
该论文发表在 CIKM 2025 (第 34 届 ACM 信息与知识管理国际会议,The 34th ACM International Conference on Information and Knowledge Management)。
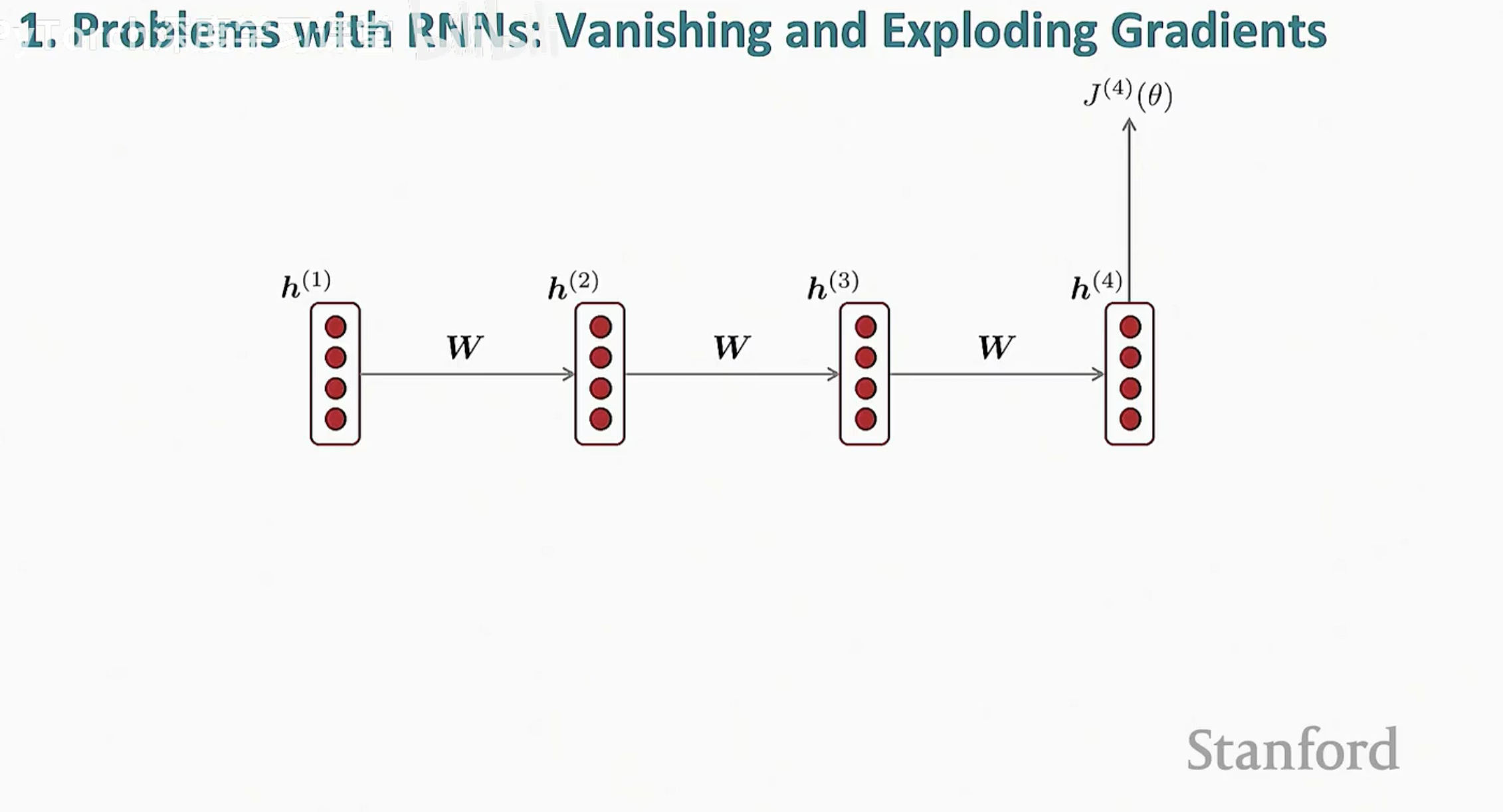
第一节:引言 在深度学习的序列建模中,循环神经网络(RNN)曾被寄予厚望。由于其循环连接的结构,理论上 RNN 能够保留无限长的历史信息。然而在实际训练中,你会发现它表现得非常“短视”——它能轻易记住上一个单词,却总是忘记上一个段落。 这种局限性的核心原因,在于反向传播(Backpropagatio
第一节: 什么是语言模型? (Language Model Recap) 在深入探讨如何评价一个模型之前,我们首先需要明确:我们要评价的对象究竟是什么? 1.1 核心定义:预测未来 从本质上讲,语言模型 (Language Model, LM) 是一个极其简单的系统:它只做一件事——预测下一个词 (
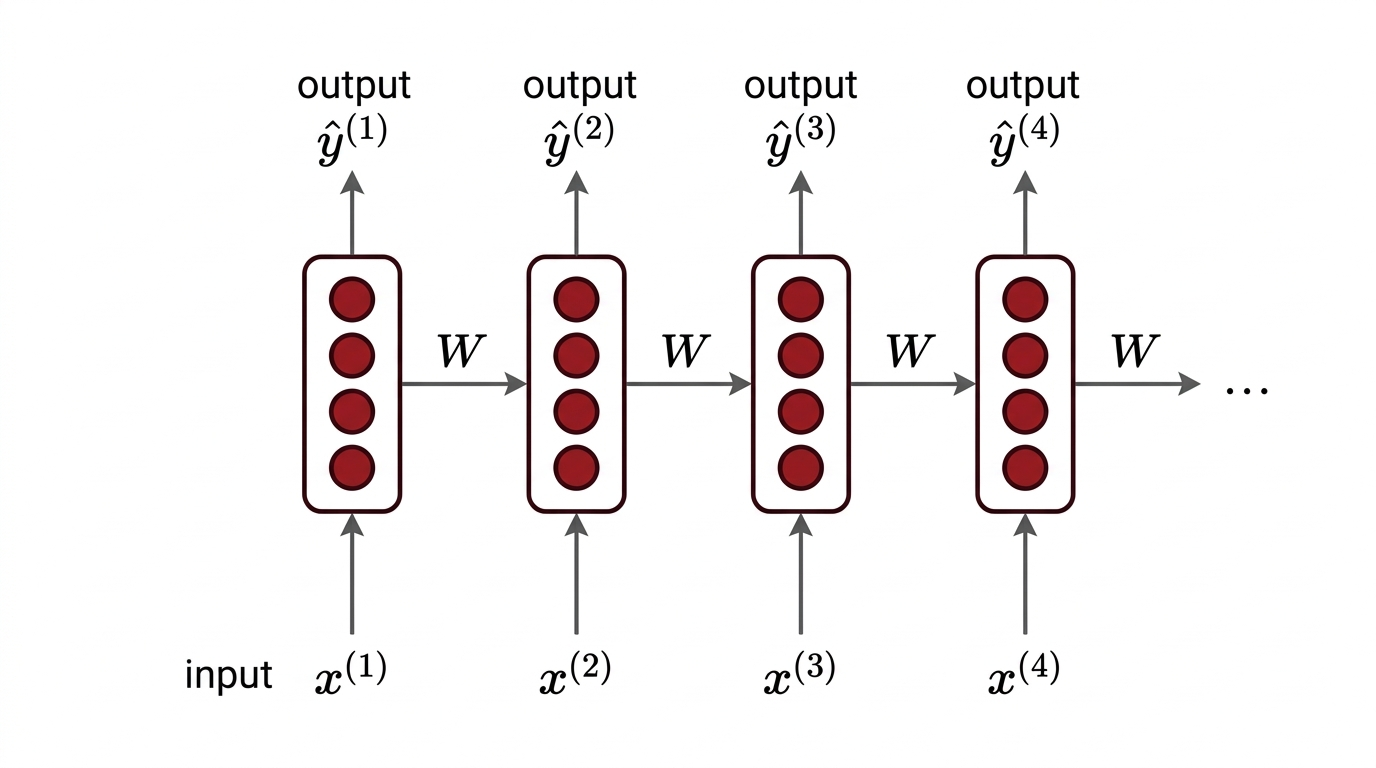
第一节:RNN 的核心架构 1.1 为什么我们需要 RNN? 在处理图像识别或简单分类任务时,传统的全连接神经网络(DNN)和卷积神经网络(CNN)表现卓越。但在处理序列数据(如自然语言、语音、股票走势)时,它们会面临两个致命的缺陷: 输入长度固定:传统模型要求输入向量的维度必须预先设定,但现实中的
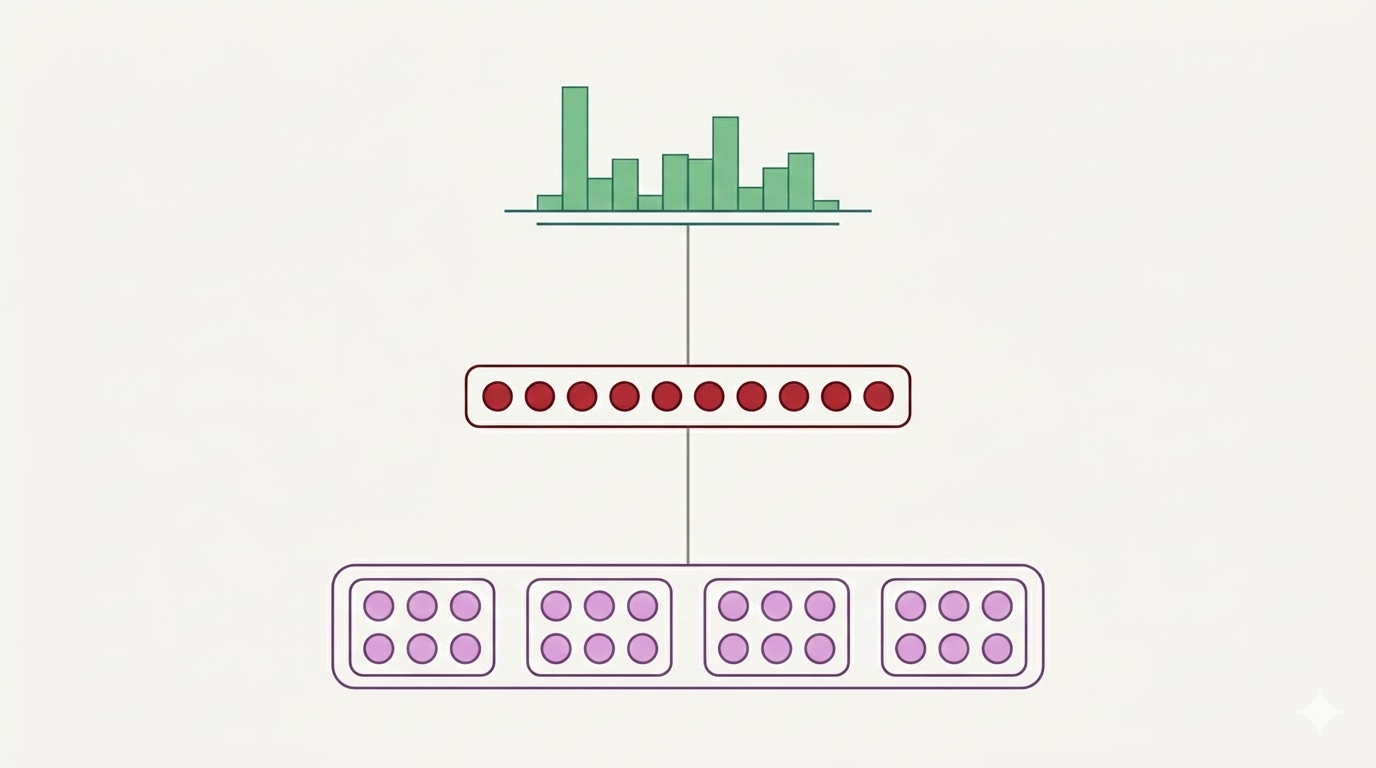
第一节:语言模型任务回顾 在深入研究复杂的神经网络架构之前,我们首先需要明确:什么是语言模型(Language Modeling)? 简单来说,语言模型的目标是预测序列中下一个出现的词。假设我们已经有了一个单词序列 x(1), x(2), ... , x(t),模型的核心任务就是计算在给定这些已知词
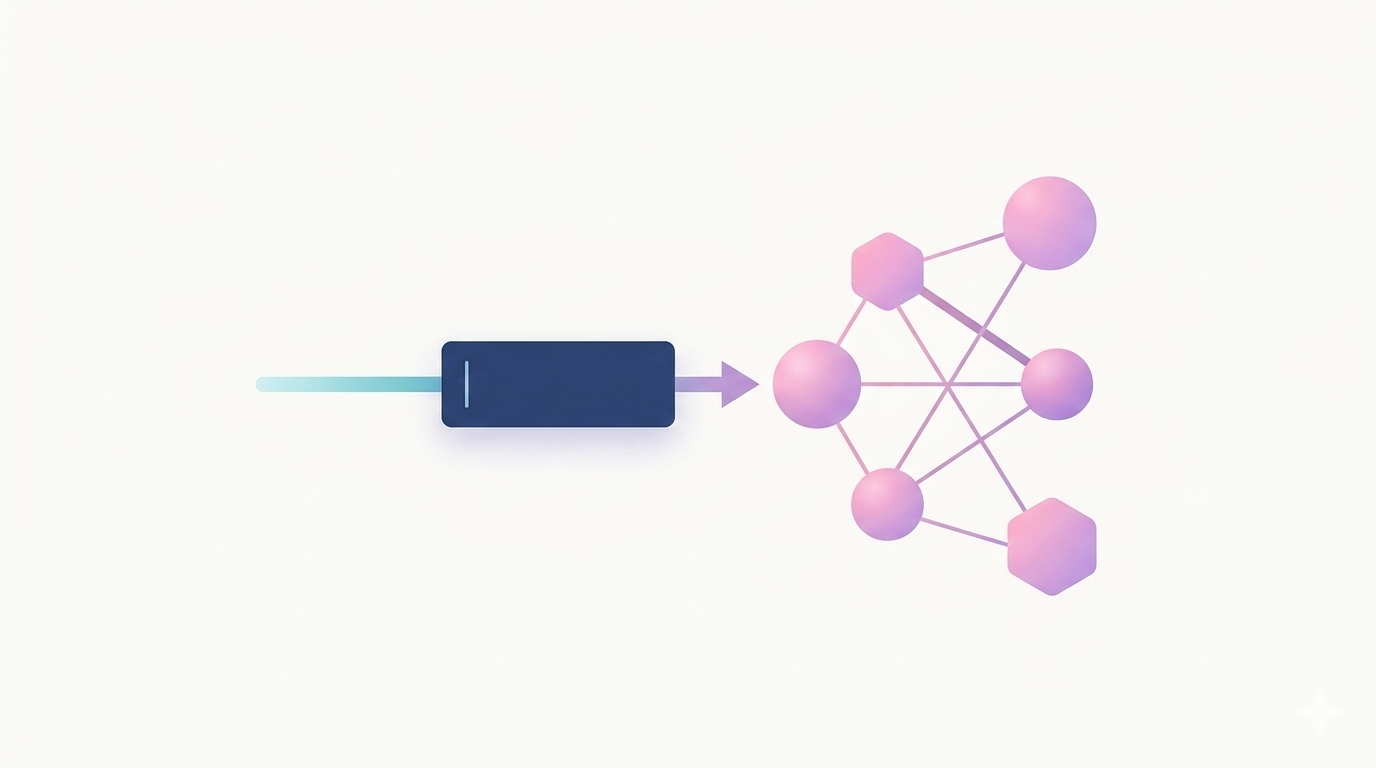
第一节:什么是语言模型? 在自然语言处理(NLP)的广阔领域中,语言模型(Language Modeling) 是最基础且最重要的核心任务之一。简单来说,它的目标是让计算机能够理解和生成人类的语言序列。 1. 核心任务:预测下一个词 语言模型的核心任务非常直观:给定一段已经出现的词序列,预测下一个可

第一节:绪论——优化算法在神经网络训练中的核心地位 在深度学习的范畴内,模型训练的本质是一个在大规模参数空间内寻找最优解的非凸优化问题。优化器(Optimizer)作为连接模型架构与数据特征的桥梁,其核心任务是通过计算损失函数 L 对模型参数 θ 的梯度,利用特定的更新规则使目标函数最小化。
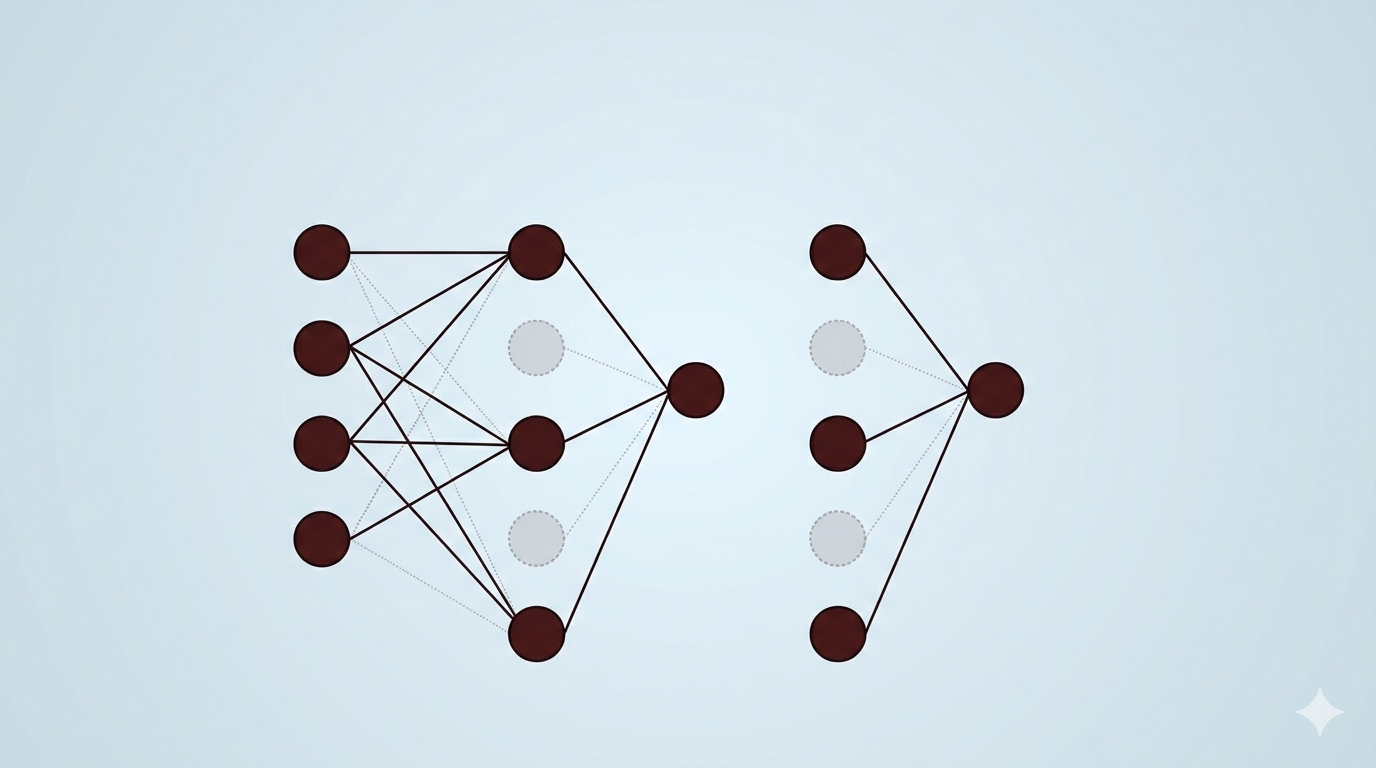
一、 引言:深度神经网络中的过拟合风险与正则化策略 在深度学习领域,模型的泛化能力(Generalization Ability)是衡量算法优劣的核心指标。随着网络深度的增加和参数量(Capacity)的指数级增长,深度神经网络展现出了极强的函数拟合能力。然而,这种强大的表达能力往往是一把双刃剑:当

1. 介绍(Introduction) 在医疗科技飞速发展的今天,数字病理学正迎来它的“高光时刻”。通过深度学习模型(Deep Learning),计算机能够以惊人的速度在成千上万张病理切片中捕捉到前列腺癌等疾病的蛛丝马迹。在理想的实验室环境下,这些算法的准确率往往能超过 98%,表现得像一位经验老

1. 介绍(Introduction) 1. 病理学的数字化转型 在过去的数年里,病理学领域正经历着一场深刻的变革
