

一、熵的直观理解与基本概念 1.1 什么是熵? 在信息论中,熵(Entropy)用来衡量一个随机变量的不确定性大小。简单理解: 一个系统越“混乱”、越难预测,它的熵就越大; 一个系统越“有序”、结果越确定,它的熵就越小。 比如: 如果抛一枚均匀的硬币,正反两面出现的概率各是 0.5,这时结果很难预测
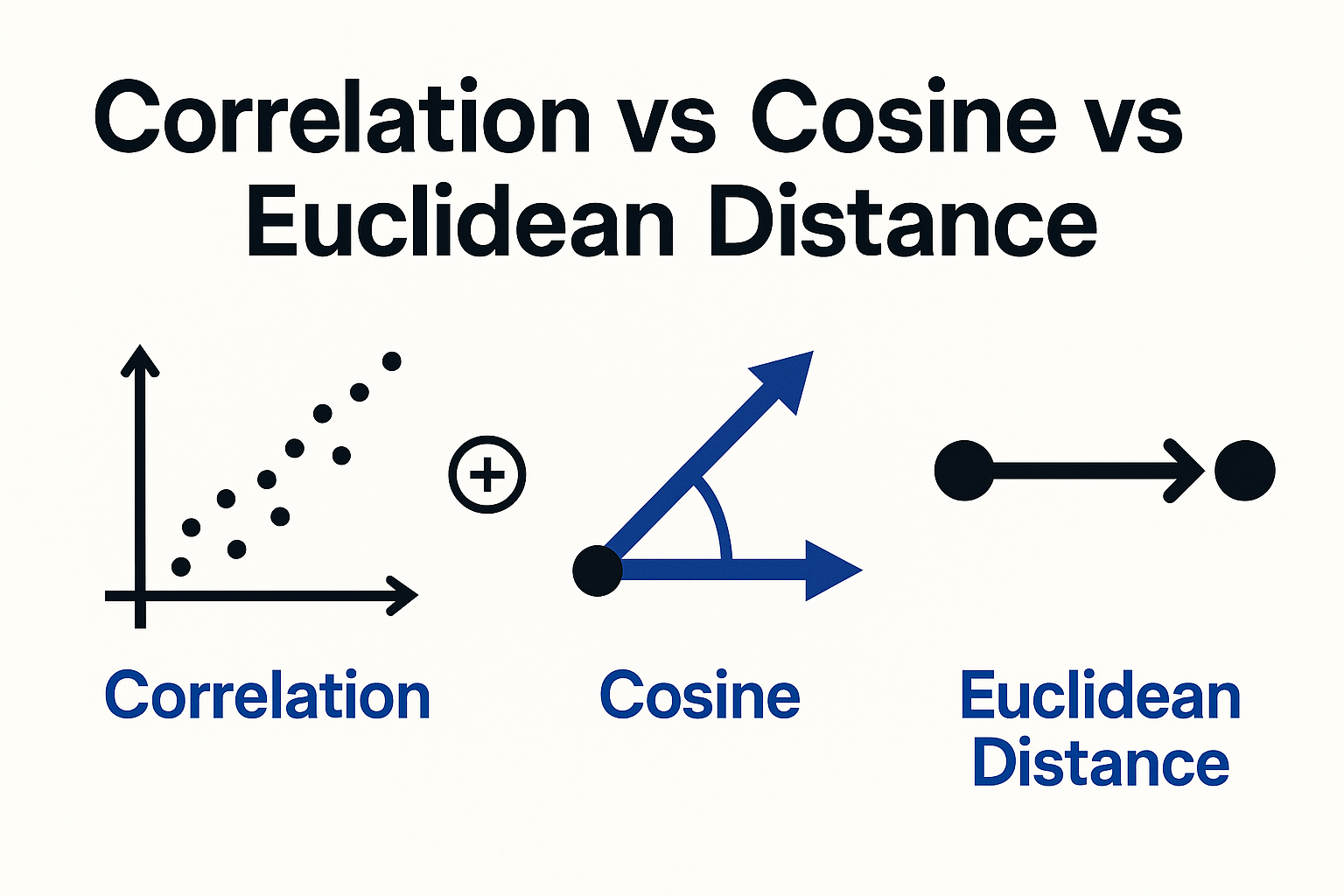
一、引言 在数据分析、机器学习和信息检索中,“相似度(similarity)”与“距离(distance)”是帮助我们理解对象之间关系的核心概念。无论是比较两篇文档的相似程度、判断两个时间序列是否具有相同趋势,还是评估样本之间的差异,不同的相似度度量方法往往会得出完全不同的结论。 在众多方法中,Pe
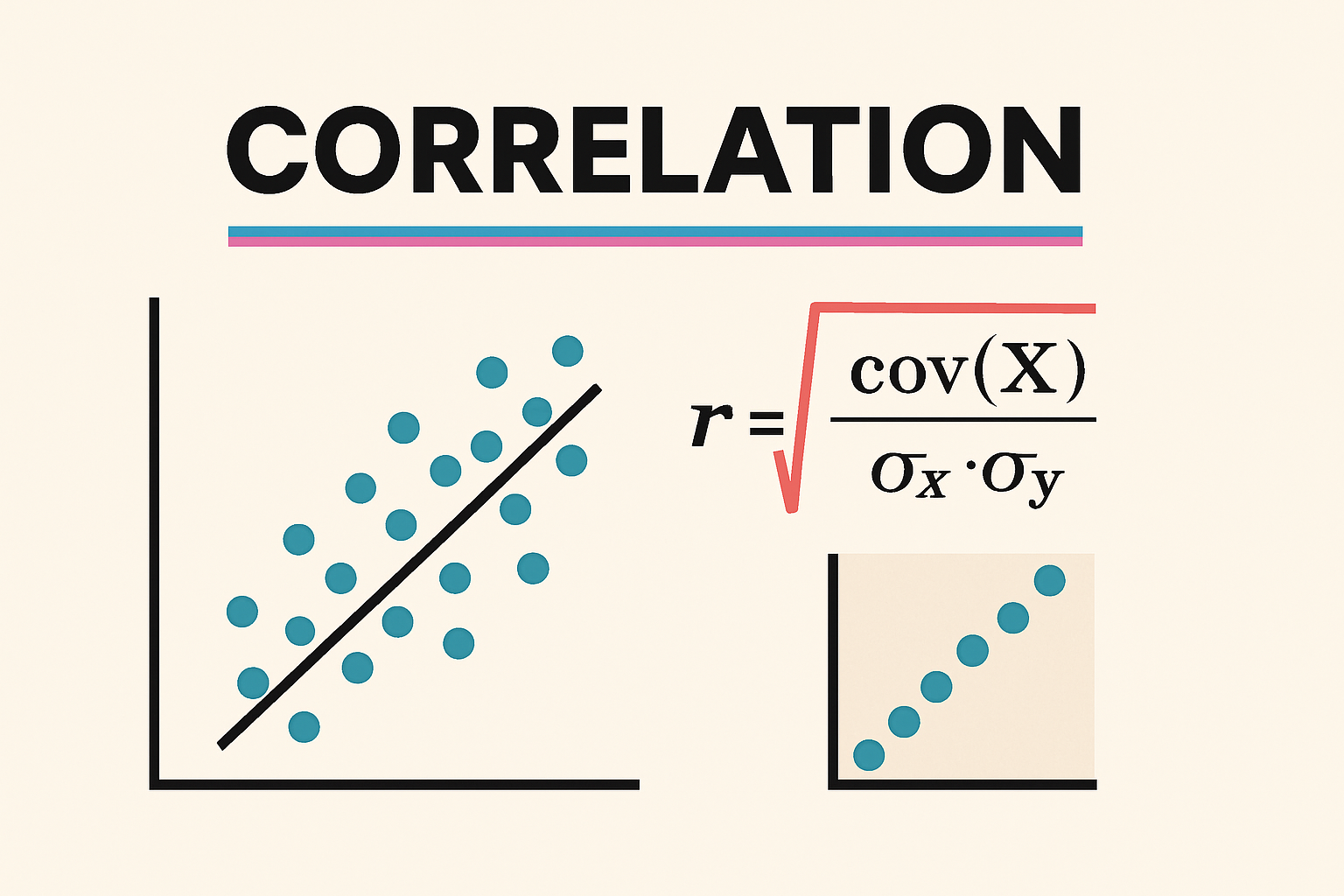
一、引言 相关性(Correlation)是数据挖掘和统计分析中最核心的概念之一,它描述了两个或多个变量之间的统计关系。在数据分析过程中,我们经常希望了解数据中的变量是否会同时变化、是否存在某种趋势上的关联,这些信息常常决定后续的建模方向和判断依据。 相关性的重要性体现在,它帮助我们理解数据结

一、引言 数据在现代分析、机器学习以及商业智能中扮演着核心角色。为了从数据中提取价值,我们不仅需要算法和工具,更需要理解数据本身的结构与形式。不同类型的数据集拥有不同的组织方式、特点和适用场景,因此在处理之前明确数据的类别是一项非常重要的前置步骤。 在数据挖掘与数据分析中,学者们通常会将数据集划分为
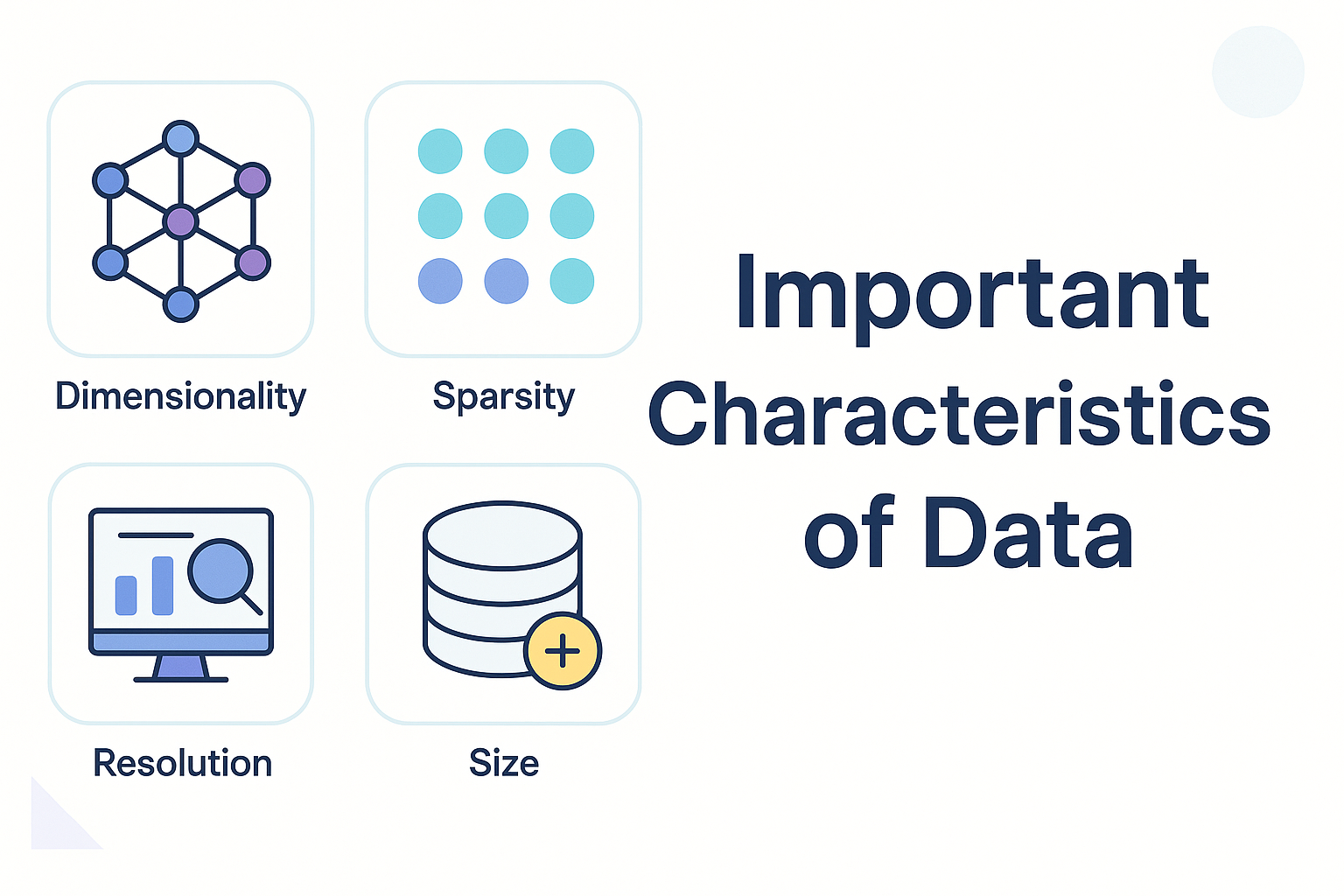
一、引言 在数据挖掘与机器学习中,我们经常强调“了解数据比使用模型更重要”。原因很简单:模型的表现往往不是由算法本身决定的,而是由数据的特征决定的。如果我们不了解数据的维度、稀疏性、分辨率以及规模,就无法正确选择分析方法,也无法判断模型是否能在这些数据上有效工作。 为了帮助你建立对“数据特征”的整体

一、引言 在数据挖掘与机器学习中,“属性(Attribute)”是描述数据对象的最小信息单元。无论是构建模型、分析数据分布,还是进行特征工程,所有步骤都离不开对属性类型的理解。一个模型是否能够正确地处理某些特征,很大程度上取决于我们是否正确识别了属性的类型。 在实际的数据集中,属性并不是单一形式出现

一、引言 在机器学习的广阔体系中,分类(Classification)与聚类(Clustering)是两种看似相似但本质不同的任务。二者都涉及对数据进行分组或划分,但在学习方式、目标与所需信息上存在根本差异。 分类是一种有监督学习(Supervised Learning)

一、引言 在数据挖掘与机器学习领域中,预测建模(Predictive Modeling) 是最核心的任务之一。它的目标是利用历史数据,建立数学模型,对未知或未来的结果进行预测。而在预测建模的范畴下,最常见的两类问题便是——回归(Regression)与分类(Classification)。

一、引言 数据挖掘(Data Mining)是现代数据分析的重要组成部分,它的核心目标是从大量数据中提取潜在的、有用的知识与规律。随着大数据与人工智能的发展,数据挖掘已成为企业决策、科学研究与社会治理的重要支撑技术。 从广义上看,数据挖掘是一种将数据转化为信息、再将信息转化为知识的过程。它不仅关注结
