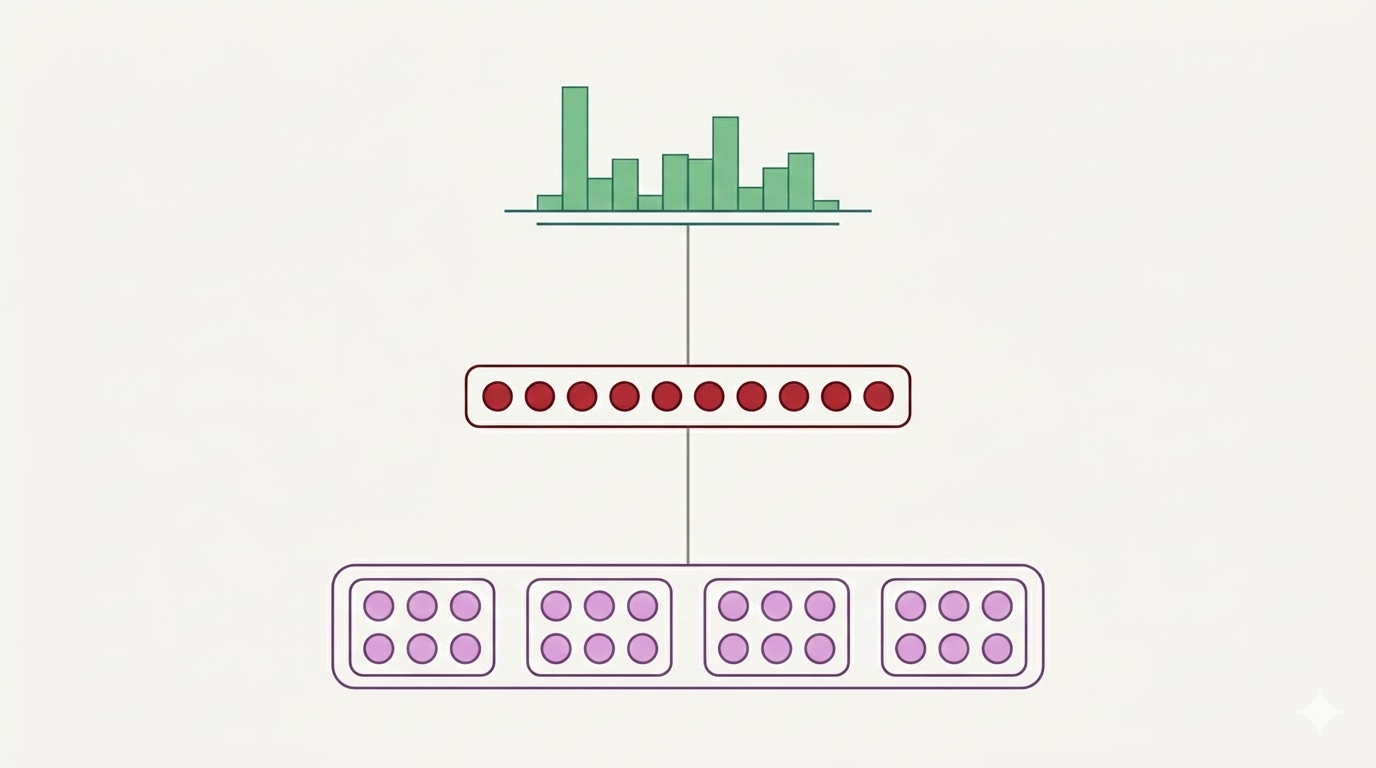
第一节:语言模型任务回顾 在深入研究复杂的神经网络架构之前,我们首先需要明确:什么是语言模型(Language Modeling)? 简单来说,语言模型的目标是预测序列中下一个出现的词。假设我们已经有了一个单词序列 x(1), x(2), ... , x(t),模型的核心任务就是计算在给定这些已知词
第一节:什么是语言模型? 在自然语言处理(NLP)的广阔领域中,语言模型(Language Modeling) 是最基础且最重要的核心任务之一。简单来说,它的目标是让计算机能够理解和生成人类的语言序列。 1. 核心任务:预测下一个词 语言模型的核心任务非常直观:给定一段已经出现的词序列,预测下一个可

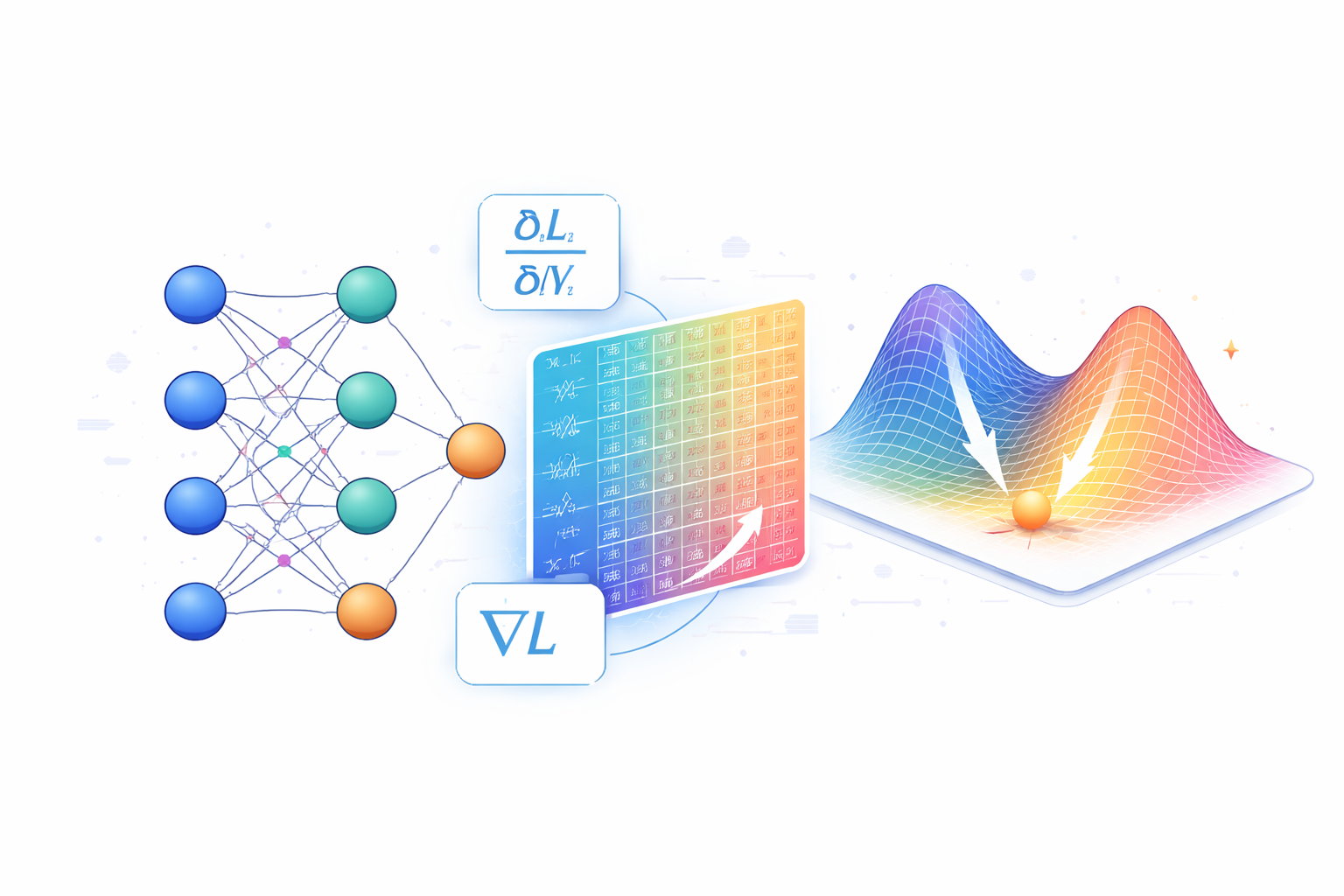
第一节:绪论——优化算法在神经网络训练中的核心地位 在深度学习的范畴内,模型训练的本质是一个在大规模参数空间内寻找最优解的非凸优化问题。优化器(Optimizer)作为连接模型架构与数据特征的桥梁,其核心任务是通过计算损失函数 L 对模型参数 θ 的梯度,利用特定的更新规则使目标函数最小化。
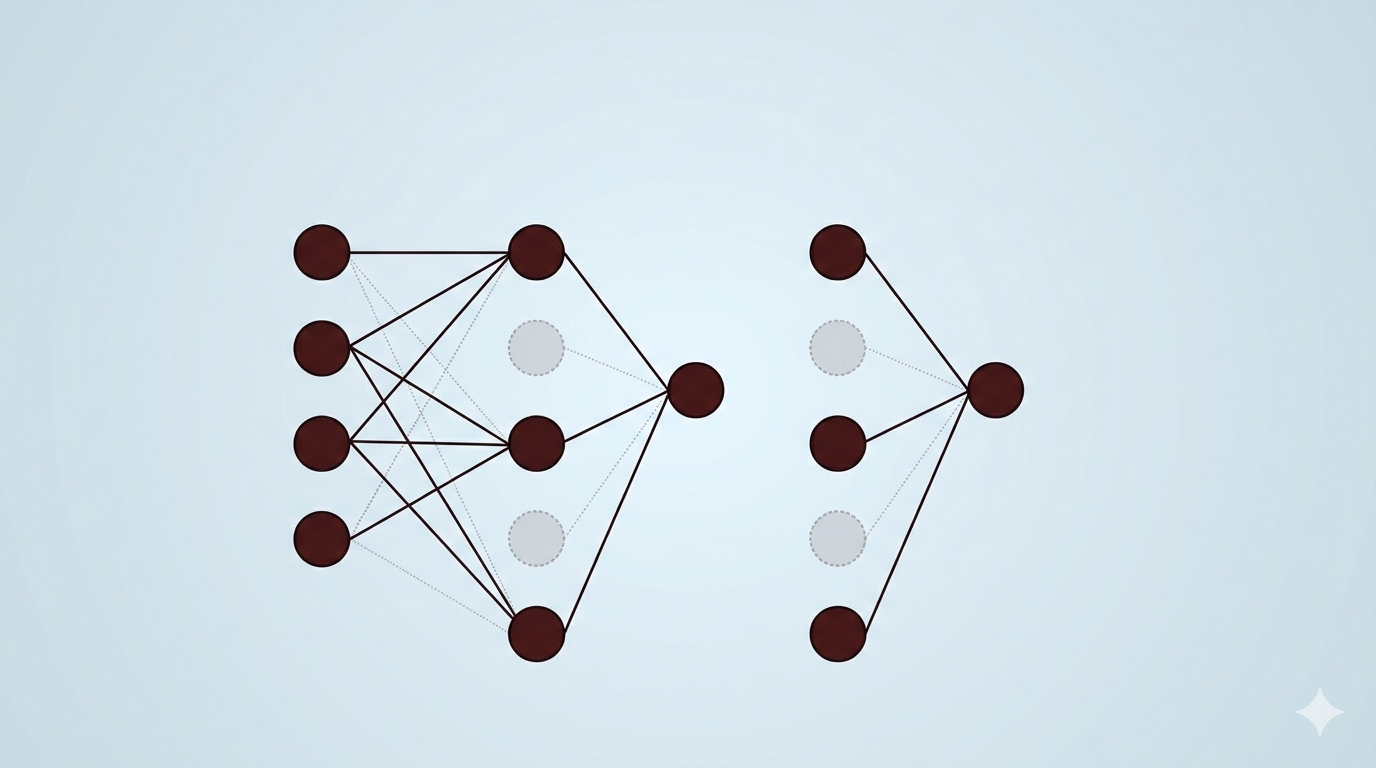
一、 引言:深度神经网络中的过拟合风险与正则化策略 在深度学习领域,模型的泛化能力(Generalization Ability)是衡量算法优劣的核心指标。随着网络深度的增加和参数量(Capacity)的指数级增长,深度神经网络展现出了极强的函数拟合能力。然而,这种强大的表达能力往往是一把双刃剑:当
第一节:句式结构的两种视野 在自然语言处理中,理解一个句子不仅仅是识别每个词的意思,更重要的是理解这些词是如何组合在一起表达完整语义的。目前主流的句法分析主要有两种视角:成分句法分析和依存句法分析。 1. 成分句法分析 (Constituency Parsing) 成分句法分析又被称为短语结构语法(
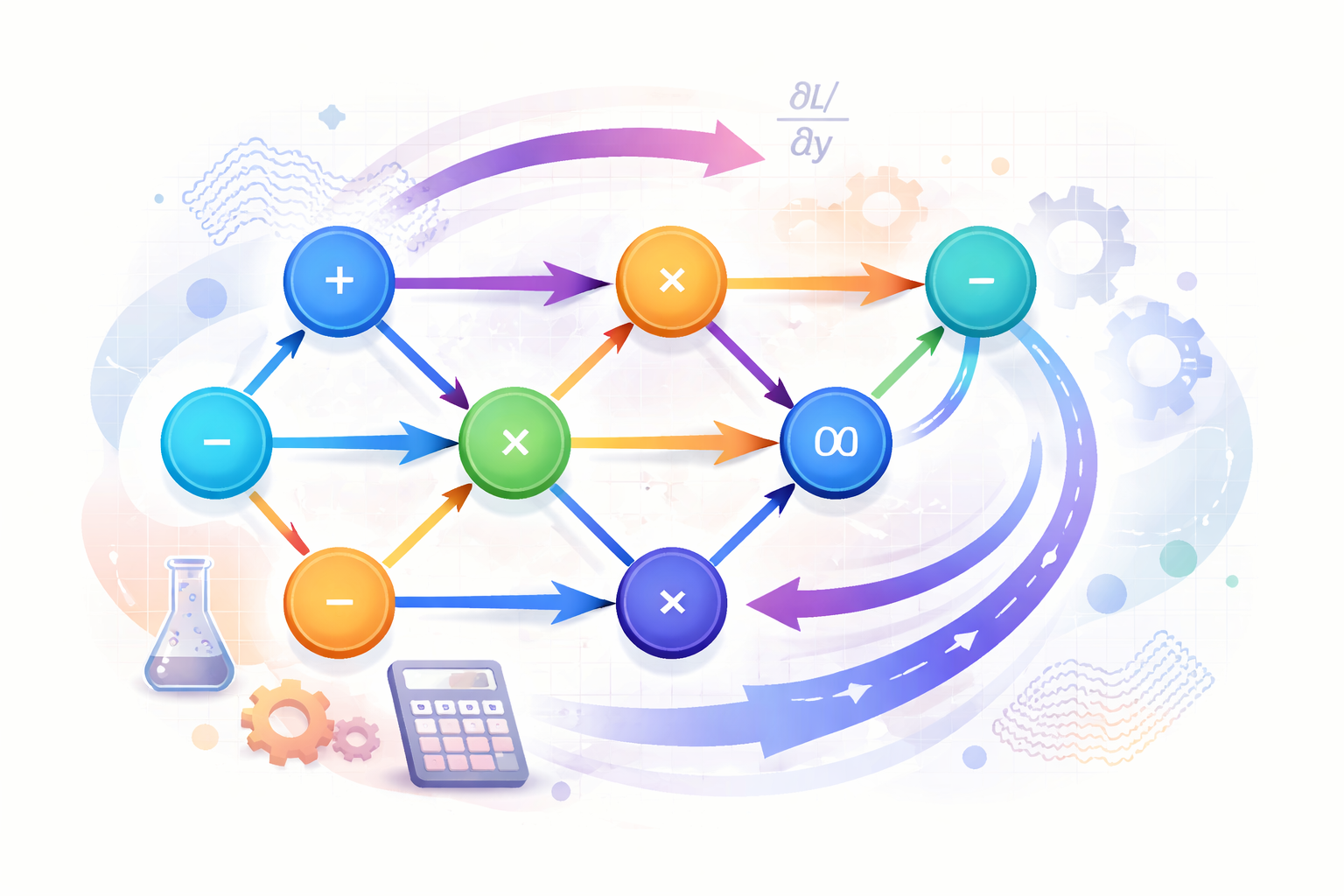
第一节:计算图定义 在深度学习中,软件并不是直接处理一长串复杂的数学公式,而是将神经网络的方程式表示为一张“图”。这种表达方式不仅让复杂的运算变得直观,更是自动求导技术的基础。 1. 什么是计算图? 计算图(Computation Graph)是数学表达式的一种图形化表示。在这种结构中: 源节点(S
第一节:从并行逻辑回归到神经网络 1. 神经网络的本质 很多人初学神经网络时会觉得它是一个复杂的“黑箱”,但从数学视角来看,神经网络并不是某种全新的魔法。本质上,一个神经网络可以看作是同时运行的多个逻辑回归。 当我们审视一个简单的单层结构时,它执行的操作与逻辑回归高度相似:对输入特征进行加权求和,然

一、引言 在数据挖掘与机器学习中,“属性(Attribute)”是描述数据对象的最小信息单元。无论是构建模型、分析数据分布,还是进行特征工程,所有步骤都离不开对属性类型的理解。一个模型是否能够正确地处理某些特征,很大程度上取决于我们是否正确识别了属性的类型。 在实际的数据集中,属性并不是单一形式出现

一、引言 在机器学习的广阔体系中,分类(Classification)与聚类(Clustering)是两种看似相似但本质不同的任务。二者都涉及对数据进行分组或划分,但在学习方式、目标与所需信息上存在根本差异。 分类是一种有监督学习(Supervised Learning)

一、引言 在数据挖掘与机器学习领域中,预测建模(Predictive Modeling) 是最核心的任务之一。它的目标是利用历史数据,建立数学模型,对未知或未来的结果进行预测。而在预测建模的范畴下,最常见的两类问题便是——回归(Regression)与分类(Classification)。
