
一、引言 在数据挖掘和机器学习中,衡量两个数据对象之间的“相似”或“不同”是非常重要的一步。无论是进行聚类分析、分类预测,还是构建推荐系统,我们都需要一种方法来量化数据之间的关系,也就是判断它们到底有多像或者多不像。这种量化方式,便是通过“相似性(Similarity)”和“不相似性(Dissimi
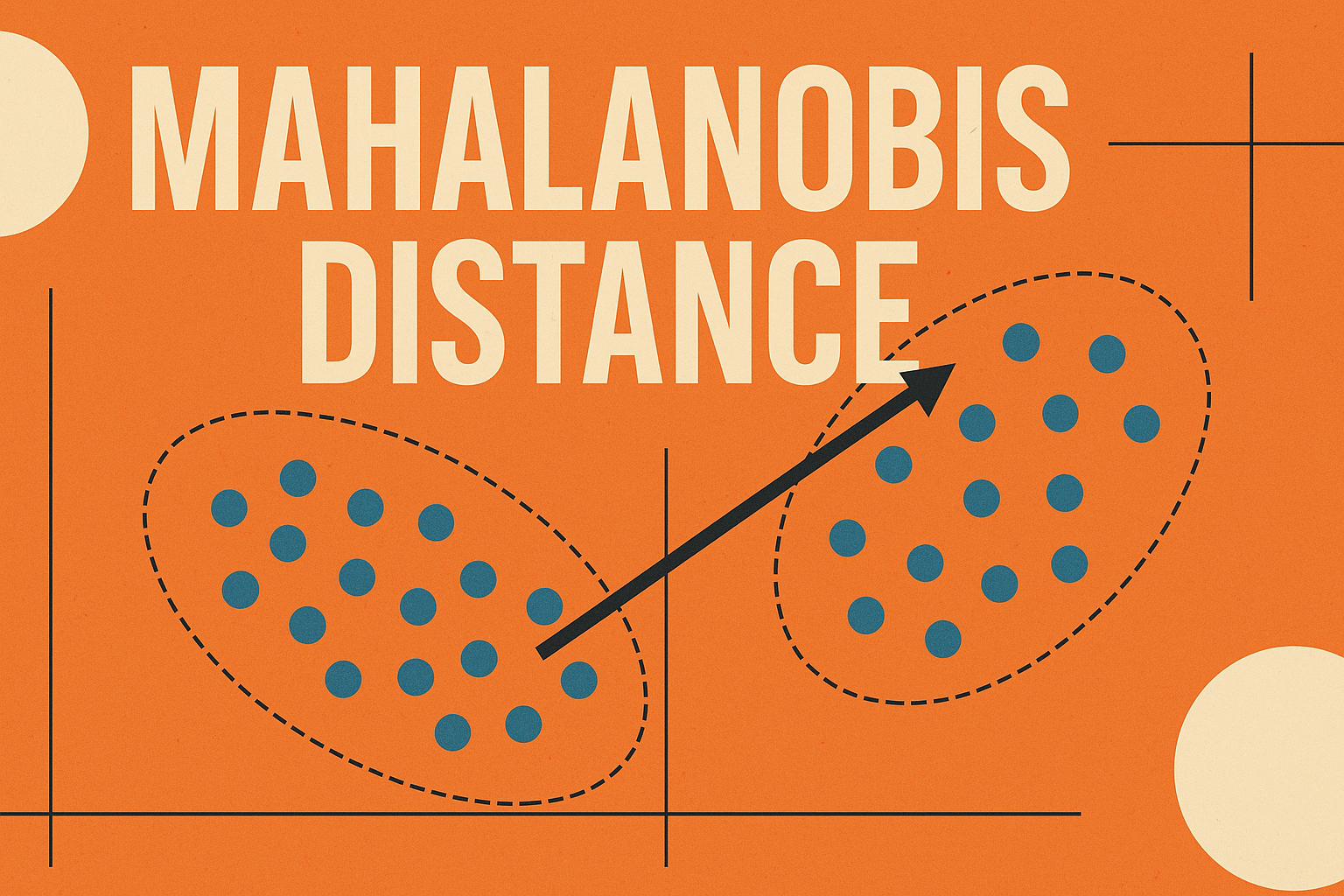
一、引言 在数据分析与机器学习中,“距离”是衡量样本之间相似度的核心概念。我们常见的欧氏距离(Euclidean Distance)与曼哈顿距离(Manhattan Distance),都基于坐标差值来计算样本间的空间距离。然而,它们都隐含着一个强假设——各个特征之间是相互独立的,并且在相同的度量尺
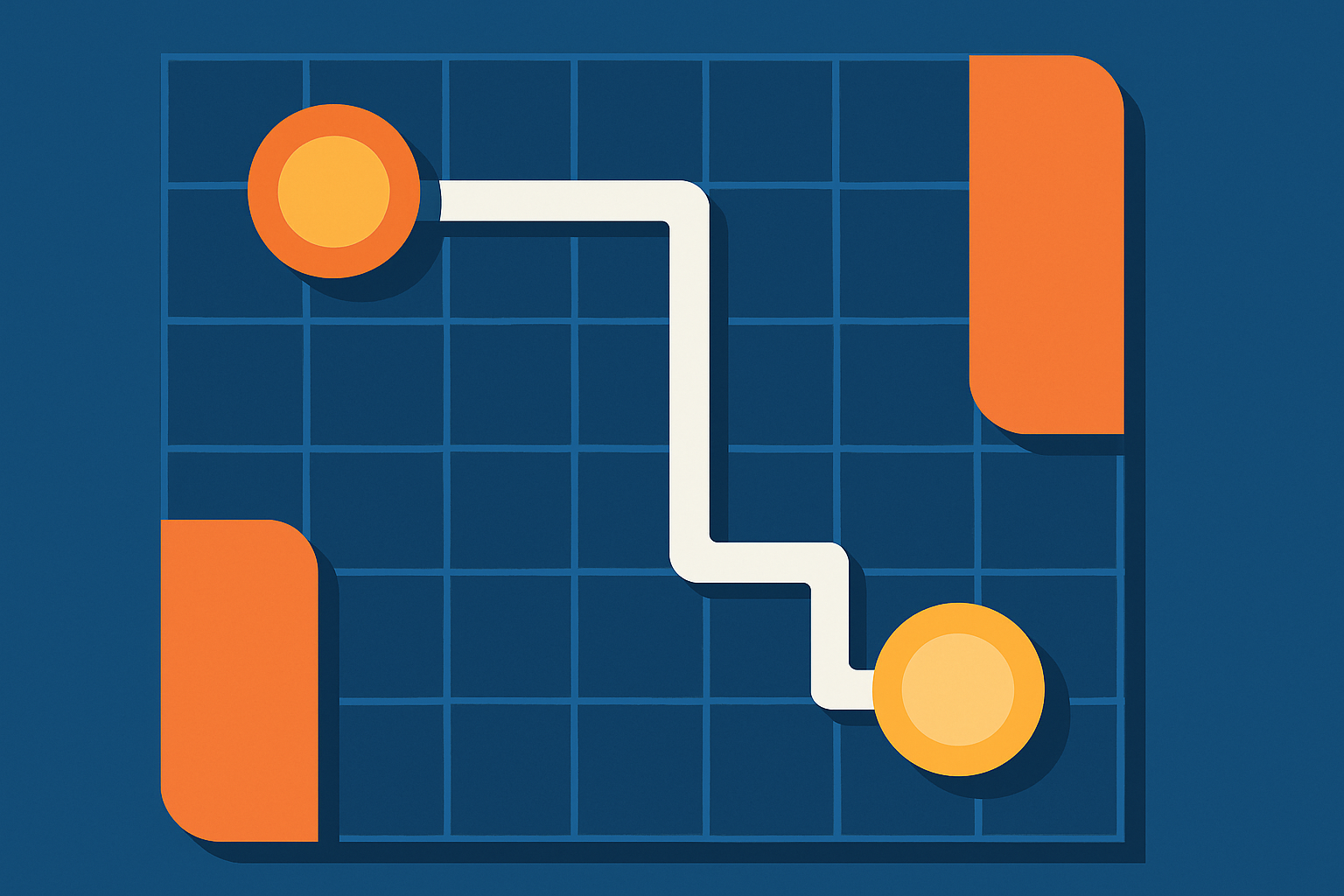
一、引言 在数据科学与机器学习的世界中,“距离”是一个极为核心的概念。无论是在聚类算法、相似度计算,还是在分类任务中,衡量两个样本之间的差异都离不开距离度量。而“Manhattan Distance(曼哈顿距离)”,便是其中最直观、最经典的一种。 曼哈顿距离(Manhattan Distance)又

一、引言 在数据分析和机器学习中,我们经常需要比较不同对象之间的相似性(similarity)。 对于数值型数据,可以使用欧氏距离(Euclidean Distance)或余弦相似度(Cosine Similarity)来衡量; 但当对象的属性仅由0和1组成时(即二元向量 Binary Vector

一、引言 在数据分析、机器学习和信息检索中,衡量“相似性”是一项基础而关键的任务。 不同的数据集、不同的特征空间,都需要一种合适的度量方式来判断对象之间的接近程度。最常见的做法是计算距离(Distance),例如欧氏距离或曼哈顿距离。然而,在许多实际场景中,我们更关心的是两个向量的方向是否一致

一、引言 在机器学习与数据挖掘中,“距离”是衡量两个对象相似度或差异性的重要指标。无论是在聚类(clustering)、最近邻搜索(nearest neighbor search)还是分类任务(classification)中,如何定义“距离”都会直接影响模型的效果。 最常见的距离度量是欧氏距离(E

一、欧式距离定义 欧氏距离(Euclidean Distance)是最常见、最直观的距离度量方法,用于衡量两个点在空间中的“直线距离”。 它可以理解为在 n 维空间中,连接两点的最短路径长度。 数学

一、Safari介绍 Safari 是苹果公司为 macOS、iOS 和 iPadOS 系统开发的默认网页浏览器,以其简洁的界面、出色的性能和强大的隐私保护著称。它支持快速加载网页、低能耗模式,并深度整合于苹果生态系统中,例如可通过 iCloud 同步书签、标签页和阅读列表,让用户在多设备间无缝切换

一、从全量到小批量——训练思路的转变

一、为什么需要探索 在强化学习的训练过程中,智能体需要不断地与环境交互, 通过观察状态、采取动作、获得奖励,逐渐学会什么是“好”的决策。 但这里有一个核心问题: 如果智能体总是选择当前看起来最优的动作,会怎样? 它可能会陷入局部最优—— 也就是说,它学到的策略在局部区域看起来很好, 但在整个任务范围
