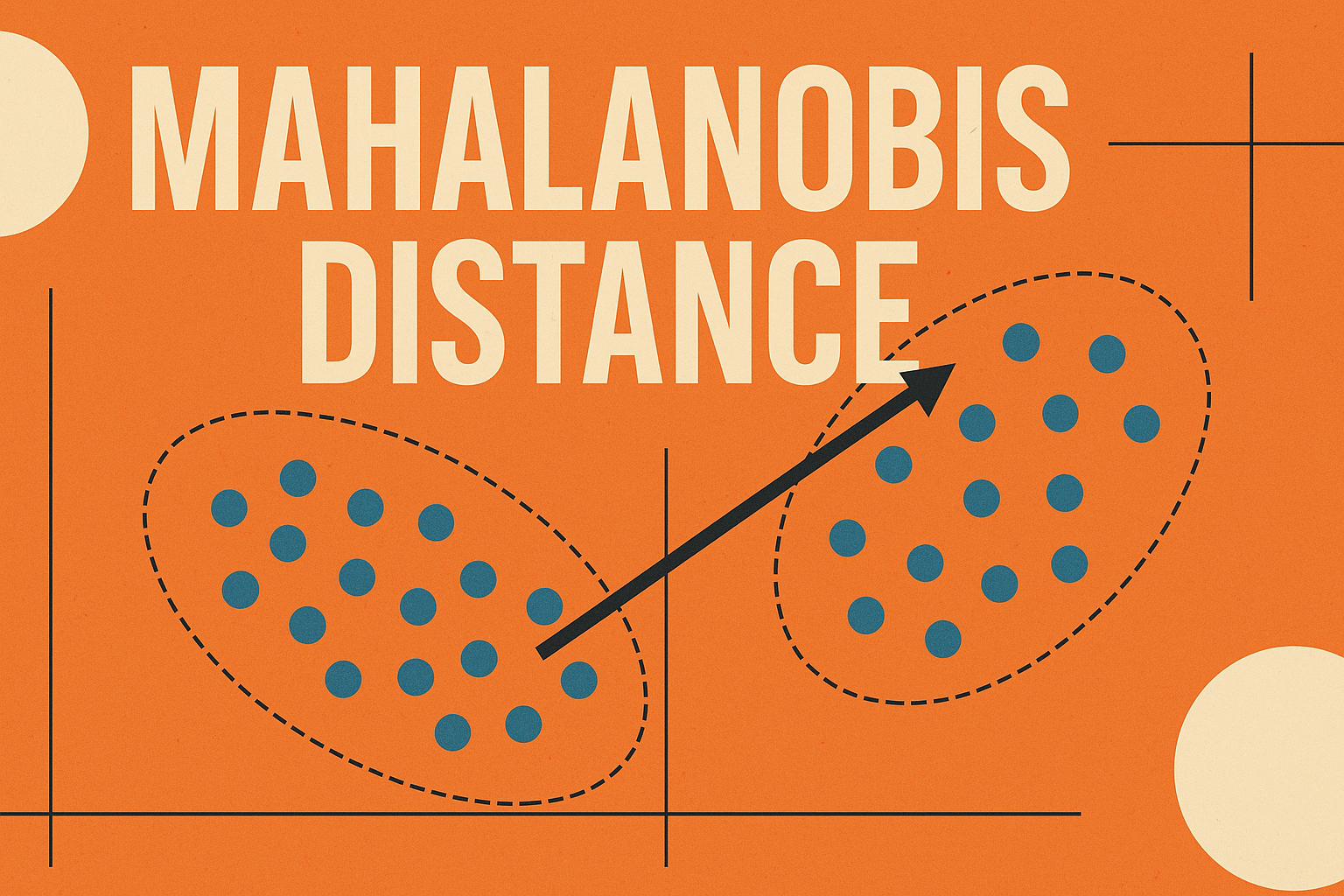
一、引言 在数据分析与机器学习中,“距离”是衡量样本之间相似度的核心概念。我们常见的欧氏距离(Euclidean Distance)与曼哈顿距离(Manhattan Distance),都基于坐标差值来计算样本间的空间距离。然而,它们都隐含着一个强假设——各个特征之间是相互独立的,并且在相同的度量尺
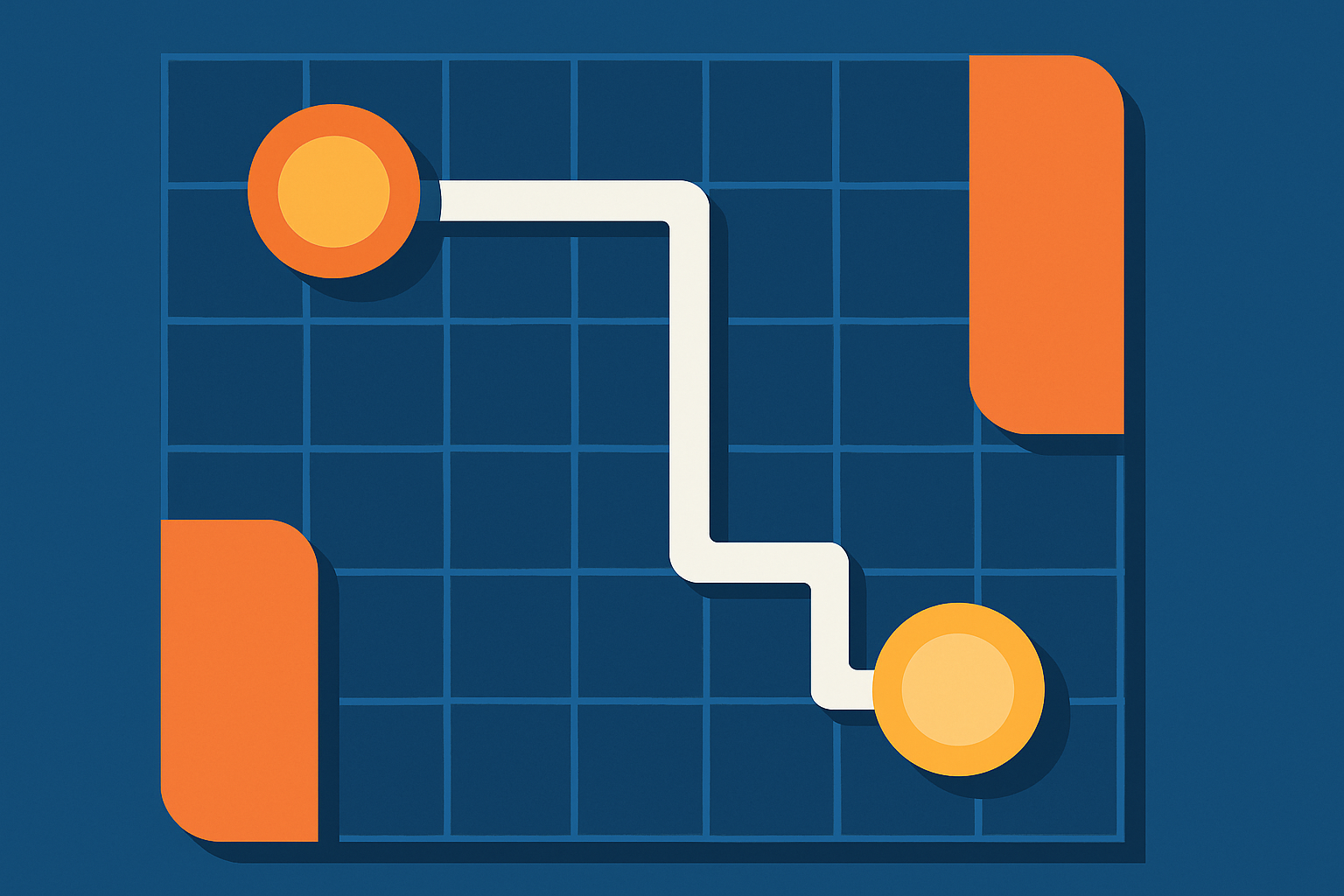
一、引言 在数据科学与机器学习的世界中,“距离”是一个极为核心的概念。无论是在聚类算法、相似度计算,还是在分类任务中,衡量两个样本之间的差异都离不开距离度量。而“Manhattan Distance(曼哈顿距离)”,便是其中最直观、最经典的一种。 曼哈顿距离(Manhattan Distance)又

一、引言 在数据分析和机器学习中,我们经常需要比较不同对象之间的相似性(similarity)。 对于数值型数据,可以使用欧氏距离(Euclidean Distance)或余弦相似度(Cosine Similarity)来衡量; 但当对象的属性仅由0和1组成时(即二元向量 Binary Vector

一、引言 在数据分析、机器学习和信息检索中,衡量“相似性”是一项基础而关键的任务。 不同的数据集、不同的特征空间,都需要一种合适的度量方式来判断对象之间的接近程度。最常见的做法是计算距离(Distance),例如欧氏距离或曼哈顿距离。然而,在许多实际场景中,我们更关心的是两个向量的方向是否一致

一、引言 在机器学习与数据挖掘中,“距离”是衡量两个对象相似度或差异性的重要指标。无论是在聚类(clustering)、最近邻搜索(nearest neighbor search)还是分类任务(classification)中,如何定义“距离”都会直接影响模型的效果。 最常见的距离度量是欧氏距离(E
